






第二讲是王若晖博士讲解,内容依然是简介和理论。
提示:以下是本篇文章正文内容,下面案例可供参考
一、图像分类的数学表示
设计一个函数,以图像为输入,输出图像属于各个类别的概率,概率最大的那个分布即最终答案。

二、Vision Transformers
1、注意力机制 Attention Mechanism
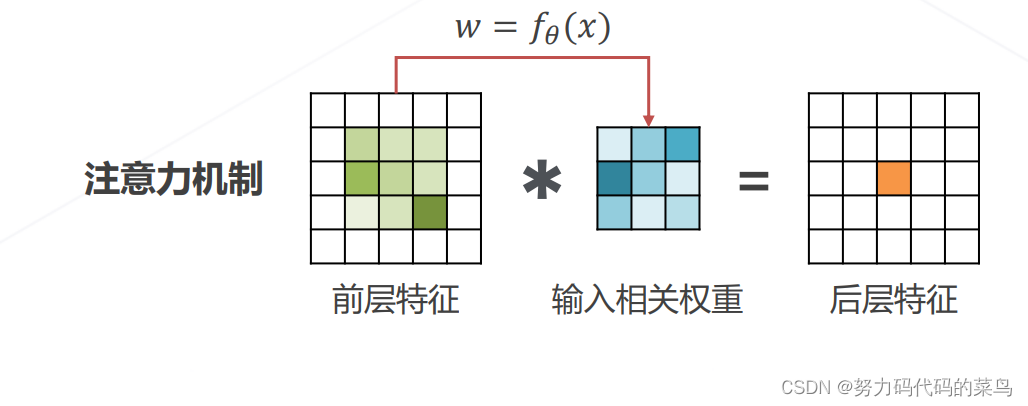
实现层次化特征:后层特征是空间邻域内的浅层特征的加权求和。
特征的物理意义:权重越大,对应位置的特征就越重要
与卷积不同点:
- 卷积:权重是可学习的参数,一个常数,与输出无关。有局限性,只能建模局部关系,远距离关系只能通过多层卷积实现。
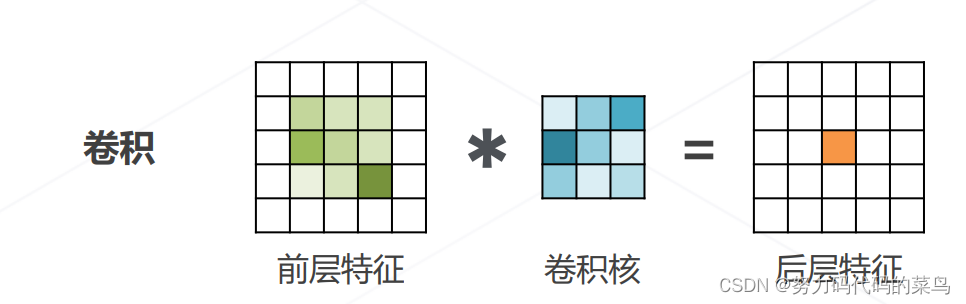
- 注意力机制:权重是一个输入的函数。可以不局限于邻域,显示建模远距离关系。
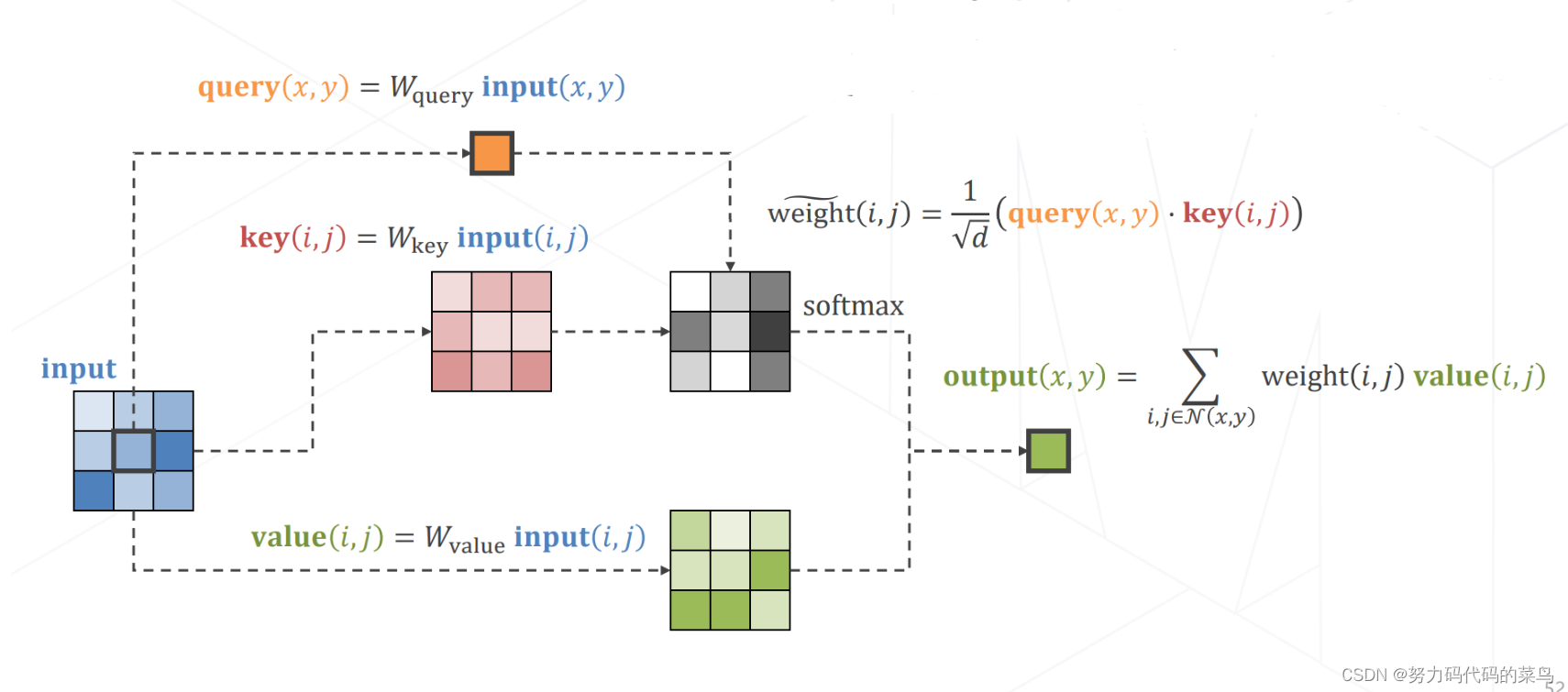
2、实现Attention
- input,output,query,key,value 均为3D特征图,特征维度未画出。
- Wkey,Wquery,Wvalue是学习参数,可由1*1的卷积实现。
- query,key,value如果出自同一个特征图则称为自注意力。
3、多头注意力
类似卷积的多通道。
使用不同参数的注意力头产生多组特征,沿通道维度拼接得到最终特征,Transformer Encoder的核心模块。
三、学习率与优化器策略
1、权重初始化
针对卷积层和全连接层,初始化连接权重W和偏置b。
(i)随机初始化
1.朴素方法:依照均匀分布或高斯分布。
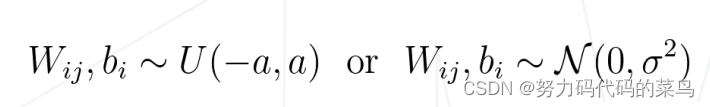
2.Xavier
3.Kaiming
(ii)用训练好的模型(通常基于 ImageNet数据集)进行权重初始化
- 替换预训练模型的分类头,进行微调训练(finetune)
2、学习率策略:学习率退火 Annealing
在训练过程中,学习率可以不一成不变。
- 从头训练可使用较大学习率,例如0.01~0.1。
- 微调(损失函数稳定后)通常使用较小学习率,例如0.001~0.01。
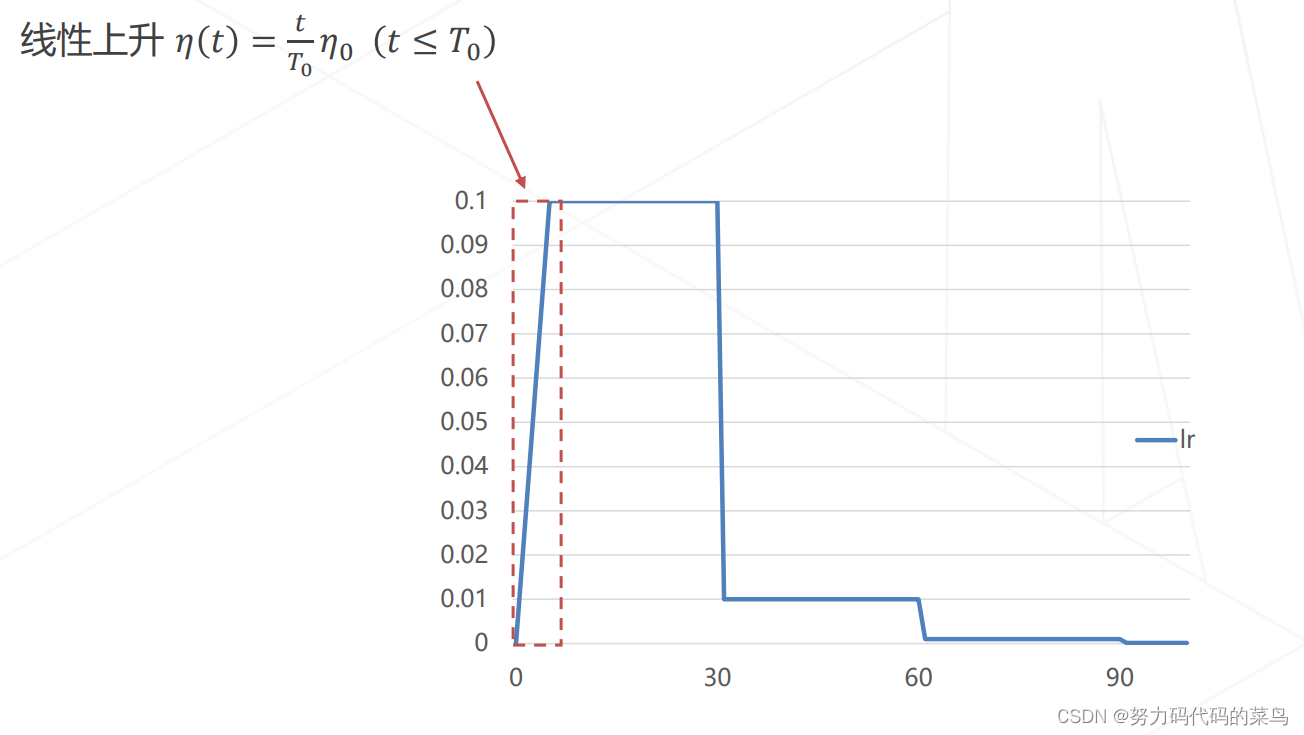
3、学习率策略:学习率升温 Warmup
在训练前几轮让学习率从0开始逐渐上升,直到预设的学习率,以稳定训练的初始阶段。
四、数据增强
训练泛化性能好的模型,需要大量多样化的数据,而数据的采集标注有成本。
可以通过简单的变换(几何变换,色彩变幻,随机遮挡)产生一系列“副本”,扩充训练数据集。















 3736
3736











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









