







1. 定义
根据一组包含异常数据的数据集,计算出能正确描述数据集中的正确数据的数学模型的参数
是从一组含有“外点”(outliers)的数据中正确估计数学模型参数的迭代算法。
“外点”一般指的的数据中的噪声,比如说匹配中的误匹配和估计曲线中的离群点。
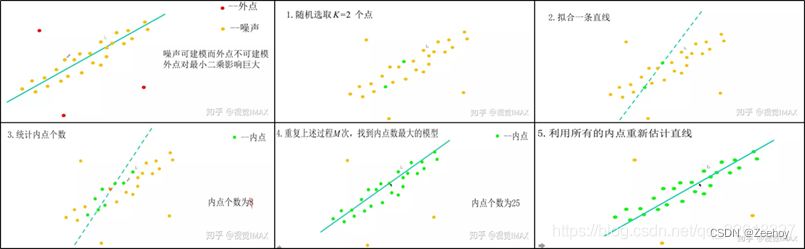
2.流程
RANSAC是通过反复随机从数据集中挑选数据,去计算出模型,一直迭代到出现认为比较好的模型为止
具体的实现步骤可以分为以下几步:
- 选择出可以估计出模型的最小数据集
- 使用这个最小数据集来计算出模型的参数
- 将所有数据代入这个模型,根据误差阈值判断数据是否是“内点”,统计出“内点”的数目
- 比较当前模型和之前推出的最好的模型的“内点“的数量,记录最大“内点”数的模型参数和“内点”数
- 重复以上步骤,直到达到最大迭代次数或者内点数目大于一定数量(内点所占总数据的比例大于一定比例),即当前模型已经足够好了,迭代结束
3.迭代次数推导
迭代的次数是可以估算出来的
假设“内点”在数据中的占比为 t:
t
=
n
i
n
l
i
e
r
s
n
i
n
l
i
e
r
s
+
n
o
u
t
l
i
e
r
s
t=\frac{n_{inliers}}{n_{inliers}+n_{outliers}}
t=ninliers+noutliersninliers
求解数学模型需要的最少的点的个数为N(如求解直线方程的参数,需要两个点;求解平面的参数需要三个点)
那么每次迭代,从数据集中随机挑选N个点,这N个点都是内点(都是正确数据)的概率:
t
N
t^N
tN
则选取的N个点,至少有一个外点(至少有一个选错了,选到异常数据;此次迭代失败)的概率:
1
−
t
N
1-t^N
1−tN
假设迭代K次,这K次迭代中,每次都失败的概率:
(
1
−
t
N
)
K
(1-t^N)^K
(1−tN)K
由于最终记录下来的模型的参数是这K次迭代中,最好的模型的参数,也就是说,只要这K次迭代中,有一次是正确的就可以了
这K次迭代中,至少有一次是成功的(所挑选的N个点全是正确数据)的概率:
P
=
1
−
(
1
−
t
N
)
K
P=1-(1-t^N)^K
P=1−(1−tN)K
通过上式,可以求得迭代次数K:
1
−
P
=
(
1
−
t
N
)
K
1-P=(1-t^N)^K
1−P=(1−tN)K
l
o
g
(
1
−
P
)
=
l
o
g
(
1
−
t
N
)
K
log(1-P)=log(1-t^N)^K
log(1−P)=log(1−tN)K
l
o
g
(
1
−
P
)
=
K
⋅
l
o
g
(
1
−
t
N
)
log(1-P)=K·log(1-t^N)
log(1−P)=K⋅log(1−tN)
K
=
l
o
g
(
1
−
P
)
l
o
g
(
1
−
t
N
)
K=\frac{log(1-P)}{log(1-t^N)}
K=log(1−tN)log(1−P)
计算t=0.9,N=3时,想要RANSAC成功率P达到P>=0.80,所需要的迭代次数K:
K
=
l
o
g
(
1
−
0.80
)
l
o
g
(
1
−
0.
9
3
)
K=\frac{log(1-0.80)}{log(1-0.9^3)}
K=log(1−0.93)log(1−0.80)















 1033
1033











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









