






开头
最近,因为自己的模型用到了交叉注意力机制,想对注意力的部分做关注区域的可视化工作,如下图所示。在网上搜索了解到grad_cam可以做热力图可视化,所以把grad_cam引入到自己的模型中,对交叉注意力的部分做热力图的可视化,在用的过程中遇到了各种各样的bug,在这里总结记录下来,供自己以后回顾,也供大家参考借鉴。

关于grad_cam的使用介绍,可以看B站UP主@Larry同学的视频
【深度学习中,模型可视化,特征图的可视化,CAM热力图可视化】
了解基本的使用方法,视频中的代码在原视频下方评论区可以找到百度网盘链接,本文是参照的该代码在自己的模型上进行迁移使用。
问题一:grad_cam的input tensor输入多个的问题
在迁移到我自己的模型的时,遇到的第一个问题,就是如何输入多个input tensor的问题。
网上的使用示例方法,在用pytorch_grad_cam.GradCAMPlusPlus实例化之后使用的时候,输入的是一张图片的信息(一般是RGB),也就是一个tensor,但我自己的模型是需要输入多张图片(RGB,频域,区域纹理)的信息,也就是多个tensor的。1-3 是我的解决该问题的思路分析过程,只想看最终解决方法的可以跳过 1 和 2,直接看 3 。
1. 把多个tensor直接传入进去
如果把3个tensor直接传入进去,像下面这样:
cam = pytorch_grad_cam.GradCAMPlusPlus(model=model, target_layers=target_layer)
# images_b是区域纹理图,images_f是频域图,images是RGB图
grayscale_cam = cam(images_b, images_f, images)
运行的时候会报错:
TypeError: forward() missing 2 required positional arguments: 'x_f' and 'x_p'
就是只有第一个tensor传过去了,但是后面两个tensor没有传过去,查看GradCAMPlusPlus继承的BaseCAM源码,其中的forward函数如下:
def forward(
self, input_tensor: torch.Tensor, targets: List[torch.nn.Module], eigen_smooth: bool = False
) -> np.ndarray:
input_tensor = input_tensor.to(self.device)
说明其中的input_tensor只接收了第1个images变量,后面2个变量没有接收,而我自己的模型的forward部分是需要3个tensor输入的:
def forward(self, x_b, x_f, x_p): # x_b为区域纹理图,x_f为频域图,x_p为RGB图
因此会报上面的错。
2. 使用tuple将多个tensor打包传入
于是,我考虑是否可以将3个tensor组成一个tuple传入进去(因为之前用tensorboard可视化网络结构传参的时候可以采用这种方式),让input_tensor可以接收到tuple,从而可以得到3个tensor,于是修改代码如下:
cam = pytorch_grad_cam.GradCAMPlusPlus(model=model, target_layers=target_layer)
# images_b是区域纹理图,images_f是频域图,images是RGB图
grayscale_cam = cam((images_b, images_f, images)) # 把3个tensor组成tuple传入
然后还是报错:
AttributeError: 'tuple' object has no attribute 'to'
意思是tuple没有to的属性,这个to属性是哪里来的呢?还是看上面提到的GradCAMPlusPlus继承的BaseCAM源码,其中的forward函数:
def forward(
self, input_tensor: torch.Tensor, targets: List[torch.nn.Module], eigen_smooth: bool = False
) -> np.ndarray:
input_tensor = input_tensor.to(self.device)
会发现里面有一个input_tensor.to(self.device)的操作,就是它需要把input_tensor传到当前所在的设备上(CPU或者GPU),而这个操作是tensor才有的,它接受到是tuple,所以就报这个错了。而且,再仔细看上面的参数说明的话,input_tensor: torch.Tensor,是需要传入的参数是tensor类型(并且只能是一个tensor,不能接收多个),基于此,我想到了最后的解决办法。
3. ⭐多个tensor使用concat组成一个tensor
如标题所示,我想到的最后的解决办法,就是把多个tensor使用concat组成一个tensor,这样子就能满足grad_cam的使用要求了(类型为tensor,且只有一个),具体需要修改代码的地方是两个:一个是grad_cam传入的地方,还有一个就是我自己模型的forward函数。
(1) gard_cam:
修改的代码如下:
# dim=1是在通道维度进行concat,.cuda()是把concat后的tensor放到GPU上
images_all = torch.cat((images_b, images_f, images), dim=1).cuda()
cam = pytorch_grad_cam.GradCAMPlusPlus(model=model, target_layers=target_layer)
grayscale_cam = cam(images_all)
(2) 自己模型forward函数:
def forward(self, x): # 接收的参数变成1个
x_b = x[:, :3, :, :] # 取x的第1-3个通道
x_f = x[:, 3:6, :, :] # 取x的第4-6个通道
x_p = x[:, -3:, :, :] # 取x的最后3个通道
可能重新取concat前的tensor时会有通道数不都是3的情况,可以根据自己的情况进行相应的修改,不过思路都是一样的,就是把多个tensor使用concat组合到一起,然后在模型里面的时候再还原成原来的多个tensor,这样子就解决了grad_cam需要传入的是tensor类型且数量只能为1个的问题。
至此,我遇到的第一个问题终于解决了!😭
因为这种方法需要改动自己原来的模型代码,做完热力图的可视化之后需要对自己原理的模型代码还原,不过这个方法的思路比较简单粗暴好理解,让我没有继续被这个Bug卡住了。。。
想用其他解决方案的小伙伴可以看一下下面的可能的其他解决思路链接
P.S:可能的其他解决思路
1. 我在找解决方法的时候在gard_cam源码Github仓库的issue部分,有看到一个老哥提供的解决方案,也是我的解决方案的灵感启发,不过我没有细看他的解决方法,直接用自己的思路解决了,有感兴趣的小伙伴也可以看一下这个链接:https://github.com/jacobgil/pytorch-grad-cam/issues/279#issuecomment-1221199929
2. 还有一个grad_cam代码作者自己在issue中给出的一个解决方法,我尝试的时候没有成功,也可能是我没有看懂,感兴趣的小伙伴也可以看一下这个链接:https://github.com/jacobgil/pytorch-grad-cam/issues/406#issuecomment-1500393283
🌟一些碎碎念:
在我找关于grad_cam可视化的bug的过程中,发现搜索不到太多中文的回答(搜到的很多都是关于grad_cam的论文解读,不是使用时的bug,也可能是我搜索的方式不太对。。。)后面才想到去grad_cam源码仓库的issue部分对报错和问题进行搜索的,所以大家在使用grad_cam还有遇到别的bug的话,可以去仓库的issue部分搜一下,我写这篇博客也是想填补一下这方面中文回答的一点空白,或者说是提供一个这样的引子吧,希望能对大家有所帮助,有写的不对的地方也欢迎批评指正~🤗
问题二:使用show_cam_on_image的时候报错cv::ColorMap only supports source images of type CV_8UC1 or CV_8UC3 in function ‘operator()’
1.详细问题描述
使用pytorch_grad_cam.GradCAMPlusPlus得到grayscale_cam之后,下一步使用show_cam_on_image将得到的grayscale_cam在src_img(原图)上使用进行叠加,以可视化网络对图片不同位置的关注程度,也就是下面这句代码:
visualization_img = show_cam_on_image(src_img, grayscale_cam, use_rgb=False)
但是在运行这一句代码的时候报错:cv2.error: OpenCV(4.9.0) /io/opencv/modules/imgproc/src/colormap.cpp:736: error: (-5:Bad argument) cv::ColorMap only supports source images of type CV_8UC1 or CV_8UC3 in function 'operator()'
报错处的代码是库函数show_cam_on_image中的第一句代码:heatmap = cv2.applyColorMap(np.uint8(255 * mask), colormap)
def show_cam_on_image(img: np.ndarray,
mask: np.ndarray,
use_rgb: bool = False,
colormap: int = cv2.COLORMAP_JET,
image_weight: float = 0.5) -> np.ndarray:
heatmap = cv2.applyColorMap(np.uint8(255 * mask), colormap) # 报错所在代码
这个报错的意思是:在调用 OpenCV 的 applyColorMap 函数时,传入的源图像类型不正确。applyColorMap 只支持类型为 CV_8UC1(单通道 8 位无符号整数)或 CV_8UC3(三通道 8 位无符号整数)的图像。
2.问题分析过程
由于grayscale_cam是由pytorch_grad_cam.GradCAMPlusPlus得到的,前面的没有报错的话,grayscale_cam应该是没有问题的,因此,关键需要检查src_img是否符合show_cam_on_image函数的输入要求。在我自己的show_cam_on_image所在的代码行加上断点,运行查看src_img的信息如下:
| name | type | shape | value |
|---|---|---|---|
| src_img | torch.Tensor | [6, 64, 64, 3] | tensor([[[[-0.49105233, 0.90546227, 2.5005665 ], [-0.49105233, 0.90546227, 2.4831376 ], [-0.49105233, 0.90546227, 2.4831376 ], …, [-0.33692956, 1.0280112 , 2.5005665 ], [-0.31980482, 1.0280112 , 2.5005665 ], [-0.33692956, 1.0280112 , 2.5005665 ]], …, [-0.49105233, 0.88795525, 2.4831376 ], [-0.49105233, 0.88795525, 2.4831376 ], [-0.49105233, 0.90546227, 2.4831376 ]]], …, ) |
可以看到,我的src_img有负值的数据,是有符号数,不符合8位无符号数的要求,因此会报上面的错。
于是将自己代码对src_img图像处理的过程与示例代码对图像处理的过程进行对比,下面是示例代码的处理过程:
origin_img = cv2.imread('/path/to/img.png')
rgb_img = cv2.cvtColor(origin_img, cv2.COLOR_BGR2RGB)
trans = transforms.Compose([
transforms.ToTensor(),
transforms.Resize(224),
transforms.CenterCrop(224)
])
crop_img = trans(rgb_img)
net_input = transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))(crop_img).unsqueeze(0)
canvas_img = (crop_img * 255).byte().numpy().transpose(1, 2, 0)
canvas_img = cv2.cvtColor(canvas_img, cv2.COLOR_RGB2BGR)
cam = pytorch_grad_cam.GradCAMPlusPlus(model=resnet18, target_layers=target_layers)
grayscale_cam = cam(net_input)
grayscale_cam = grayscale_cam[0, :]
src_img = np.float32(canvas_img) / 255
visualization_img = show_cam_on_image(src_img, grayscale_cam, use_rgb=False)
示例代码的图像完整变化过程的详细信息如下表:
| name | operation | type | shape | value |
|---|---|---|---|---|
| origin_img | cv2.imread | numpy.ndarray | (1626, 1626, 3) | array([[[ B85, G130, R164], [ 85, 130, 164], [ 85, 130, 164], …, [150, 158, 195], [149, 157, 194], [149, 157, 194]], …, [150, 158, 195], [149, 157, 194], [149, 157, 194]]], dtype=uint8) |
| rgb_img | cv2.COLOR_BGR2RGB | numpy.ndarray | (1626, 1626, 3) | array([[[R164, G130, B85], [164, 130, 85], [164, 130, 85], …, [195, 158, 150], [194, 157, 149], [194, 157, 149]], …, [195, 158, 150], [194, 157, 149], [194, 157, 149]]], dtype=uint8) |
| crop_img | transforms.ToTensor(), transforms.Resize(224), transforms.CenterCrop(224) | torch.Tensor | [3, 224, 224] |  |
| net_input | transforms.Normalize ((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)) (crop_img).unsqueeze(0) | torch.Tensor | [1, 3, 224, 224] |  |
| canvas_img | (crop_img * 255).byte(). numpy().transpose(1, 2, 0) | numpy.ndarray | (224, 224, 3) | array([[[R164, G130, B85], [164, 130, 85], [163, 129, 84], …, [[209, 174, 168], [210, 175, 169], [208, 171, 165], …, [194, 157, 149], [196, 159, 151], [197, 160, 152]]], dtype=uint8) |
| canvas_img | cv2.COLOR_RGB2BGR | numpy.ndarray | (224, 224, 3) | array([[[B85, G130, R164], [ 85, 130, 164], [ 84, 129, 163], …, [[168, 174, 209], [169, 175, 210], [165, 171, 208], …, [149, 157, 194], [151, 159, 196], [152, 160, 197]]], dtype=uint8) |
| grayscale_cam | cam(net_input) | numpy.ndarray | (1, 224, 224) |  |
| grayscale_cam | grayscale_cam[0, :] | numpy.ndarray | (224, 224) | 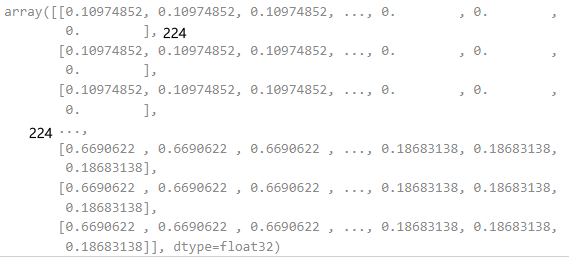 |
| src_img | np.float32(canvas_img) / 255 | numpy.ndarray | (224, 224, 3) | array([[[B0.33333334, G0.50980395, R0.6431373 ], [0.33333334, 0.50980395, 0.6431373 ], [0.32941177, 0.5058824 , 0.6392157 ], …, [0.5882353 , 0.61960787, 0.7647059 ], [0.5921569 , 0.62352943, 0.76862746], [0.6 , 0.63529414, 0.76862746]], [[0.65882355, 0.68235296, 0.81960785], [0.6627451 , 0.6862745 , 0.8235294 ], [0.64705884, 0.67058825, 0.8156863 ], …, [0.58431375, 0.6156863 , 0.7607843 ], [0.5921569 , 0.62352943, 0.76862746], [0.59607846, 0.627451 , 0.77254903]]], dtype=float32) |
| visualization_img | show_cam_on_image(src_img, grayscale_cam, use_rgb=False) | numpy.ndarray | (224, 224, 3) | array([[[B160, G65, R82], [160, 65, 82], [160, 64, 81], …, [[ 84, 193, 232], [ 84, 193, 232], [ 82, 191, 231], …, [202, 108, 97], [203, 109, 98], [203, 110, 98]]], dtype=uint8) |
可以看到,scr_img其变化过程如下:origin_img→rgb_img→crop_img→canvas_img→src_img,且其是类型为numpy.ndarray,尺寸为(W,H,C),范围为[0,1]的数据。
经过与我自己的代码的图像变化过程对比发现其中很关键的是transforms.Normalize((0.485, 0.456, 0.406),(0.229, 0.224, 0.225))这个操作,这一操作是在生成grayscale_cam时对输入的net_input需要做的操作,而在生成src_img过程中是不需要进行的。该操作是标准化图像张量,目的是将图像数据的像素值调整到一个特定的范围,以便更好地适应机器学习模型的训练和推理,其中的数值是通过计算 ImageNet 数据集中所有图像的每个通道的像素值的平均值和标准差得到的,而这个操作有可能让图像的数据产生负值。
我的代码中,因为在图像的预处理中,已经使用了该操作,导致我的图像数据已经产生了负值,而我直接将预处理之后的图片当成了src_img传入了show_cam_on_image函数中,故产生了上述错误。
3.问题解决方法
因此,总结起来,解决的方法就是,检查自己代码show_cam_on_image函数src_img对应的输入图像的变化过程,注意不要对其有transforms.Normalize((0.485, 0.456, 0.406),(0.229, 0.224, 0.225))操作,确保其变化过程与origin_img→rgb_img→crop_img→canvas_img→src_img的变化过程一致,详细的变化过程信息见下表。
| name | operation | type | shape | value |
|---|---|---|---|---|
| origin_img | cv2.imread | numpy.ndarray | (1626, 1626, 3) | array([[[ B85, G130, R164], [ 85, 130, 164], [ 85, 130, 164], …, [150, 158, 195], [149, 157, 194], [149, 157, 194]], …, [150, 158, 195], [149, 157, 194], [149, 157, 194]]], dtype=uint8) |
| rgb_img | cv2.COLOR_BGR2RGB | numpy.ndarray | (1626, 1626, 3) | array([[[R164, G130, B85], [164, 130, 85], [164, 130, 85], …, [195, 158, 150], [194, 157, 149], [194, 157, 149]], …, [195, 158, 150], [194, 157, 149], [194, 157, 149]]], dtype=uint8) |
| crop_img | transforms.ToTensor(), transforms.Resize(224), transforms.CenterCrop(224) | torch.Tensor | [3, 224, 224] |  |
| canvas_img | (crop_img * 255).byte(). numpy().transpose(1, 2, 0) | numpy.ndarray | (224, 224, 3) | array([[[R164, G130, B85], [164, 130, 85], [163, 129, 84], …, [[209, 174, 168], [210, 175, 169], [208, 171, 165], …, [194, 157, 149], [196, 159, 151], [197, 160, 152]]], dtype=uint8) |
| canvas_img | cv2.COLOR_RGB2BGR | numpy.ndarray | (224, 224, 3) | array([[[B85, G130, R164], [ 85, 130, 164], [ 84, 129, 163], …, [[168, 174, 209], [169, 175, 210], [165, 171, 208], …, [149, 157, 194], [151, 159, 196], [152, 160, 197]]], dtype=uint8) |
| src_img | np.float32(canvas_img) / 255 | numpy.ndarray | (224, 224, 3) | array([[[B0.33333334, G0.50980395, R0.6431373 ], [0.33333334, 0.50980395, 0.6431373 ], [0.32941177, 0.5058824 , 0.6392157 ], …, [0.5882353 , 0.61960787, 0.7647059 ], [0.5921569 , 0.62352943, 0.76862746], [0.6 , 0.63529414, 0.76862746]], [[0.65882355, 0.68235296, 0.81960785], [0.6627451 , 0.6862745 , 0.8235294 ], [0.64705884, 0.67058825, 0.8156863 ], …, [0.58431375, 0.6156863 , 0.7607843 ], [0.5921569 , 0.62352943, 0.76862746], [0.59607846, 0.627451 , 0.77254903]]], dtype=float32) |
同时,需要注意的是,show_cam_on_image函数src_img是单张图片,如果是想一次处理多张图片(比如我自己的代码就是一次处理的6张图片,因此在2.问题分析过程部分时src_img的tensor的维度是4,其中第一个维度就是我图像的batch_size为6),可以使用如下的for循环:
src_img = np.float32(canvas_img) / 255
cam_img = []
for i in range(src_img.shape[0]):
cam_img.append(show_cam_on_image(src_img[i], grayscale_cam[i], use_rgb=False))
cam_img = np.stack(cam_img)
至此,终于解决了我遇到的第二个问题🎉。
结尾
以上就是我在使用grad_cam对自己的模型进行可视化的过程中遇到的一些问题了,其实还有一些小的其他问题,没有总结写出来,反正,这个过程真的还蛮不顺利的😭,不过最后总算是弄出来了,看到在自己的模型代码中跑出来了自己要的效果图的时候,那一刻是真的很开心了😊~
也许这就是程序员改bug的幸福所在吧,经历风雨🌧️之后的彩虹🌈,才显得更美丽~
哈哈哈,改个bug也能写出这样一句感悟,我也是有点好笑,嘻嘻嘻😁~(不太聪明的样子)

















 4854
4854

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









