









 本文详细介绍了VIT模型在计算机视觉领域的突破,Transformer的自注意力机制,以及Transformer架构的编码器-解码器设计。讨论了BERT和GPT的创新,以及深度学习中数据规模、模型简化和通用性的重要性。
本文详细介绍了VIT模型在计算机视觉领域的突破,Transformer的自注意力机制,以及Transformer架构的编码器-解码器设计。讨论了BERT和GPT的创新,以及深度学习中数据规模、模型简化和通用性的重要性。
阅读前必知:
1.加了背景的字都是重点
2.无水印的图可以到知乎中下载,csdn都是带水印的。
1. 论文地位:
VIT模型(Vision Transformer),这是一篇Google于2021年发表在计算机视觉顶级会议ICLR上的一篇文章。它首次将Transformer这种发源于NLP领域的模型引入到了CV领域,并在ImageNet数据集上击败了当时最先进的CNN网络。这是一个标志性的网络,代表transformer击败了CNN和RNN,同时在CV领域和NLP领域达到了统治地位,此后基本在ImageNet排行榜上都是基于transformer架构的模型了。
2.Transformer Encoder中的Self-Attention讲解
必须先把下面这几章认真看了,每一章都很重要:
上面6个部分也就是下面链接的1-6章:
狗都能看懂的Self-Attention讲解_a single-head self-attention-CSDN博客
3.transformer的架构及其原理
一、Transformer的架构及其详解:
主要由输入部分(输入输出嵌入与位置编码)、多层编码器、多层解码器以及输出部分(输出线性层与Softmax)四大部分组成。
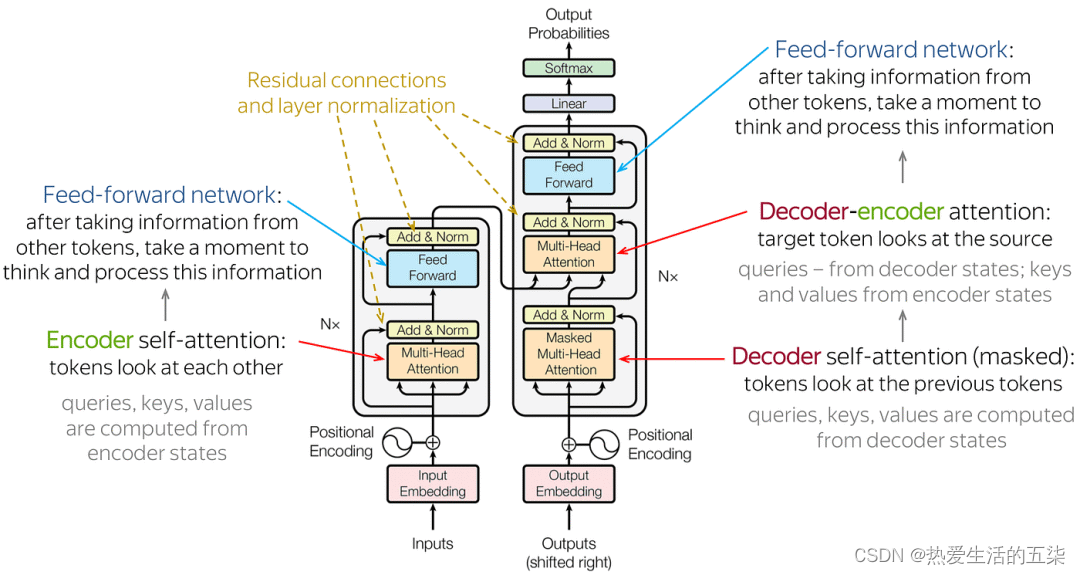
Transformer架构解释如下:(一定要理解清楚,下面内容很重要)(对上文图的细致解释)
- 输入部分:
- 源文本嵌入层:将源文本中的词汇数字表示转换为向量表示,捕捉词汇间的关系。
- 位置编码器:为输入序列的每个位置生成位置向量,以便模型能够理解序列中的位置信息。
- 目标文本嵌入层(在解码器中使用):将目标文本中的词汇数字表示转换为向量表示。
- 编码器部分:
- 由N个编码器层堆叠而成。transformer中N=6。
- 每个编码器层由两个子层连接结构组成:第一个子层是一个多头自注意力子层(这个是重点,见上文第二章Self-Attention讲解),第二个子层是一个前馈全连接子层。每个子层后都接有一个规范化层(Norm)和一个残差连接(add)。
- 解码器部分:
- 由N个解码器层堆叠而成。
- 每个解码器层由三个子层连接结构组成:第一个子层是一个带掩码的多头自注意力子层,第二个子层是一个多头注意力子层(编码器到解码器),第三个子层是一个前馈全连接子层。每个子层后都接有一个规范化层和一个残差连接。
- 输出部分:
- 线性层:将解码器输出的向量转换为最终的输出维度。
- Softmax层:将线性层的输出转换为概率分布,以便进行最终的预测。
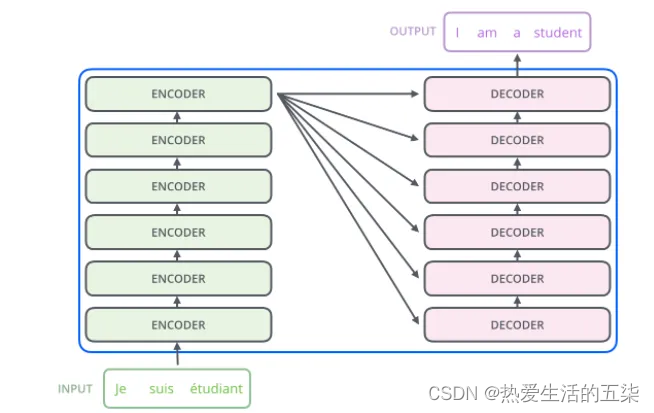
Encoder-Decoder(编码器-解码器):左边是N个编码器,右边是N个解码器,Transformer中的N为6。
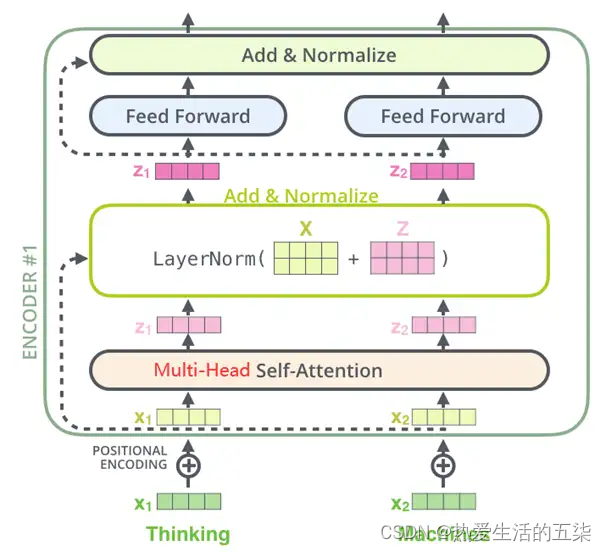
- Encoder编码器:
- Transformer中的编码器部分一共6个相同的编码器层组成。
每个编码器层都有两个子层,即多头自注意力层(Multi-Head Attention)层和逐位置的前馈神经网络(Position-wise Feed-Forward Network)。在每个子层后面都有残差连接(图中的虚线)和层归一化(LayerNorm)操作,二者合起来称为Add&Norm操作。
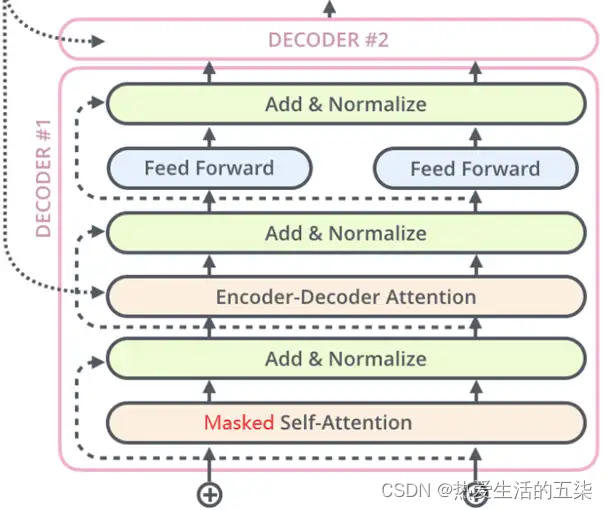
Decoder解码器:
- Decoder解码器:
- Transformer中的解码器部分同样一共6个相同的解码器层组成。
每个解码器层都有三个子层,掩蔽自注意力层(Masked Self-Attention)、Encoder-Decoder注意力层、逐位置的前馈神经网络。同样,在每个子层后面都有残差连接(图中的虚线)和层归一化(LayerNorm)操作,二者合起来称为Add&Norm操作。
二、Transformer的原理
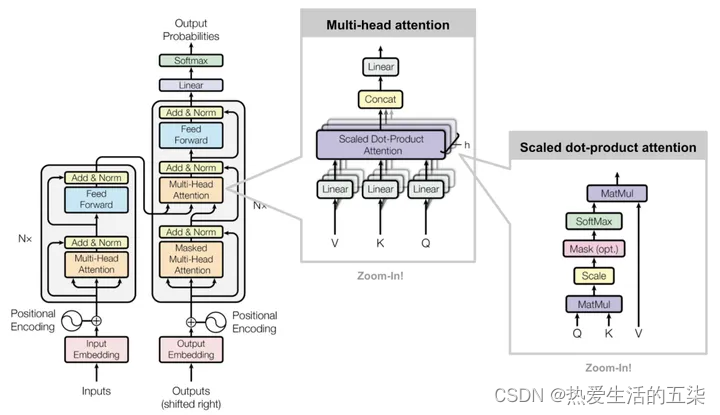
1. Multi-Head Attention(多头注意力):
它允许模型同时关注来自不同位置的信息。通过分割原始的输入向量到多个头(head),每个头都能独立地学习不同的注意力权重,从而增强模型对输入序列中不同部分的关注能力。
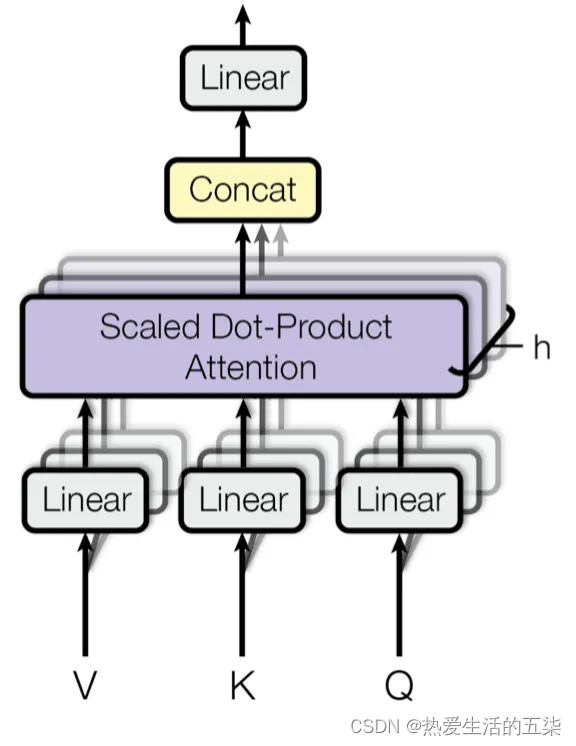
Multi-Head Attention(多头注意力)
是Encoder-Decoder注意力层中的关键一环)(本文第二章里面也有,看过的话可以再简单了解一下或者不看)
- 输入线性变换:对于输入的Query(查询)、Key(键)和Value(值)向量,首先通过线性变换将它们映射到不同的子空间。这些线性变换的参数是模型需要学习的。
- 分割多头:经过线性变换后,Query、Key和Value向量被分割成多个头。每个头都会独立地进行注意力计算。
- 缩放点积注意力:在每个头内部,使用缩放点积注意力来计算Query和Key之间的注意力分数。这个分数决定了在生成输出时,模型应该关注Value向量的部分。
- 注意力权重应用:将计算出的注意力权重应用于Value向量,得到加权的中间输出。这个过程可以理解为根据注意力权重对输入信息进行筛选和聚焦。
- 拼接和线性变换:将所有头的加权输出拼接(concat)在一起,然后通过一个线性变换(linear)得到最终的Multi-Head Attention输出。
2. Scaled Dot-Product Attention(缩放点积注意力):
它是Transformer模型中Multi-Head Attention(多头注意力机制)的一个关键组成部分。(本文第二章里面也有,看过的话可以再简单了解一下或者不看)
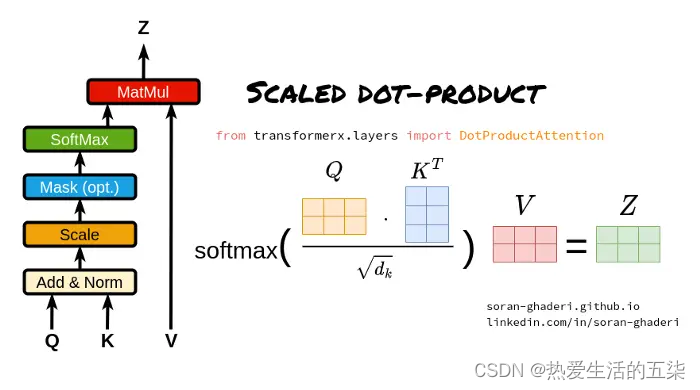
Scaled Dot-Product Attention(缩放点积注意力)(本文第二章里面也有,看过的话可以再简单了解一下或者不看)
- Query、Key和Value矩阵:
- Query矩阵(Q):表示当前的关注点或信息需求,用于与Key矩阵进行匹配。
- Key矩阵(K):包含输入序列中各个位置的标识信息,用于被Query矩阵查询匹配。
- Value矩阵(V):存储了与Key矩阵相对应的实际值或信息内容,当Query与某个Key匹配时,相应的Value将被用来计算输出。
- 点积计算:
- 通过计算Query矩阵和Key矩阵之间的点积(即对应元素相乘后求和),来衡量Query与每个Key之间的相似度或匹配程度。
- 缩放因子:
- 由于点积操作的结果可能非常大,尤其是在输入维度较高的情况下,这可能导致softmax函数在计算注意力权重时进入饱和区。为了避免这个问题,缩放点积注意力引入了一个缩放因子,通常是输入维度的平方根。点积结果除以这个缩放因子,可以使得softmax函数的输入保持在一个合理的范围内。
- Softmax函数:
- 将缩放后的点积结果输入到softmax函数中,计算每个Key相对于Query的注意力权重。Softmax函数将原始得分转换为概率分布,使得所有Key的注意力权重之和为1。
- 加权求和:
- 使用计算出的注意力权重对Value矩阵进行加权求和,得到最终的输出。这个过程根据注意力权重的大小,将更多的关注放在与Query更匹配的Value上。
4.BERT(Transformer架构改进):
- BERT是一种基于Transformer的预训练语言模型,它的最大创新之处在于引入了双向Transformer编码器,这使得模型可以同时考虑输入序列的前后上下文信息。
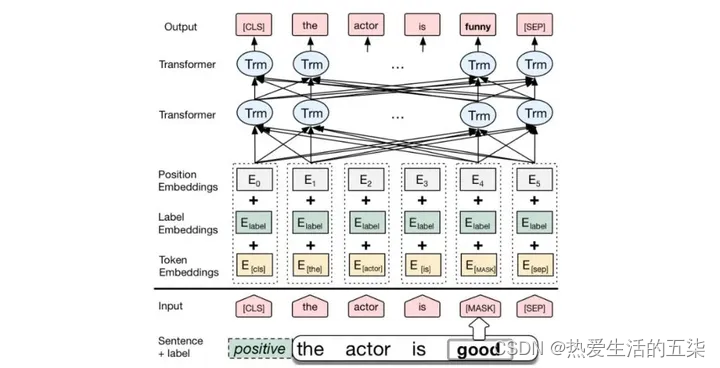
BERT架构如下
1.输入层(Embedding层):
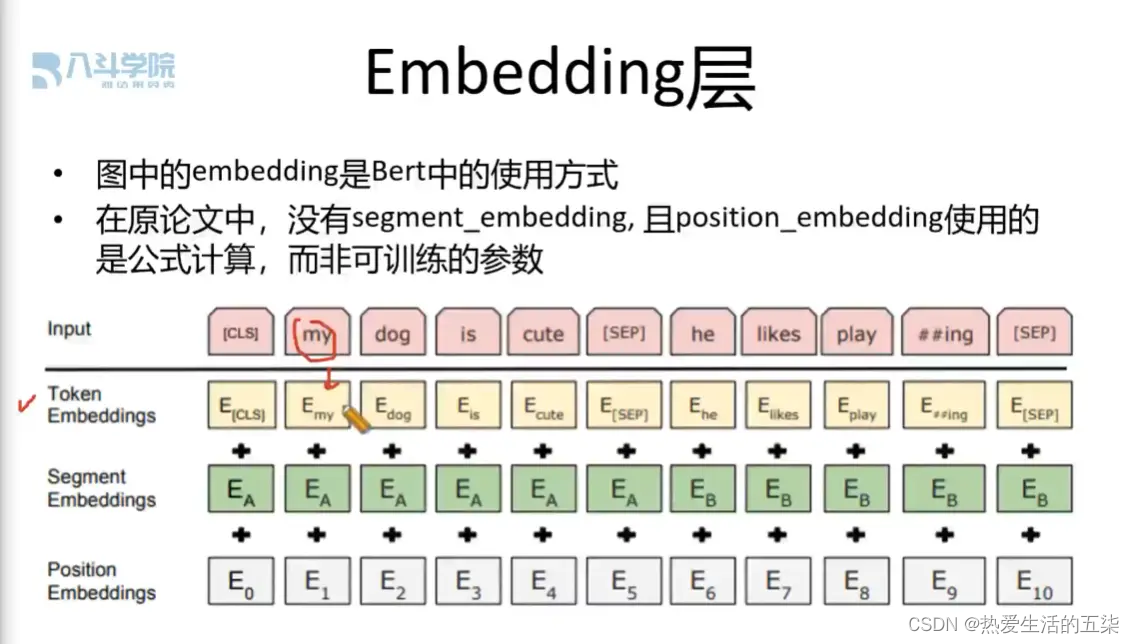
"Embeddings" 指的是将这些基本单元映射到一个连续的向量空间中的过程,这样每个基本单元都会对应一个向量,称为嵌入向量,它可以捕捉基本单元的语义和语法信息。(把离散字符转化为数字,相当于将非数字变成数字的过程)
-
token embeddings(令牌嵌入层,分词嵌入):用于区分文本内容,1个文本字符对应768维的向量,1个token embeddings输出N(字符数)x 768维的矩阵
-
segment embeddings(段落嵌入层):用于区分哪一句话,输出也是N x 768维的矩阵,同一句对应的向量是相同的
-
position embeddings(位置嵌入层):用于确定文本位置,输出也是N x 768维的矩阵
因此得到3个N x 768矩阵,3个矩阵相加,输出一个新的N x 768的矩阵
2.编码层(Transformer Encoder):BERT模型使用双向Transformer编码器进行编码。
3.输出层(Pre-trained Task-specific Layers):
- MLM输出层:用于预测被掩码(masked)的单词。在训练阶段,模型会随机遮盖输入序列中的部分单词,并尝试根据上下文预测这些单词。
- NSP输出层:用于判断两个句子是否为连续的句子对。在训练阶段,模型会接收成对的句子作为输入,并尝试预测第二个句子是否是第一个句子的后续句子。
5.GPT
GPT也是一种基于Transformer的预训练语言模型,它的最大创新之处在于使用了单向Transformer编码器,这使得模型可以更好地捕捉输入序列的上下文信息。
tips:GPT采用的是单向的Transformer,而BERT采用的是双向的Transformer
5.PyTorch代码实现Transformer并详细解读代码
可以看看下面连接的代码部分,加深印象,最好看一下
搞懂Transformer结构,看这篇PyTorch实现就够了(上) - 知乎
6.总结
总结上面这些关于Transformer工作的发展中,我也整理出了一些关于深度学习发展趋势的个人心得:
1. 有监督模型向半监督甚至无监督方向发展
数据的规模的增长速度远远超过了数据的标注速度,这也就导致了大量无标签数据的产生。这些无标签的数据并非没有价值,相反,如果找到合适的“炼金术”,将可以从这些海量的数据中获取意想不到的价值。如何利用上这些无标签的数据来改善任务的表现变成了一个越来越无法轻视的问题。
2. 从少量数据复杂模型到大量数据简单模型
深度神经网络的拟合能力非常的强大,一个简单的神经网络模型就足以拟合任何函数。但无奈使用越简单的网络结构完成同一个任务,对数据量的要求也更高。数据量越是上升,数据质量越是提高,往往对模型的要求就会越会降低。数据量越大,模型就越容易捕捉到符合真实世界分布的特征。Word2Vec就是一个例子,它所使用的目标函数非常的简单,但是由于使用了大量的文本,于是训练出的词向量中就包含了许多有趣的特性。
3. 从专用模型向通用模型发展
GPT、BERT、MT-DNN、GPT-2都使用了经过预训练的通用模型来继续进行下游的机器学习任务,并不需要对模型本身再做太多的修改。如果一个模型的表达能力足够的强,训练时候使用的数据量足够的大,那么模型的通用性就会更强,就不需要针对特定的任务做太多的修改。最极端的情况就像是GPT-2这个样子,训练时甚至完全不需要知道后续的下游任务是什么,就能够训练出一个通用的多任务模型。
4. 对数据的规模和质量要求提高
GPT、BERT、MT-DNN、GPT-2虽然先后刷榜,但是我认为成绩的提升中,数据规模的提升占有比结构调整更大的比重。随着模型的通用化和简单化,为提升模型的性能,今后更多的注意力将会从如何设计一个复杂、专用的模型转移到如何获取、清洗、精化出质量更加出众的、大量的数据上。数据的处理方式调整的作用将会大于模型结构调整的作用。
参考链接:
本文第1,2章参考链接:狗都能看懂的Self-Attention讲解_a single-head self-attention-CSDN博客
本文第3,4章参考链接:一文搞懂Transformer,讲解神经网络算法 最好的一篇文章! - 知乎
















 957
957











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











