






点乱.....有空整理......
数据集介绍
VOC 格式
voc 形式的数据集一般包含以下几个文件夹
- Annotations
- ImageSets
- JPEGImages
- SegmentationClass
- SegmentationObject
对于目标检测的任务而言,一般只需要用到 Annotations 文件夹和 JPEGImages 文件夹,其中测试图片和训练图片都保存在一个目录下面,通过 ImageSets 文件夹中 Main 子文件夹下面的 txt 文件来对测试图片和验证图片进行解析。
JPEGImages 主要提供的是PASCAL VOC所提供的所有的图片信息,包括训练图片,测试图片,这些图像就是用来进行训练和测试验证的图像数据。
Annotations 主要存放 xml 格式的标签文件,每个 xml 对应 JPEGImage 中的一张图片
ImageSetsMain 图像物体识别的数据,总共 20 类, 需要保证 train、val 没有交集
SegmentationObject & SegmentationClass 保存的是物体分割后的数据,在物体识别中没有用到
<annotation>
<folder>VOC2012</folder> // 图像所在文件夹
<filename>2007_000392.jpg</filename> // 文件名
<source> // 图像来源(不重要)
<database>The VOC2007 Database</database>
<annotation>PASCAL VOC2007</annotation>
<image>flickr</image>
</source>
<size> // 图像尺寸(长宽以及通道数)
<width>500</width>
<height>332</height>
<depth>3</depth>
</size>
<segmented>1</segmented> // 是否用于分割(在图像物体识别中01无所谓)
<object> // 目标对象的信息
<name>horse</name> // 物体类别
<pose>Right</pose> // 拍摄角度
<truncated>0</truncated> // 是否被截断(0表示完整)
<difficult>0</difficult> // 目标是否难以识别(0表示容易识别)
<bndbox> // bounding-box 边界框信息(包含左下角和右上角xy坐标)
<xmin>100</xmin>
<ymin>96</ymin>
<xmax>355</xmax>
<ymax>324</ymax>
</bndbox>
</object>
<object> // 下面是其他目标的信息,这里略掉
......
</object>
</annotation>
一般而言,有图片的名称、长和宽等信息,之后一张图片对应有多个 object,每个 object 中包含了类名、然后三个对于目标检测而言不重要的信息,以及 bndbox 信息,bndbox 信息十分重要,主要是左上角的坐标和右下角的坐标。
COCO格式
coco 数据集为 json 文件,一般包含5个字段
- info
- images
- annotations
- licenses
- categories
info
info 字段包含了数据集的基本信息,包括数据集的来源,提供者之类的,info 字段在写程序的时候一般不会使用到,内容如下:
info: {
"year": int, # 年份
"version": str, # 版本
"description": str, # 数据集描述
"contributor": str, # 提供者
"url": str, # 下载地址
"date_created": datetime
}
licenses
licenses 字段表明了图片的版权信息之类的,一般的程序中也用不到,licenses字段的结构如下:
license{
"id": int,
"name": str,
"url": str,
}
images
images 字段是整个 json 文件中最重要的字段之一,包含了图片的基本信息,包括图片的名称,宽高。images 目录由多个 image 构成数组,可以遍历。每一个 image 的实例是一个 dict。其中有一个 id 字段,代表的是图片的 id,每一张图片具有唯一的一个独特的 id。结构如下:
image{
"id": int, # 图片的ID编号(每张图片ID是唯一的)
"width": int, # 宽
"height": int, # 高
"file_name": str, # 图片名
"license": int,
"flickr_url": str, # flickr网路地址
"coco_url": str, # 网路地址路径
"date_captured": datetime # 数据获取日期
}
annotations
annotations 存储图片的标注信息,结构如下:
annotation{
"id": int, # 对象ID,因为每一个图像有不止一个对象,所以要对每一个对象编号(每个对象的ID是唯一的)
"image_id": int, # 对应的图片ID(与images中的ID对应)
"category_id": int, # 类别ID(与categories中的ID对应)
"segmentation": RLE or [polygon], # 对象的边界点(边界多边形,此时iscrowd=0)。
# segmentation 格式取决于这个实例是一个单个的对象(即iscrowd=0,将使用polygons格式)还是一组对象(即iscrowd=1,将使用RLE格式)
"area": float, # 区域面积
"bbox": [x,y,width,height], # 定位边框 [x,y,w,h]
"iscrowd": 0 or 1 # 见下
}
其中注意这里的bbox格式为[x,y,width,height]。[x,y,w,h]是没有进行归一化的,所以在进行yolo的转化时需要进行归一化的处理。
categories
categories字段是记录annotations字段中的类别信息,结构如下:
{
"supercategory": str, # 主类别
"id": int, # 类对应的id (0 默认为背景)
"name": str # 子类别
}YOLO数据集格式
YOLO标注格式保存在txt文件中,有5个数据,用空格隔开。
<object-class> <x> <y> <width> <height>x, y 是目标的中心坐标,width, height 是目标的宽和高。这些值是通过归一化得到的,其中 x, width 是使用原图的 width 进行归一化,y, height 是使用原图的 height 进行归一化的。

若图像的高和宽别为h, w,bbox的左上角坐标为(,
),右下角坐标为(
,
),bbox中心坐标(
,
)为:
YOLO的5个数据:l,其对应关系:
反过来,则有:

批量修改XML标注文件的标签名

对于瑕疵点的类别都视为0
# coding :UTF-8
# Time : 2022/3/23 21:38
# Author : Alchemist
# File : amend_label_xml.py
# Software: PyCharm
'''
使用python xml解析树解析xml文件,批量修改xml文件里object节点下name节点的text
'''
import os
import xml.etree.ElementTree as ET
file_dir = './label'
for root, dirs, files in os.walk(file_dir):
if len(files) != 0: # 路径下所有非目录子文件不为空
xml_dir = root # xml文件所在目录
for i in range(len(files)):
if files[i].split(' ')[1].split('.')[1] == 'xml': # 针对自己的文件名进行分割
xml_path = os.path.join(xml_dir, files[i]) # xml文件路径
tree = ET.parse(xml_path)
obj_list = tree.getroot().findall('object')
for per_obj in obj_list:
if per_obj[0].text: # 待修改的标签名
per_obj[0].text = 'flaw' # 欲修改成的标签名
tree.write(xml_path) # 将改好的文件重新写入,会覆盖原文件
# 自己写的,弱鸡本人😭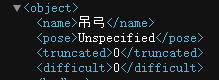
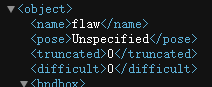
天池布匹瑕疵竞赛数据集格式转换(json —> txt)

对于瑕疵点的类别都视为0
# coding :UTF-8
# Time : 2022/3/23 15:38
# Author : Alchemist
# File : tianchi_json2txt.py
# Software: PyCharm
import json
import os.path
import cv2
# import shutil as sh
from tqdm.auto import tqdm
# 原标签文件的存放地址(json)
json_path = r'./train/18/Annotations/anno_train.json'
# 原图片存放目录地址
image_path = r'./train/18/defect_Images'
name_list = [] # 存放图片名
label_list = [] # 存放标签名
image_h_list = [] # 存放图片的高度
image_w_list = [] # 存放图片的宽度
x_center_list = [] # 存放bbox中心点的x轴坐标
y_center_list = [] # 存放bbox中心点的y轴坐标
w_list = [] # 存放bbox的宽度
h_list = [] # 存放bbox的高度
with open(json_path, mode = 'r') as f:
temps = tqdm(json.loads(f.read())) # 读取整个文件
for temp in temps:
name = temp["name"].split('.')[0] # 截取图片名(无文件扩展名)
path = os.path.join(image_path, temp['name']) # 获取图片的路径(含扩展名)
im = cv2.imread(path)
sp = im.shape # 读取矩阵的形状(图片的高、宽、通道数)
image_h, image_w = sp[0], sp[1] # 获取图片的高宽
x_l, y_l, x_r, y_r = temp['bbox'] # 获取bbox的坐标(坐上、右下)
if temp['defect_name']: # 修改标签,个人将所有疵点归为一类
defect_name = '0'
# bbox的归一化后的中心点坐标
x_center = (x_l+x_r) / (2*image_w)
y_center = (y_l+y_r) / (2*image_h)
# bbox的归一化后的宽高
w = (x_r-x_l) / image_w
h = (y_r-y_l) / image_h
name_list.append(temp['name']) # 存入图片名
label_list.append(defect_name) # 存入标签名
image_h_list.append(image_h) # 存入图片的高
image_w_list.append(image_w) # 存入图片的宽
x_center_list.append(x_center) # 存入bbox归一化后中心点的x轴坐标
y_center_list.append(y_center) # 存入bbox归一化后中心点的y轴坐标
w_list.append(w) # 存入bbox归一化后的宽度
h_list.append(h) # 存入bbox归一化后的高度
index = list(set(name_list))
# val_index = index[:len(index) // 5] # 选取一部分作为测试集
space = ' '
for num, name in enumerate(name_list):
row = [label_list[num], space, x_center_list[num], space, y_center_list[num], space, w_list[num], space, h_list[num]] # 获取yolo标签格式
# if name in val_index:
# path2save = 'val/'
# else:
# path2save = 'train/'
if not os.path.exists('./train/labels'):
os.makedirs('./train/labels')
with open('./train/labels/' + name.split('.')[0] + '.txt', 'a+') as f:
for data in row:
f.write('{}'.format(data))
f.write('\n')
# if not os.path.exists('./train/images'):
# os.makedirs('./train/images')
# sh.copy(os.path.join(image_path, name), './train/images/{}'.format(name))
'''
****************************** tqdm ******************************
Tqdm是快速、可扩展的Python进度条,可在Python长循环中添加一个进度提示信息,用户只需要封装任意的迭代器tqdm(iterator)即可
tqdm(list)方法可以传入任意一种list,比如数组
from tqdm import tqdm
for i in tqdm(range(1000)):
#do something
pass
或者string的数组
for char in tqdm(["a", "b", "c", "d"]):
#do something
pass
****************************** split ******************************
Python split() 通过指定分隔符对字符串进行切片,如果参数 num 有指定值,则分隔 num+1 个子字符串
语法:str.split(str="", num=string.count(str)).
参数:
str -- 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。
num -- 分割次数。默认为 -1, 即分隔所有。
输入输出:
>>> str="hello boy<[www.doiido.com]>byebye"
>>> str.split("[")[1].split("]")[0]
'www.doiido.com'
>>> str.split("[")[1].split("]")[0].split(".")
['www', 'doiido', 'com']
解析:
str.split("[")[1]. split("]")[0]输出的是 [ 后的内容以及 ] 前的内容。
str.split("[")[1]. split("]")[0]. split(".") 是先输出 [ 后的内容以及 ] 前的内容,然后通过 . 作为分隔符对字符串进行切片。
****************************** set ******************************
set() 函数创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等。
set 语法:class set([iterable])
参数说明:iterable -- 可迭代对象对象
返回值:返回新的集合对象。
****************************** list ******************************
list() 方法用于将元组或字符串转换为列表。
注:元组与列表是非常类似的,区别在于元组的元素值不能修改,元组是放在括号中,列表是放于方括号中。
list()方法语法:list( seq )
参数:seq -- 要转换为列表的元组或字符串。
返回值:返回列表。
****************************** enumerate ******************************
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
enumerate() 方法语法:enumerate(sequence, [start=0])
参数:sequence -- 一个序列、迭代器或其他支持迭代对象;start -- 下标起始位置的值。
返回值:返回 enumerate(枚举) 对象。
'''依据xml文件,将图片名写入txt文本中
# coding :UTF-8
# Time : 2022/3/24 20:38
# Author : Alchemist
# File : xml2txt.py
# Software: PyCharm
import os
import random
import argparse
parser = argparse.ArgumentParser()
# xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default=r'./Annotations', type=str, help='input xml label path')
# 数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default=r'./ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
trainval = random.sample(list_index, num)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
for i in list_index:
name = total_xml[i][:-4] + '\n'
file_trainval.write(name)
file_trainval.close()
# 将数据集分类并将图片名写入文本中
# parser = argparse.ArgumentParser()
# #xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
# parser.add_argument('--xml_path', default=r'D:\new\11\yolov5-master\data\VOC2007\Annotations', type=str, help='input xml label path')
# #数据集的划分,地址选择自己数据下的ImageSets/Main
# parser.add_argument('--txt_path', default=r'D:\new\11\yolov5-master\data\VOC2007\ImageSets\Main', type=str, help='output txt label path')
# opt = parser.parse_args()
#
# trainval_percent = 1.0
# train_percent = 0.9
# xmlfilepath = opt.xml_path
# txtsavepath = opt.txt_path
# total_xml = os.listdir(xmlfilepath)
# if not os.path.exists(txtsavepath):
# os.makedirs(txtsavepath)
#
# num = len(total_xml)
# list_index = range(num)
# tv = int(num * trainval_percent)
# tr = int(tv * train_percent)
# trainval = random.sample(list_index, tv)
# train = random.sample(trainval, tr)
#
# file_trainval = open(txtsavepath + '/trainval.txt', 'w')
# file_test = open(txtsavepath + '/test.txt', 'w')
# file_train = open(txtsavepath + '/train.txt', 'w')
# file_val = open(txtsavepath + '/val.txt', 'w')
#
# for i in list_index:
# name = total_xml[i][:-4] + '\n'
# if i in trainval:
# file_trainval.write(name)
# if i in train:
# file_train.write(name)
# else:
# file_val.write(name)
# else:
# file_test.write(name)
#
# file_trainval.close()
# file_train.close()
# file_val.close()
# file_test.close()
'''
**************************** argparse ****************************
argparse是python用于解析命令行参数和选项的标准模块,用于代替已经过时的optparse模块。argparse模块的作用是用于解析命令行参数。
使用流程:
创建解析器:parser = argparse.ArgumentParser(description='Process some integers.')
使用 argparse 的第一步是创建一个 ArgumentParser 对象。
ArgumentParser 对象包含将命令行解析成 Python 数据类型所需的全部信息。
prog - 程序的名称(默认:sys.argv[0])
usage - 描述程序用途的字符串(默认值:从添加到解析器的参数生成)
description - 在参数帮助文档之前显示的文本(默认值:无)
epilog - 在参数帮助文档之后显示的文本(默认值:无)
parents - 一个 ArgumentParser 对象的列表,它们的参数也应包含在内
formatter_class - 用于自定义帮助文档输出格式的类
prefix_chars - 可选参数的前缀字符集合(默认值:’-’)
fromfile_prefix_chars - 当需要从文件中读取其他参数时,用于标识文件名的前缀字符集合(默认值:None)
argument_default - 参数的全局默认值(默认值: None)
conflict_handler - 解决冲突选项的策略(通常是不必要的)
add_help - 为解析器添加一个 -h/--help 选项(默认值: True)
allow_abbrev - 如果缩写是无歧义的,则允许缩写长选项 (默认值:True)
添加参数:parser.add_argument('integers', metavar='N', type=int, nargs='+', help='an integer for the accumulator')
给一个 ArgumentParser 添加程序参数信息是通过调用 add_argument() 方法完成的。
name or flags - 一个命名或者一个选项字符串的列表,例如 foo 或 -f, --foo。
action - 当参数在命令行中出现时使用的动作基本类型。
nargs - 命令行参数应当消耗的数目。
const - 被一些 action 和 nargs 选择所需求的常数。
default - 当参数未在命令行中出现时使用的值。
type - 命令行参数应当被转换成的类型。
choices - 可用的参数的容器。
required - 此命令行选项是否可省略 (仅选项可用)。
help - 一个此选项作用的简单描述。
metavar - 在使用方法消息中使用的参数值示例。
dest - 被添加到 parse_args() 所返回对象上的属性名。
解析参数:ArgumentParser 通过 parse_args() 方法解析参数。
'''
VOC数据格式—>YOLO数据格式
# coding :UTF-8
# Time : 2022/3/25 16:05
# Author : Alchemist
# File : xml2txt_label.py
# Software: PyCharm
import xml.etree.ElementTree as ET
import os
classes = ["flaw"] # 修改成自己的类别
def convert(size, box): # 对数据进行归一化处理
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 # bbox中心横坐标
y = (box[2] + box[3]) / 2.0 # bbox中心纵坐标
w = box[1] - box[0] # bbox宽
h = box[3] - box[2] # bbox高
x = x * dw
y = y * dh
w = w * dw
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
if not os.path.exists(r'D:\Code\Project\transform_dataset\Annotations/%s.xml' % (image_id)):
return
in_file = open(r'D:\Code\Project\transform_dataset\Annotations/%s.xml' % (image_id)) # 第二个%后的内容替换%s
out_file = open(r'D:\Code\Project\transform_dataset\label/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file) # 将 XML 文档解析为元素树
root = tree.getroot() # 返回树的根元素
size = root.find('size') # 按标签名称或路径查找第一个匹配元素
w = int(size.find('width').text) # Text before first subelement.
h = int(size.find('height').text)
for obj in root.iter('object'): # Create tree iterator
cls = obj.find('name').text # 获取标注的类别
cls_id = classes.index(cls) # Return first index of value
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
for image in os.listdir('images'): # 返回路径下文件名的列表
# 这里需要根据图片情况进行对应修改
image_id = image[:-4]
convert_annotation(image_id)

2021广东工业制造创新大赛 — 瓷砖瑕疵检测数据集
生成voc格式的数据集(json—>voc)
json文件
[
{ "name": "223_89_t20201125085855802_CAM3.jpg",
"image_height": 3500,
"image_width": 4096,
"category": 4,
"bbox": [
1702.79,
2826.53,
1730.79,
2844.53]
},
...
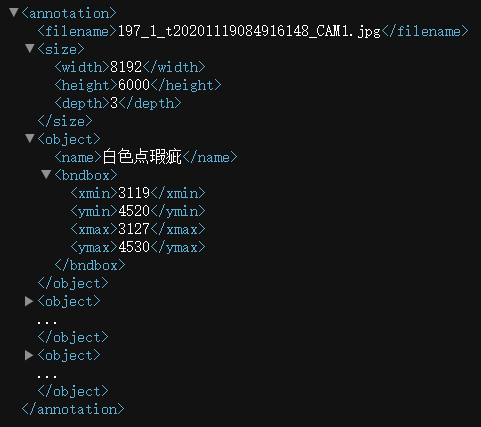
]xml文件
import codecs
import json
import os
# 瑕疵类别
class_name_dic = {
"0": "背景",
"1": "边异常",
"2": "角异常",
"3": "白色点瑕疵",
"4": "浅色点瑕疵",
"5": "深色点块瑕疵",
"6": "光圈瑕疵"
}
# 原始图片路径
rawImgDir = 'D:/PostGraduate/MachineVision/guangdong_tile_defect/tile_round1_train_20201231/train_imgs/'
# 原始标签路径(json)
rawLabelDir = r'D:\PostGraduate\MachineVision\guangdong_tile_defect\tile_round1_train_20201231\train_annos.json'
anno_dir = 'D:/PostGraduate/MachineVision/guangdong_tile_defect/tile_round1_train_20201231/voc/Annotations/'
if not os.path.exists(anno_dir):
os.makedirs(anno_dir)
with open(rawLabelDir) as f:
annos = json.load(f)
# print(annos) # {"name","h","w","category","bbox"},{...},{...},...
# 每张图片对应瑕疵的序号
image_ann = {}
for i in range(len(annos)): # len(annos)=15230 0-15229
anno = annos[i]
name = anno['name'] # 223_89_t20201125085855802_CAM3.jpg
if name not in image_ann:
image_ann[name]=[]
image_ann[name].append(i)
# print(image_ann) # {'22.jpg':[0], '23.jpg':[1, 2, 3, 4, 5], ...}
for name in image_ann.keys(): # 返回字典所有的键
indexs = image_ann[name] # 每张图片对应瑕疵的序号
# print(indexs) # [0] [1, 2, 3, 4, 5, 6, 7] [8, 9, 10]...
# print(indexs[0]) # 取每张图瑕疵序号的首位来表示该图
height, width = annos[indexs[0]]["image_height"], annos[indexs[0]]["image_width"]
with codecs.open(anno_dir + name[:-4] + '.xml', 'w', 'utf-8') as xml:
xml.write('<annotation>\n')
xml.write('\t<filename>' + name + '</filename>\n')
xml.write('\t<size>\n')
xml.write('\t\t<width>' + str(width) + '</width>\n')
xml.write('\t\t<height>' + str(height) + '</height>\n')
xml.write('\t\t<depth>' + str(3) + '</depth>\n')
xml.write('\t</size>\n')
for index in indexs:
obj = annos[index]
assert name == obj['name']
bbox = obj['bbox']
category = obj['category']
xmin, ymin, xmax, ymax = bbox
class_name = class_name_dic[str(category)]
xml.write('\t<object>\n')
xml.write('\t\t<name>' + class_name + '</name>\n')
xml.write('\t\t<bndbox>\n')
xml.write('\t\t\t<xmin>' + str(int(xmin)) + '</xmin>\n')
xml.write('\t\t\t<ymin>' + str(int(ymin)) + '</ymin>\n')
xml.write('\t\t\t<xmax>' + str(int(xmax)) + '</xmax>\n')
xml.write('\t\t\t<ymax>' + str(int(ymax)) + '</ymax>\n')
xml.write('\t\t</bndbox>\n')
xml.write('\t</object>\n')
xml.write('</annotation>')生成yolo格式的数据集(voc—>yolo)
xml文件
txt文件
import os
import xml.etree.ElementTree as ET
'''
标注文件xml转txt(voc to yolo),转换后添加labels文件,即数字序号对应的标签名
'''
classes = ['边异常', '角异常', '白色点瑕疵', '浅色块瑕疵', '深色点块瑕疵', '光圈瑕疵']
def convert(size, box): # 对数据进行归一化处理
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1 # bbox中心横坐标
y = (box[2] + box[3]) / 2.0 - 1 # bbox中心纵坐标
w = box[1] - box[0] # bbox宽
h = box[3] - box[2] # bbox高
x = x * dw
y = y * dh
w = w * dw
h = h * dh
if x >= 1:
x = 0.99
if y >= 1:
y = 0.99
if w >= 1:
w = 0.99
if h >= 1:
h = 0.99
return (x, y, w, h)
def convert_annotation(rootpath, xmlname):
xmlpath = rootpath + '/Annotations'
xmlfile = os.path.join(xmlpath, xmlname)
with open(xmlfile, 'r', encoding='UTF-8') as in_file:
txtname = xmlname[:-4] + '.txt' # 标注文件转为txt的文件名
# print(txtname) # 197_1_t20201119084916148_CAM1.txt
txtpath = rootpath + '/worktxt' # txt存放的文件路径
if not os.path.exists(txtpath):
os.makedirs(txtpath)
txtfile = os.path.join(txtpath, txtname)
with open(txtfile, 'w+', encoding='UTF-8') as out_file:
tree = ET.parse(in_file) # 将XML文档解析为元素树
root = tree.getroot() # 返回树的根元素
size = root.find('size') # 按标签名称或路径查找第一个匹配元素
w = int(size.find('width').text) # Text before first subelement, 获取图片的宽
h = int(size.find('height').text) # 获取图片的高
out_file.truncate() # 截断文件,无指定size则从当前位置起截断
for obj in root.iter('object'): # 创建树迭代器,按文档顺序循环遍历元素,返回具有匹配标签的元素
cls = obj.find('name').text # 获取标注的类别
if cls not in classes:
continue
cls_id = classes.index(cls) # 获取瑕疵类别的序号
# print(classes.index('边异常')) # 0
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text),
float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text)) # 获取瑕疵的标注位置
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
if __name__ == '__main__':
rootpath = './voc'
xmlpath = rootpath + '/Annotations'
list = os.listdir(xmlpath) # list:['172.xml', '14.xml', ...]
for i in range(0, len(list)):
path = os.path.join(xmlpath, list[i])
if ('.xml' in path) or ('.XML' in path):
convert_annotation(rootpath, list[i])
else:
print('not xml file', i)参考文章
批量修改XML标注文件标签(label)名称_SYGgogogo的博客-CSDN博客
目标检测常用数据集格式转化voc yolo coco_dejahu的博客-CSDN博客_常用数据集格式
YOLO数据格式说明与转换_lokvke的博客-CSDN博客_yolo数据格式
team-learning-cv/DefectDetection at master · datawhalechina/team-learning-cv · GitHub















 1358
1358











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









