







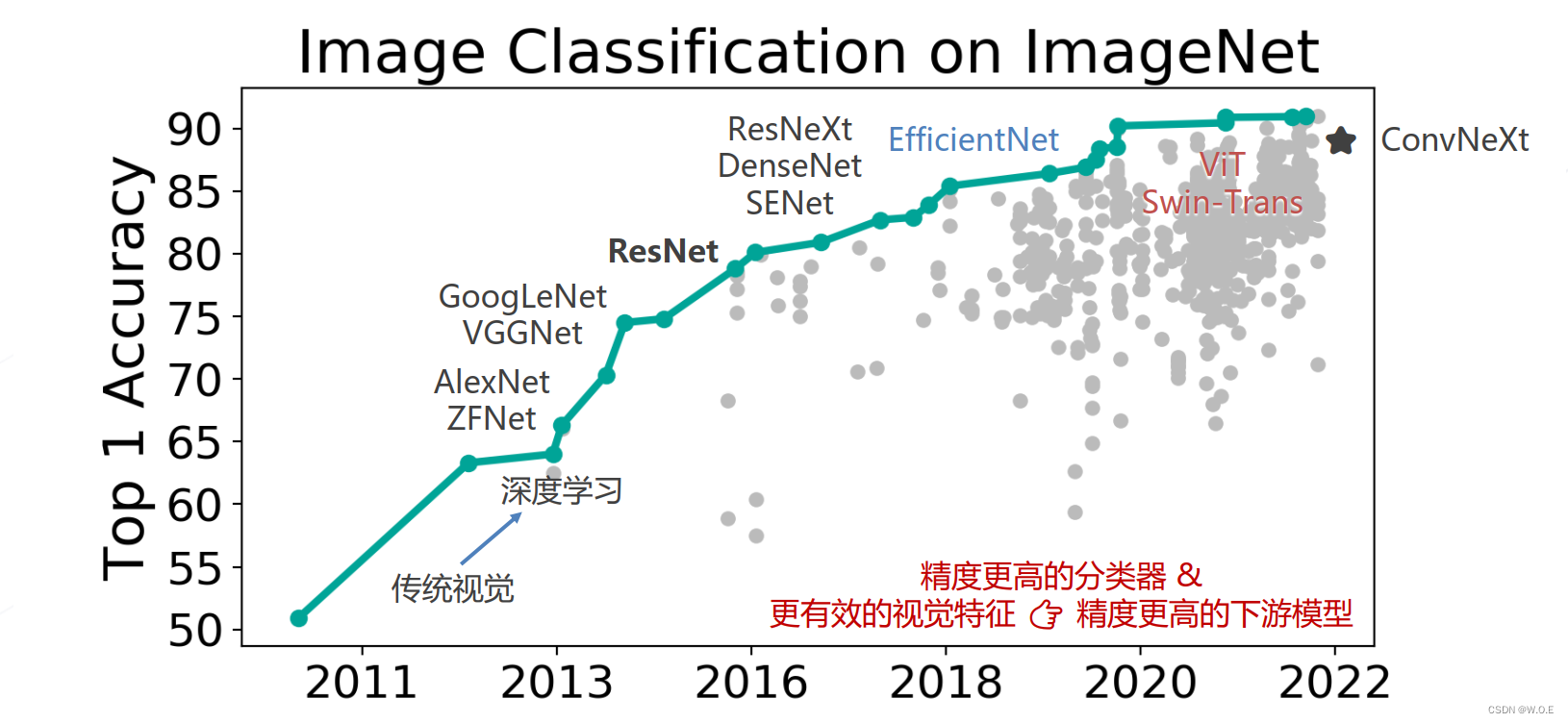
图像分类

模型设计
卷积神经网络
- AlexNet (2012)
- Going Deeper (2012~2014):VGG (2014)、GoogLeNet (Inception v1, 2014)
- 残差网络 ResNet (2015)
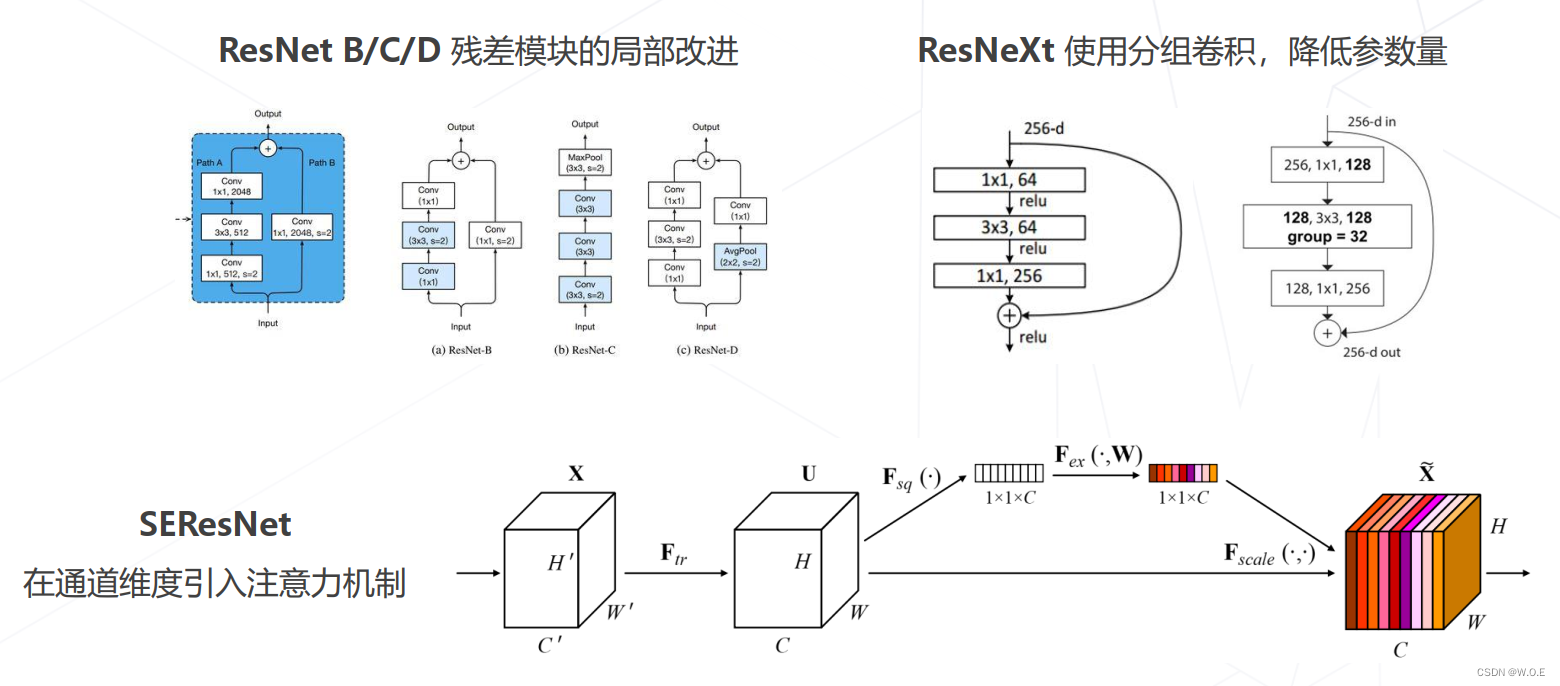
- ResNet 的后续改进
- 神经结构搜索 Neural Architecture Search (2016+):NASNet (2017)、 MnasNet (2018)、 EfficientNet (2019) 、 RegNet (2020) 等,借助强化学习等方法搜索表现最佳的网络
- Vision Transformers (2020+):Vision Transformer (2020), Swin-Transformer (2021 ICCV 最佳论文),使用 Transformer 替代卷积网络实现图像分类,使用更大的数据集训练,达到超越卷积网络的精度
- ConvNeXt (2022):将 Swin Transformer 的模型元素迁移到卷积网络中,性能反超 Transformer
图像分类 & 视觉基础模型的发展
轻量化卷积神经网络
- GoogLeNet 使用不同大小的卷积核
- ResNet 使用1×1卷积压缩通道数
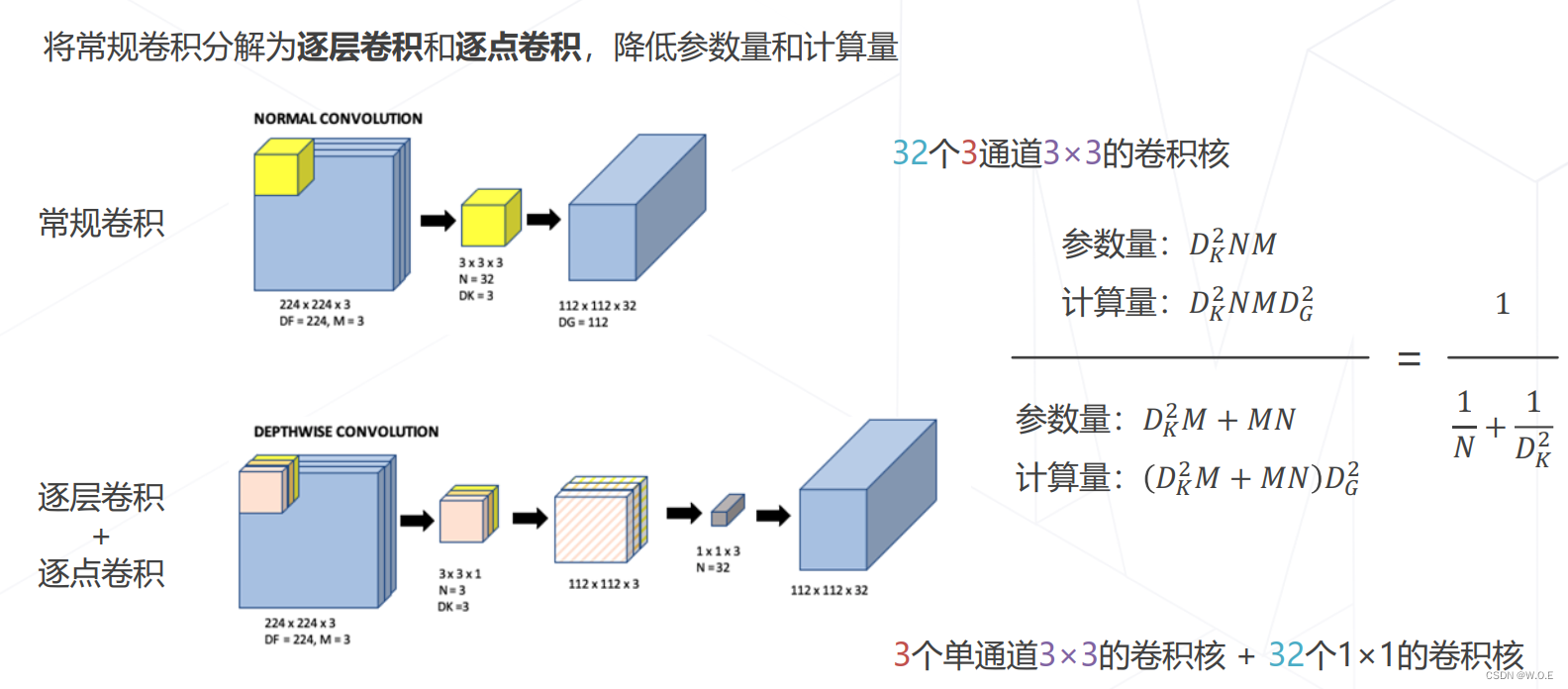
- 可分离卷积
- MobileNet V1/V2/V3 (2017~2019):MobileNet V1 使用可分离卷积,只有 4.2M 参数,MobileNet V2/V3 在 V1 的基础上加入了残差模块和 SE 模块
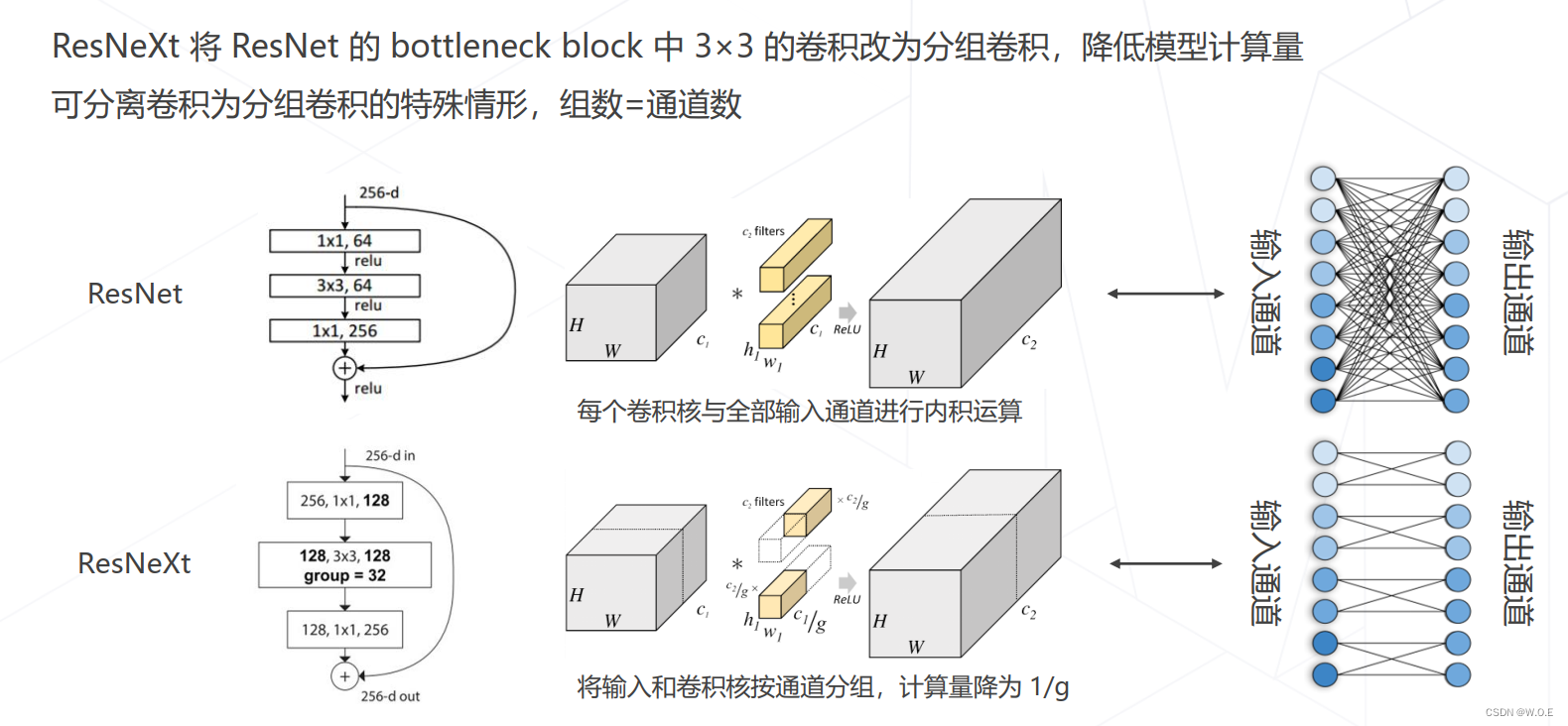
- ResNeXt 中的分组卷积
Vision Transformers
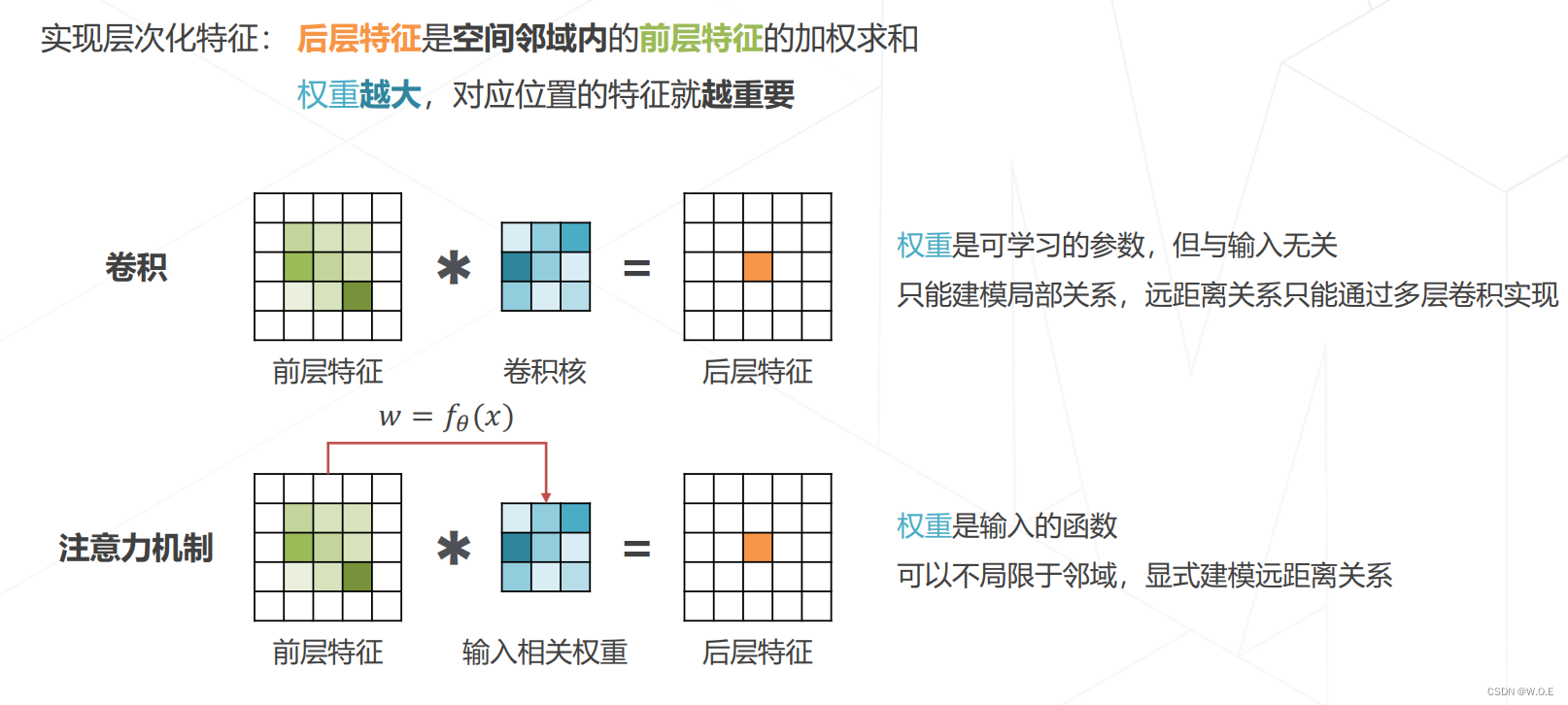
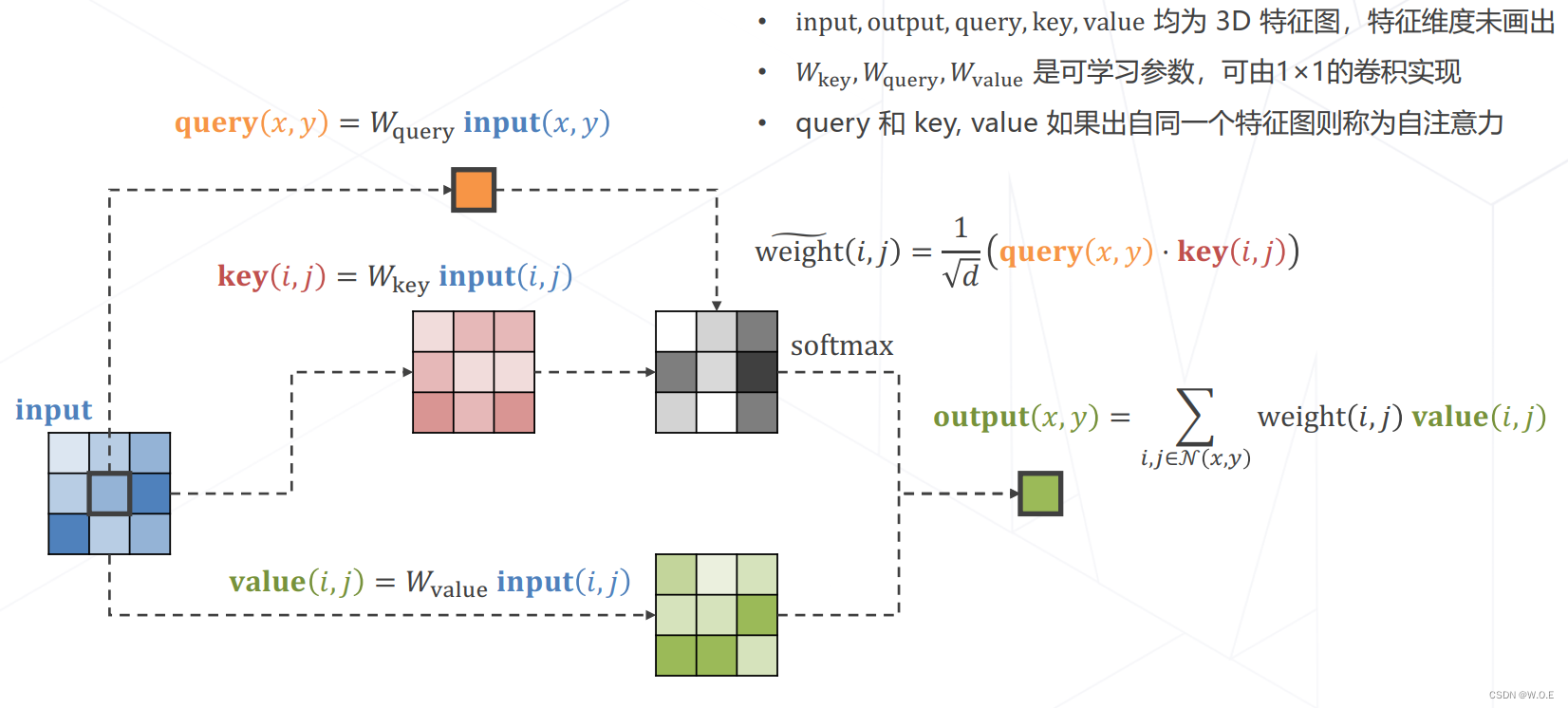
- 注意力机制 Attention Mechanism
- 实现Attention
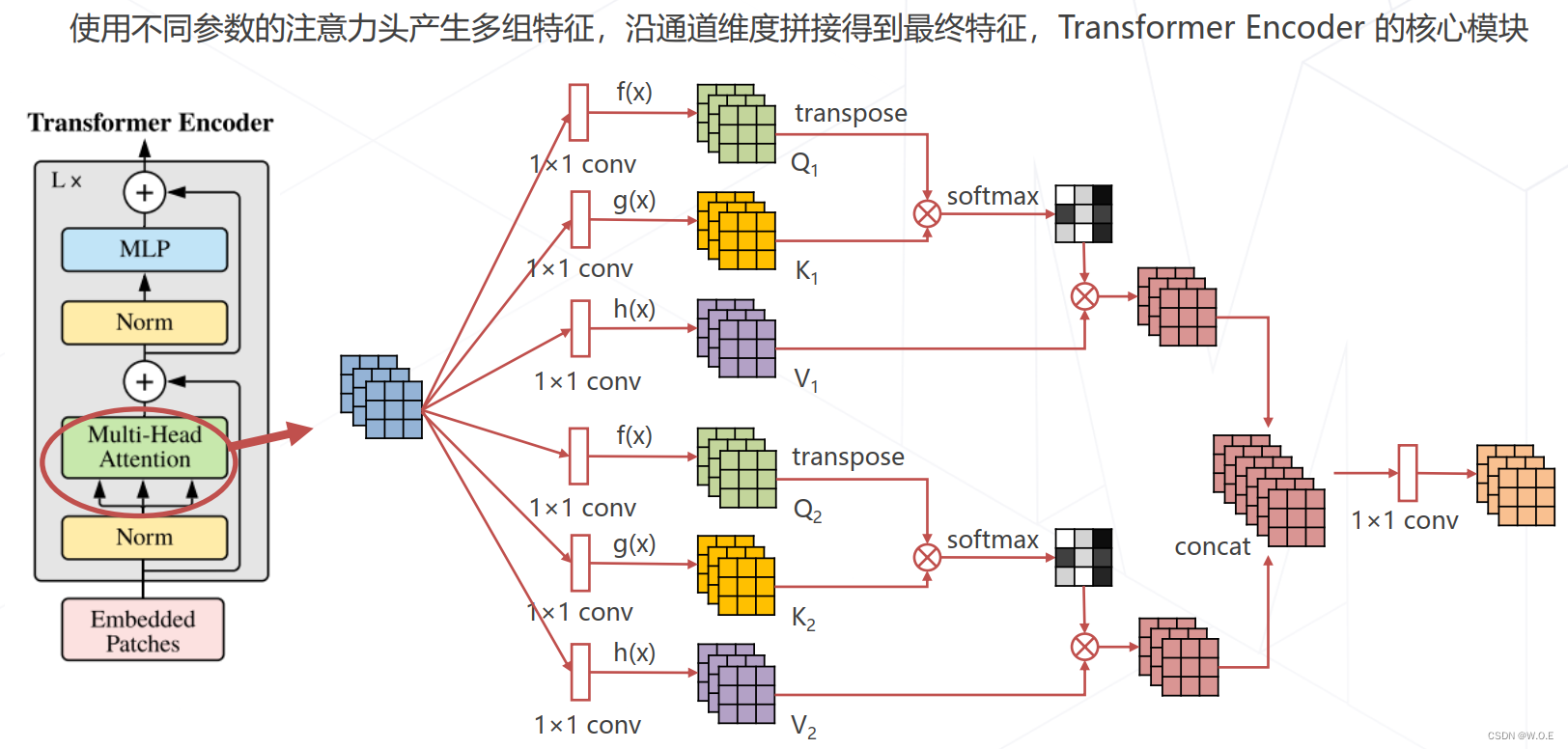
- 多头注意力 Multi-head (Self-)Attention
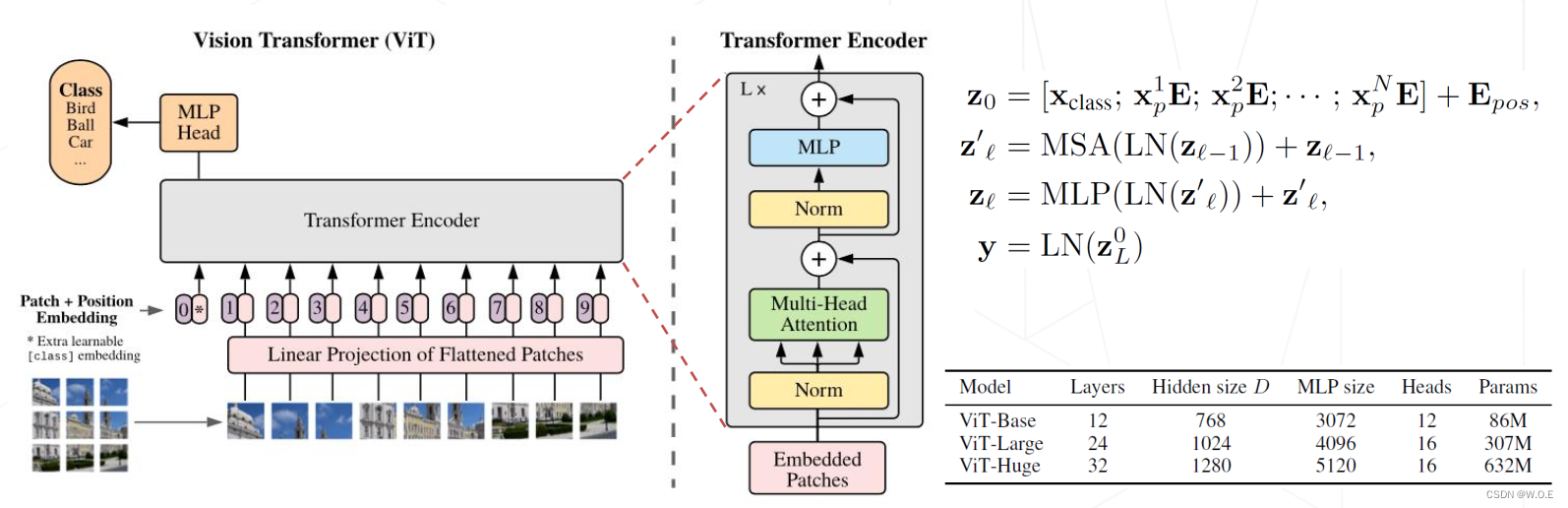
- Vision Transformer (2020)
- 将图像切分成若干 16×16 的小块,当作一列"词向量",经多层 Transformer Encoder 变换产生特征
- 图块之外加入额外的 token,用于 query 其他 patch 的特征并给出最后分类
- 注意力模块基于全局感受野,复杂度为尺寸的 4 次方
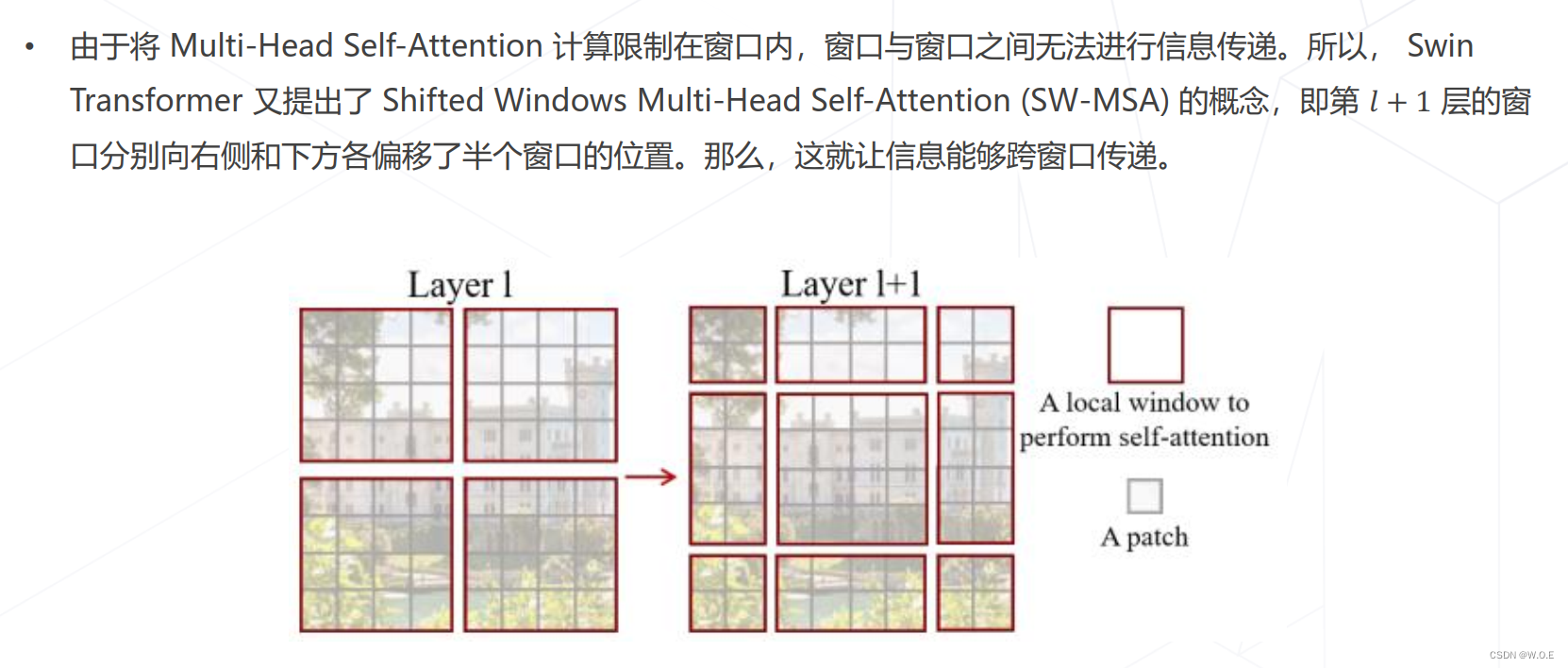
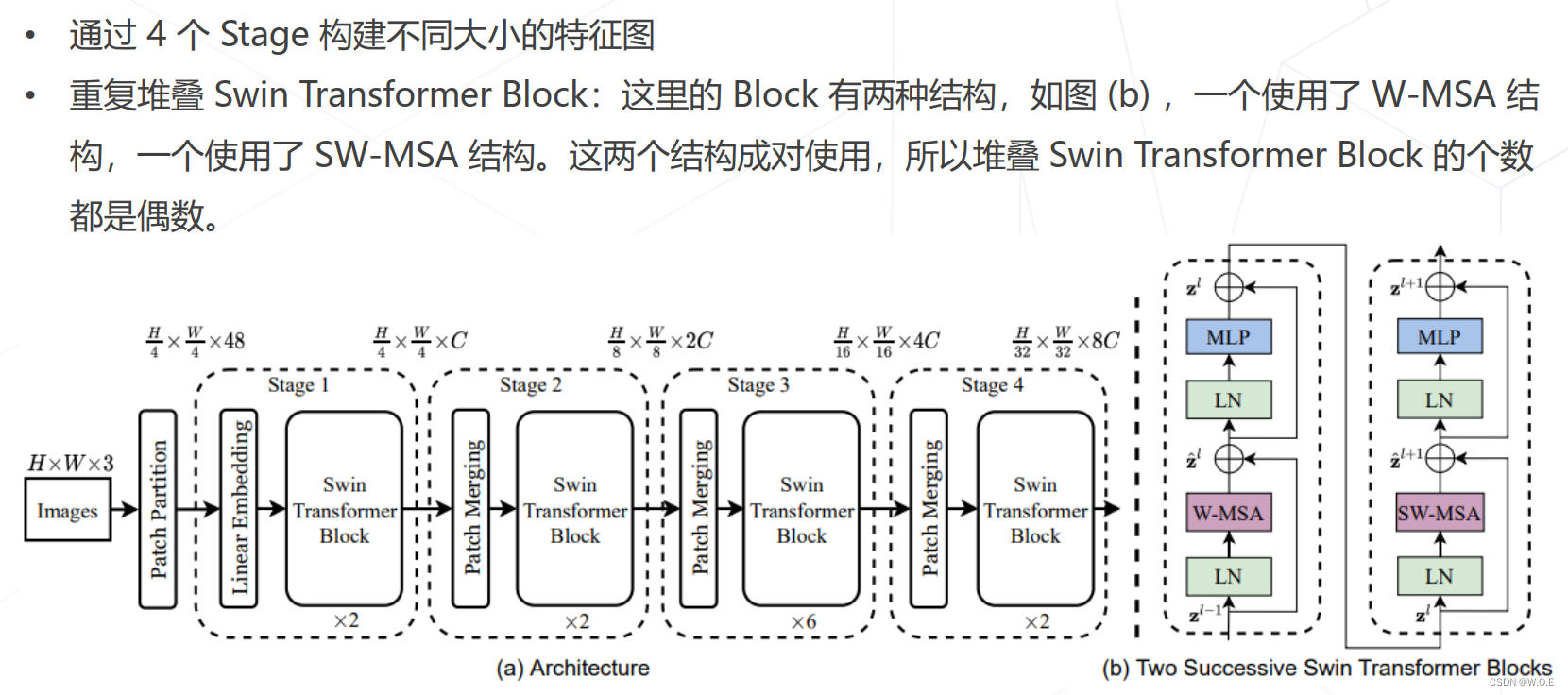
- Swin Transformer (ICCV 2021 best paper)

模型学习
监督学习
基于标注数据学习

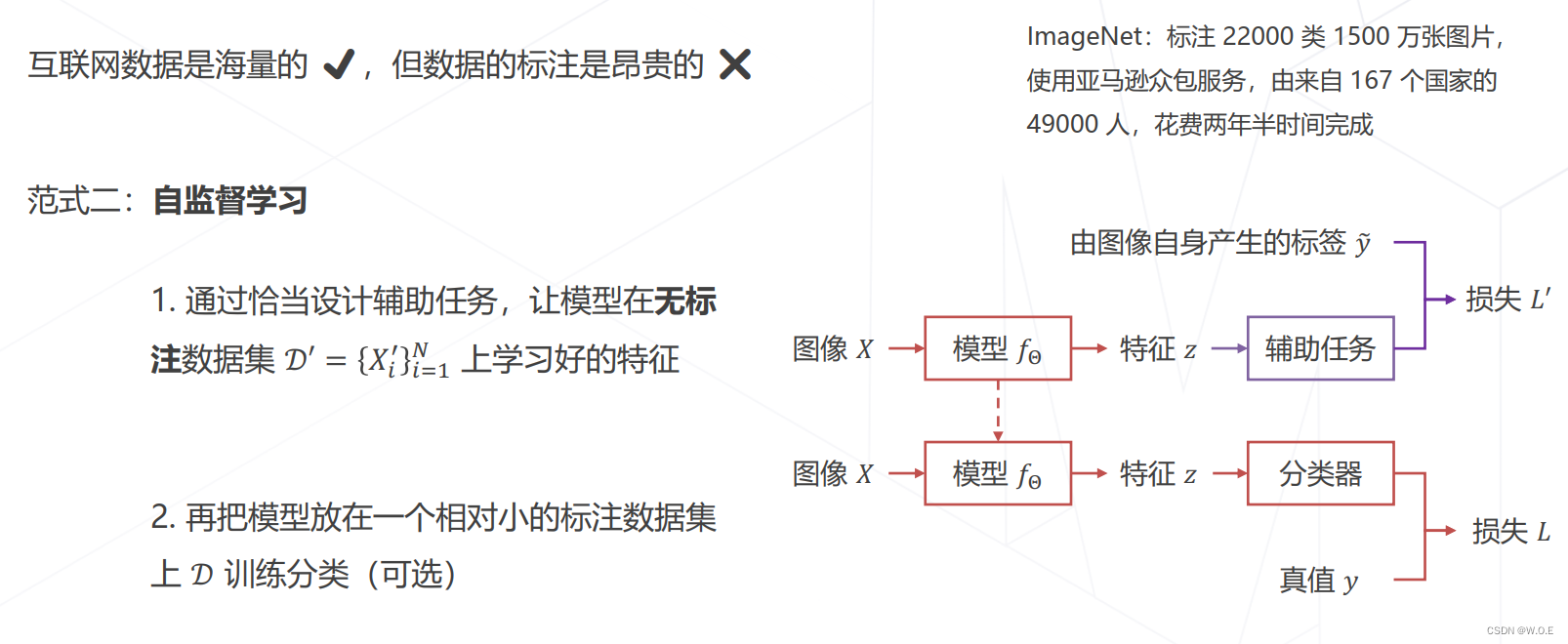
自监督学习
基于无标注的数据学习
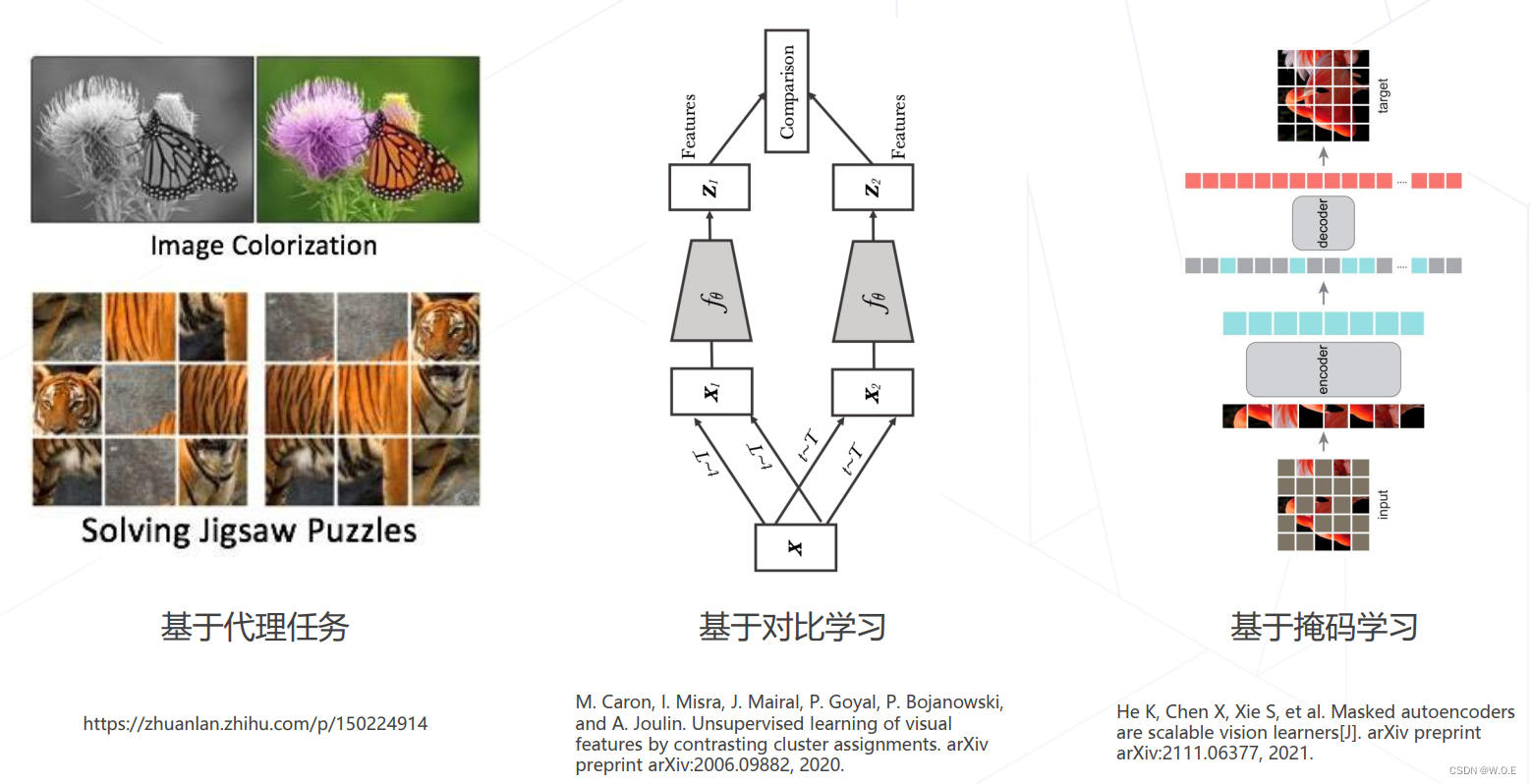
- 常见类型
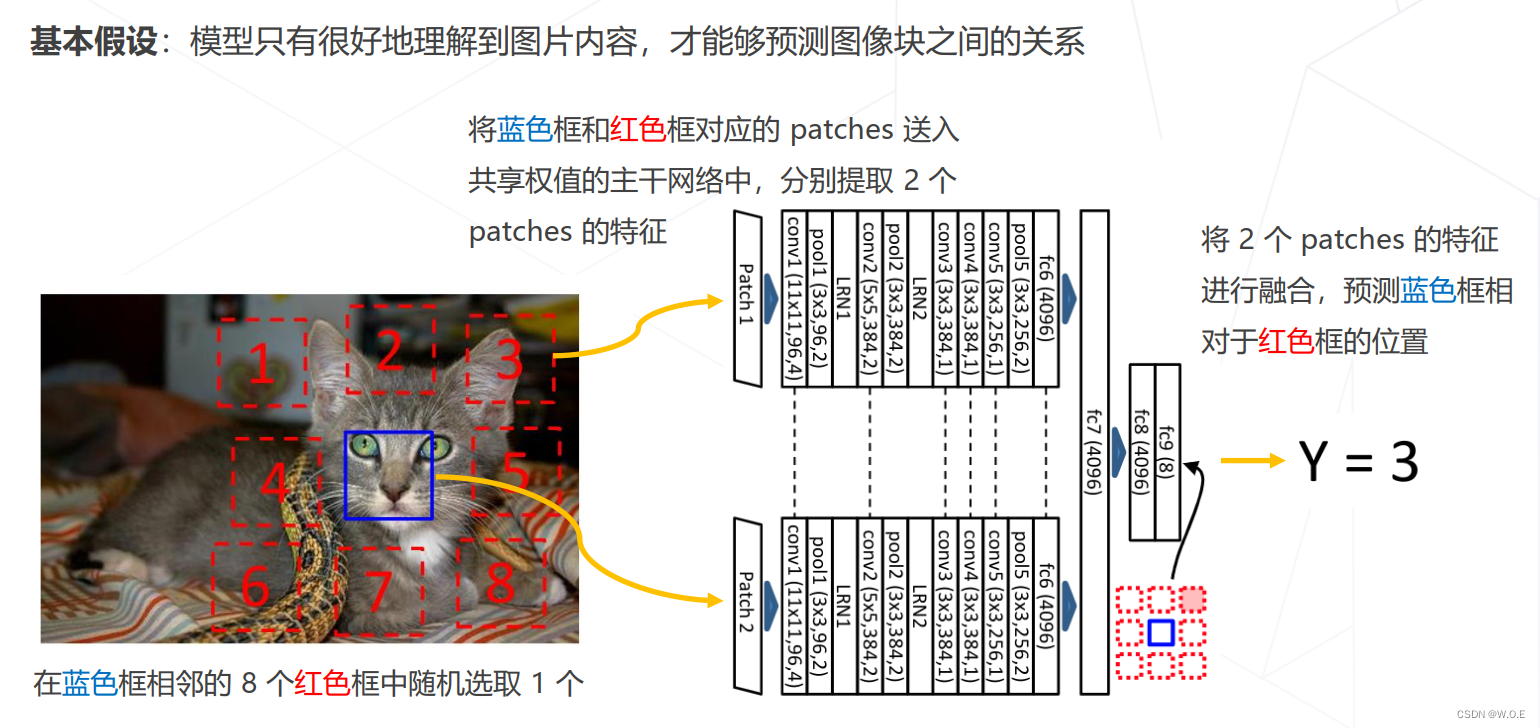
- Relative Location (ICCV 2015)
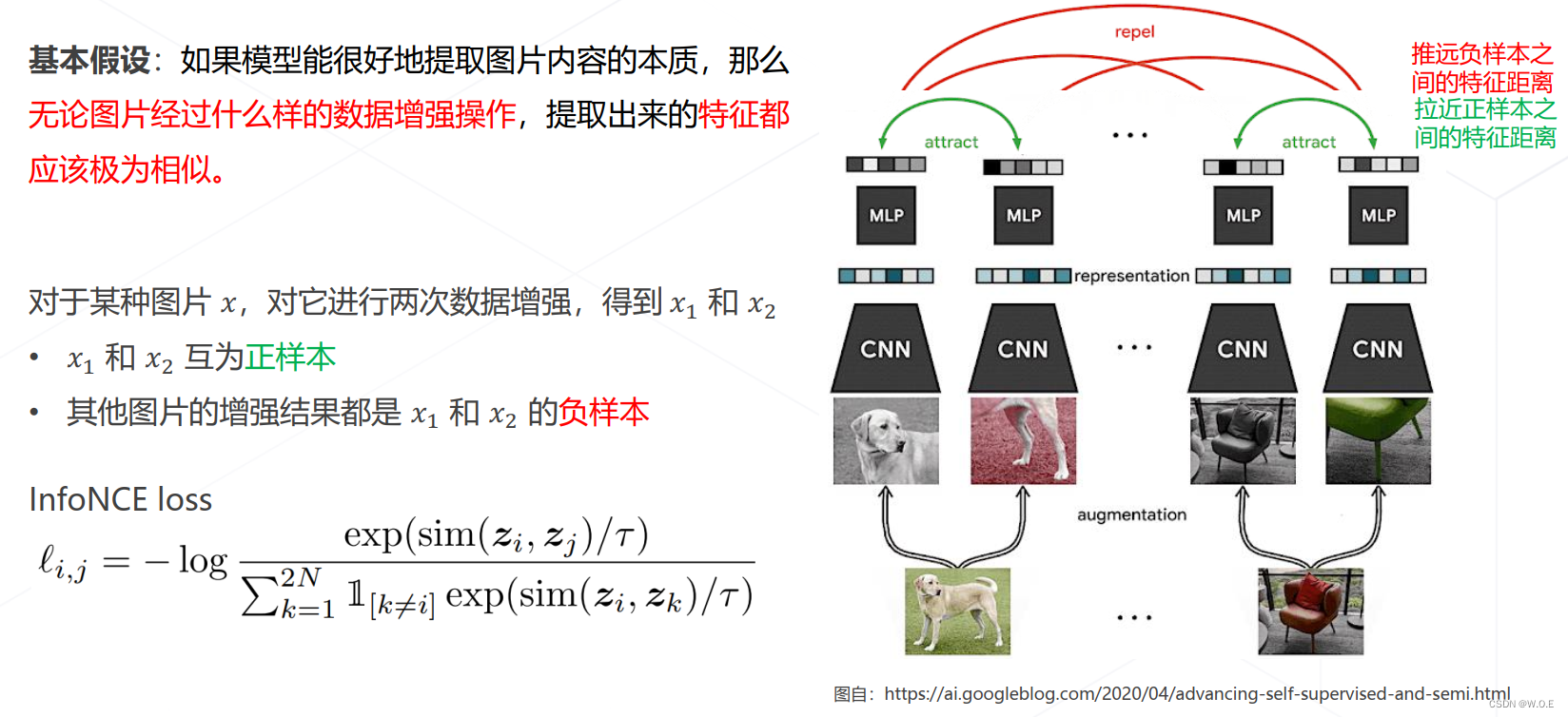
- SimCLR (ICML 2020)
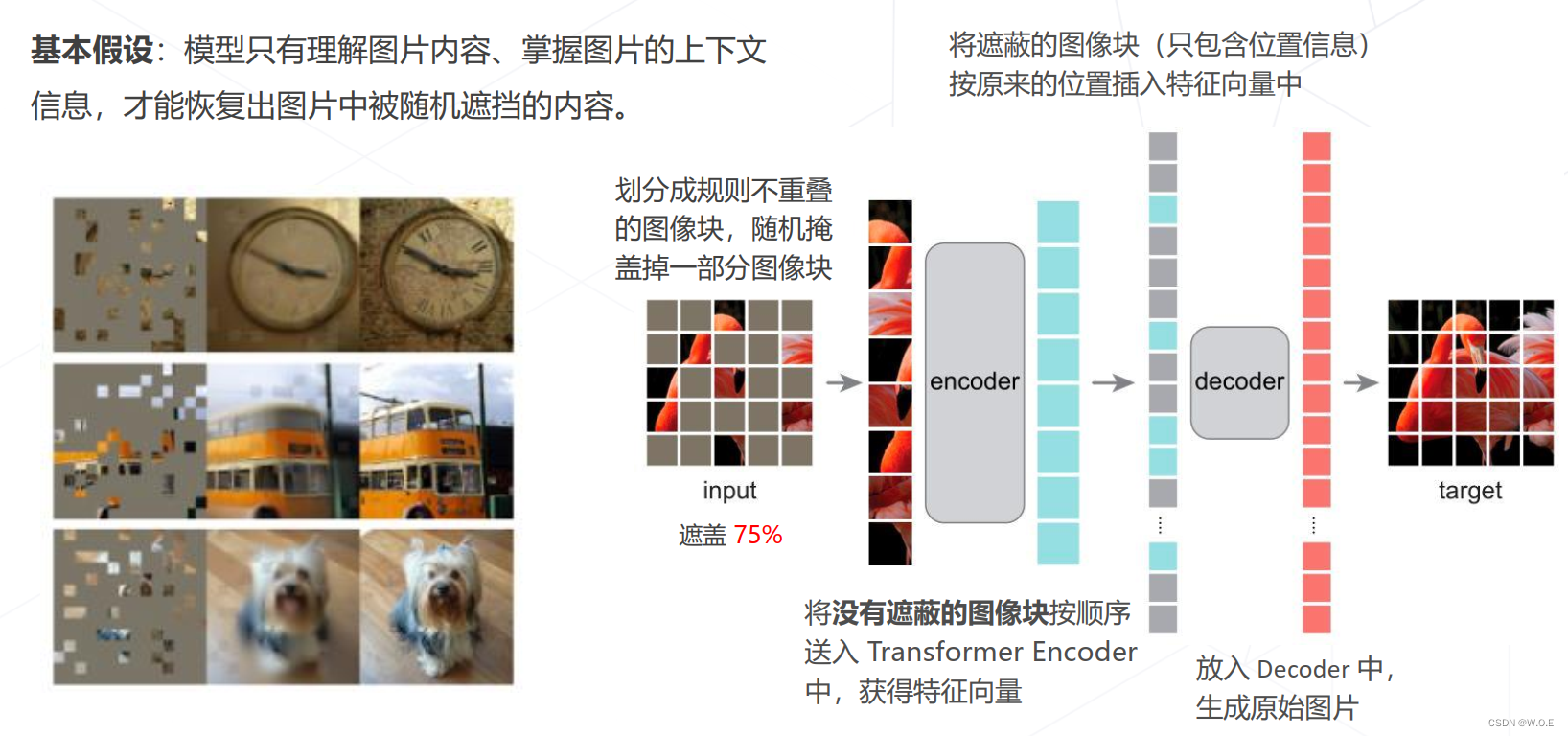
- Masked autoencoders (MAE, CVPR 2022)
数据增强
- 组合数据增强
- 组合图像 Mixup & CutMix
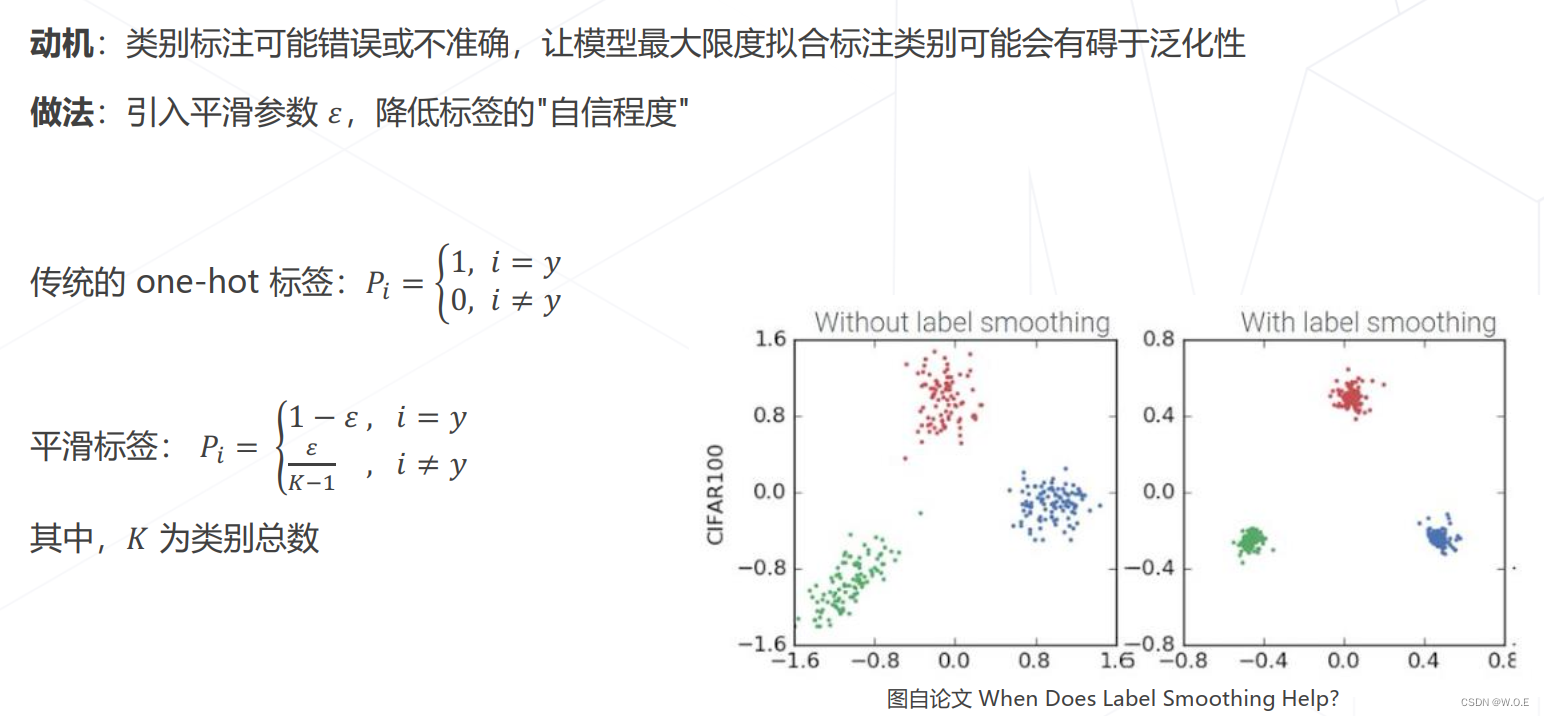
- 标签平滑 Label Smoothing

















 3736
3736











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









