







内容介绍:
K近邻算法(K-Nearest-Neighbor, KNN)是一种用于分类和回归的非参数统计方法,是机器学习最基础的算法之一。它正是基于以上思想:要确定一个样本的类别,可以计算它与所有训练样本的距离,然后找出和该样本最接近的k个样本,统计出这些样本的类别并进行投票,票数最多的那个类就是分类的结果。KNN的三个基本要素:
-
K值,一个样本的分类是由K个邻居的“多数表决”确定的。K值越小,容易受噪声影响,反之,会使类别之间的界限变得模糊。
-
距离度量,反映了特征空间中两个样本间的相似度,距离越小,越相似。常用的有Lp距离(p=2时,即为欧式距离)、曼哈顿距离、海明距离等。
-
分类决策规则,通常是多数表决,或者基于距离加权的多数表决(权值与距离成反比)。
具体内容:
1. 导包
from download import download
import os
import csv
import numpy as np
import matplotlib.pyplot as plt
import mindspore as ms
from mindspore import nn, ops
ms.set_context(device_target="CPU")2. 下载数据集
# 下载红酒数据集
url = "https://ascend-professional-construction-dataset.obs.cn-north-4.myhuaweicloud.com:443/MachineLearning/wine.zip"
path = download(url, "./", kind="zip", replace=True)3. 读取数据
with open('wine.data') as csv_file:
data = list(csv.reader(csv_file, delimiter=','))
print(data[56:62]+data[130:133])X = np.array([[float(x) for x in s[1:]] for s in data[:178]], np.float32)
Y = np.array([s[0] for s in data[:178]], np.int32)4. 可视化
attrs = ['Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols',
'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins', 'Color intensity', 'Hue',
'OD280/OD315 of diluted wines', 'Proline']
plt.figure(figsize=(10, 8))
for i in range(0, 4):
plt.subplot(2, 2, i+1)
a1, a2 = 2 * i, 2 * i + 1
plt.scatter(X[:59, a1], X[:59, a2], label='1')
plt.scatter(X[59:130, a1], X[59:130, a2], label='2')
plt.scatter(X[130:, a1], X[130:, a2], label='3')
plt.xlabel(attrs[a1])
plt.ylabel(attrs[a2])
plt.legend()
plt.show()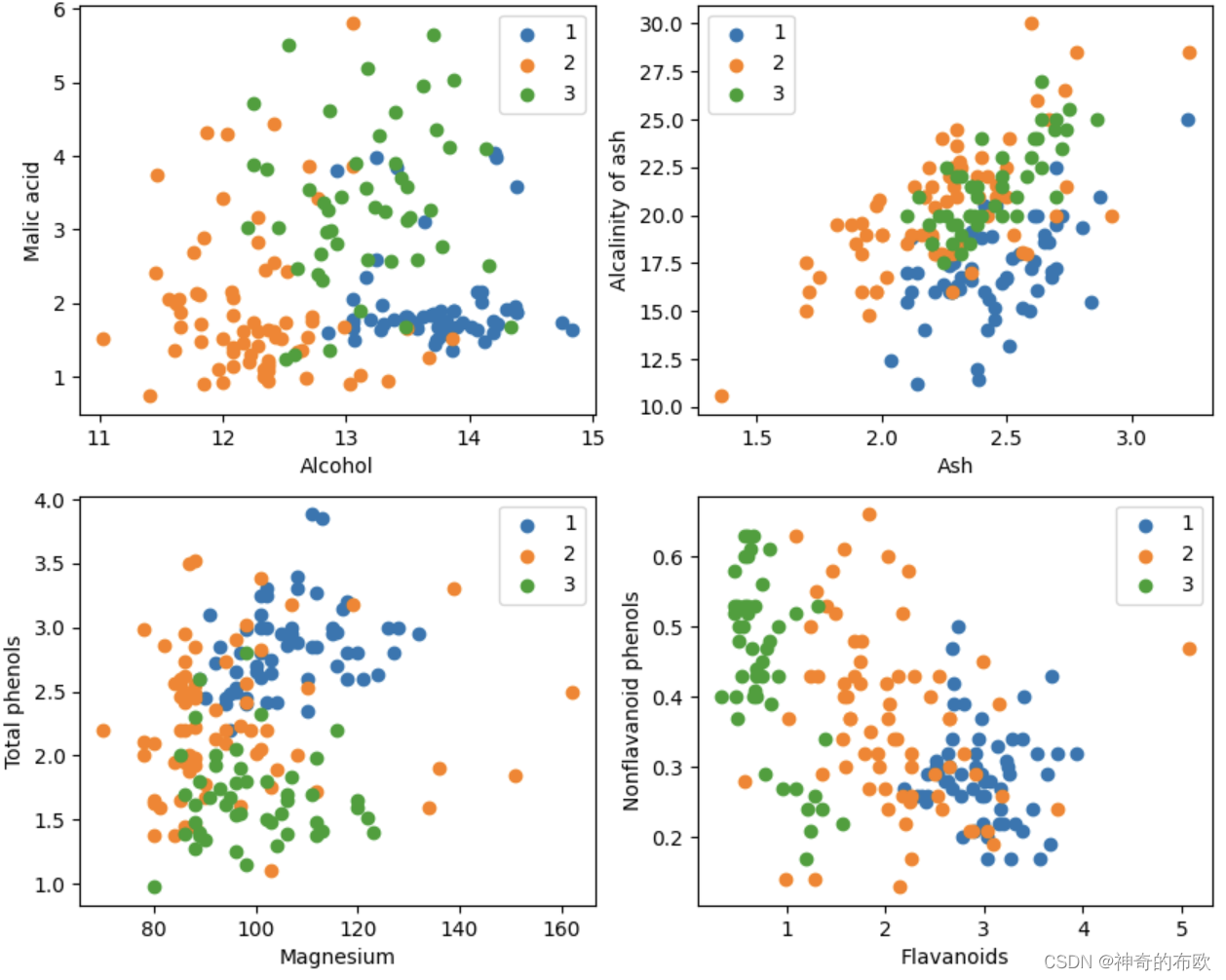
5. 数据集划分
train_idx = np.random.choice(178, 128, replace=False)
test_idx = np.array(list(set(range(178)) - set(train_idx)))
X_train, Y_train = X[train_idx], Y[train_idx]
X_test, Y_test = X[test_idx], Y[test_idx]6. 构建模型
class KnnNet(nn.Cell):
def __init__(self, k):
super(KnnNet, self).__init__()
self.k = k
def construct(self, x, X_train):
#平铺输入x以匹配X_train中的样本数
x_tile = ops.tile(x, (128, 1))
square_diff = ops.square(x_tile - X_train)
square_dist = ops.sum(square_diff, 1)
dist = ops.sqrt(square_dist)
#-dist表示值越大,样本就越接近
values, indices = ops.topk(-dist, self.k)
return indices
def knn(knn_net, x, X_train, Y_train):
x, X_train = ms.Tensor(x), ms.Tensor(X_train)
indices = knn_net(x, X_train)
topk_cls = [0]*len(indices.asnumpy())
for idx in indices.asnumpy():
topk_cls[Y_train[idx]] += 1
cls = np.argmax(topk_cls)
return cls7. 模型预测
acc = 0
knn_net = KnnNet(5)
for x, y in zip(X_test, Y_test):
pred = knn(knn_net, x, X_train, Y_train)
acc += (pred == y)
print('label: %d, prediction: %s' % (y, pred))
print('Validation accuracy is %f' % (acc/len(Y_test)))
KNN算法中的K值是一个关键的超参数,它决定了模型的复杂度和性能。在红酒数据上,不同的K值可能会产生截然不同的聚类或分类结果。通过交叉验证等方法选择最优的K值,可以使得模型更加准确和鲁棒。
虽然你提到的是使用KNN进行“聚类”,但实际上KNN是一种分类算法。在红酒数据的背景下,如果我们想要进行聚类分析,可能会选择其他算法(如K-means、层次聚类等)。然而,通过KNN分析红酒数据,你可以观察到数据中的自然分组和边界,这对于理解数据结构和选择更合适的聚类算法是有帮助的。

















 1026
1026











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











