






深度学习与金融风控
反欺诈生命周期
第一层设备与网络
- 代理检测
- IDC检测
- 模拟器/虚拟机检测
- 木马检测
第二层用户行为
- 注册行为
- 登录行为
- 交易行为
- 事件行为
- 时间间隔异常
第三层业务频次
- 注册频次
- 登录频次
- 交易频次
- 地域频次
- 时间间隔频次
第四层业务异常
- 注册异常
- 登录异常
- 交易异常
- 地域异常
- 时间段异常
第五层诈骗团伙图谱
- 羊毛党发现
- 代理池发现
- 羊毛党设备发现
- 肉鸡网络发现
- 跨应用欺诈团伙
反欺诈规则的缺点
反欺诈一般通过两种方式,一种是设定规则,另一种是通过算法。
规则在反欺诈实践中应用也较多,但是缺点也明显,主要表现为:
- 策略性较强,命中直接拒绝,而且黑名单本身的误伤性也较强;
- 无法给出用户的欺诈风险有多大;
- 未考虑用户从信用风险向欺诈风险的转移,尤其是在行业不景气时。
以上缺点机器学习可以进行有效的避免,如可计算用户的欺诈概率有多大,从而采取一定的措施争取客户,而不是直接拒绝,同时也可以通过模型计算用户从信用风险转移为欺诈风险的概率,从而金融机构可及时进行风险控制与准备。
深度学习风控场景
序列数据建模:代表算法LSTM
图谱建模:代表算法Word2Vec Node2Vec GCN
传统特征衍生:CNN XDeepFM
循环神经网络
(Recurrent Neural Network,RNN)通常应用在自然语言处理、语音识别等领域,是一个拥有对时间序列显示建模能力的神经网络。
代表场景是拥有顺序的序列数据:B卡,盗号检测,失联模型,文本分类
异常的行为隐藏在行为序列中,总会找到蛛丝马迹。我们把一个时间段内的所有行为按先后顺序给机器学习,在学习大量样本后,它就能找出其中的细微差别,这就是RNN时间序列算法对于金融的价值所在。
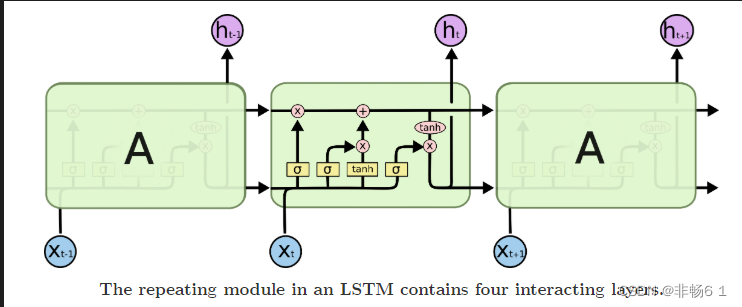
为什么要LSTM?
因为简单的RNN很容易就发生梯度消失和梯度爆炸,其中主要的原因是RNN中求导,引起的链式法则,对时间上的追溯,很容易发生系数矩阵的累乘,矩阵元素大于1,那么就会发生梯度爆炸;矩阵元素小于1,就会发生梯度消失。
LSTM通过门的控制,可以有效的防止梯度消失,但是依旧可能出现梯度爆炸的问题,所以训练LSTM会加入梯度裁剪(Gradient Clipping)。
- 记忆门
- 遗忘门
- 输出门
为什么要用BiLSTM
Bi代表双向。其实使用BiLSTM还是蛮有争议,因为人类理解时序信号的默认顺序其实是时间流逝的顺序,那么将时间倒叙的信号还有没有意义?有人说有,譬如说看一个人写一个字的具体笔画顺序其实不影响我们猜测这个字;有人说没有,倒着听一个人说话就不行。不管有什么争议,但是架不住BiLSTM在实际应用中效果十有八九好于LSTM,所以就用吧。
具体双向LSTM的结构其实相当简单,就是两个单向LSTM各自沿着时间和网络层向前传播,然后最后的输出拼接在一起。
rom torch import nn
class BLSTM(nn.Module):
"""
Implementation of BLSTM Concatenation for sentiment classification task
"""
def __init__(self, embeddings, input_dim, hidden_dim, num_layers, output_dim, max_len=40, dropout=0.5):
super(BLSTM, self).__init__()
self.emb = nn.Embedding(num_embeddings=embeddings.size(0),
embedding_dim=embeddings.size(1),
padding_idx=0)
self.emb.weight = nn.Parameter(embeddings)
self.input_dim = input_dim
self.hidden_dim = hidden_dim
self.output_dim = output_dim
# sen encoder
self.sen_len = max_len
self.sen_rnn = nn.LSTM(input_size=input_dim,
hidden_size=hidden_dim,
num_layers=num_layers,
dropout=dropout,
batch_first=True,
bidirectional=True)
self.output = nn.Linear(2 * self.hidden_dim, output_dim)
def bi_fetch(self, rnn_outs, seq_lengths, batch_size, max_len):
rnn_outs = rnn_outs.view(batch_size, max_len, 2, -1)
# (batch_size, max_len, 1, -1)
fw_out = torch.index_select(rnn_outs, 2, Variable(torch.LongTensor([0])).cuda())
fw_out = fw_out.view(batch_size * max_len, -1)
bw_out = torch.index_select(rnn_outs, 2, Variable(torch.LongTensor([1])).cuda())
bw_out = bw_out.view(batch_size * max_len, -1)
batch_range = Variable(torch.LongTensor(range(batch_size))).cuda() * max_len
batch_zeros = Variable(torch.zeros(batch_size).long()).cuda()
fw_index = batch_range + seq_lengths.view(batch_size) - 1
fw_out = torch.index_select(fw_out, 0, fw_index) # (batch_size, hid)
bw_index = batch_range + batch_zeros
bw_out = torch.index_select(bw_out, 0, bw_index)
outs = torch.cat([fw_out, bw_out], dim=1)
return outs
def forward(self, sen_batch, sen_lengths, sen_mask_matrix):
"""
:param sen_batch: (batch, sen_length), tensor for sentence sequence
:param sen_lengths:
:param sen_mask_matrix:
:return:
"""
''' Embedding Layer | Padding | Sequence_length 40'''
sen_batch = self.emb(sen_batch)
batch_size = len(sen_batch)
''' Bi-LSTM Computation '''
sen_outs, _ = self.sen_rnn(sen_batch.view(batch_size, -1, self.input_dim))
sen_rnn = sen_outs.contiguous().view(batch_size, -1, 2 * self.hidden_dim) # (batch, sen_len, 2*hid)
''' Fetch the truly last hidden layer of both sides
'''
sentence_batch = self.bi_fetch(sen_rnn, sen_lengths, batch_size, self.sen_len) # (batch_size, 2*hid)
representation = sentence_batch
out = self.output(representation)
out_prob = F.softmax(out.view(batch_size, -1))
return out_prob卷积神经网络
CNN中的卷积本质上就是利用一个共享参数的过滤器(kernel),通过计算中心像素点以及相邻像素点的加权和来构成feature map实现空间特征的提取,加权系数就是卷积核的权重系数。
场景:用于有拓扑关系的数据上
将可以求和的数据展开成feature-map的样子即可做卷积,从而实现特征交叉,挖掘更深层次的特征
深度学习另一个非常重要的领域——知识图谱
word2Vec
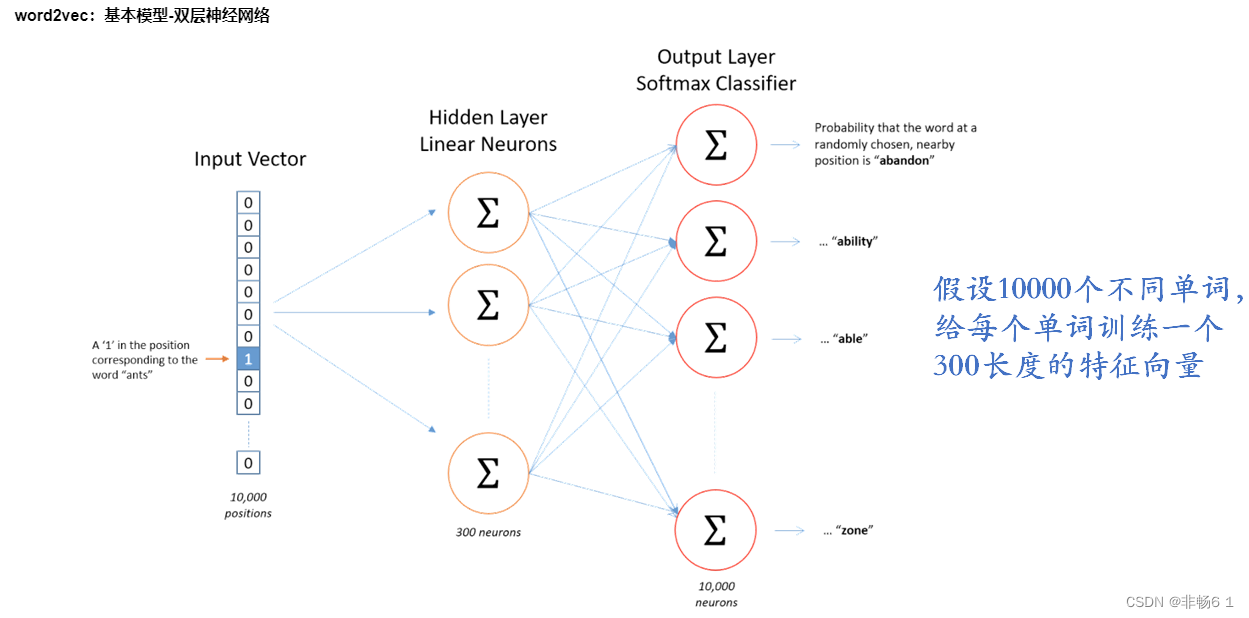
word2vec基本流程
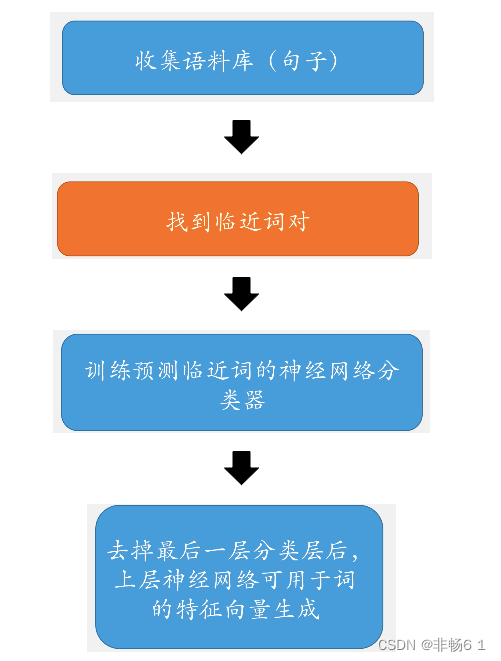
如何在图上找临近节点?如何生成节点序列?
1、广度优先遍历
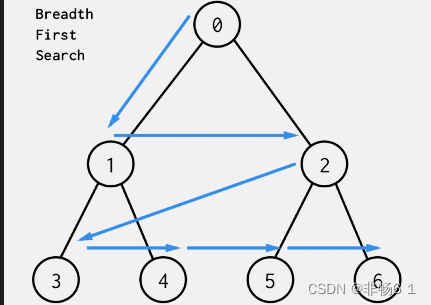
2、深度优先遍历
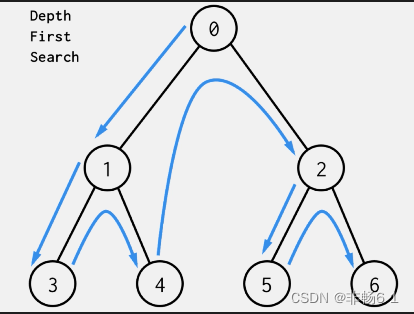
随机游走Random walk
随机漫步(Random Walk)思想最早由Karl Pearson在1905年提出,它是一种不规则的变动形式,在变动过程当中的每一步都是随机的。假如我们有下面这样一个小的关系网络。
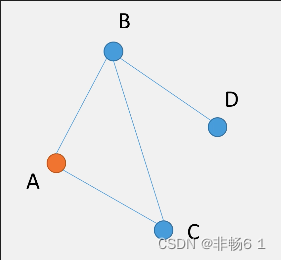
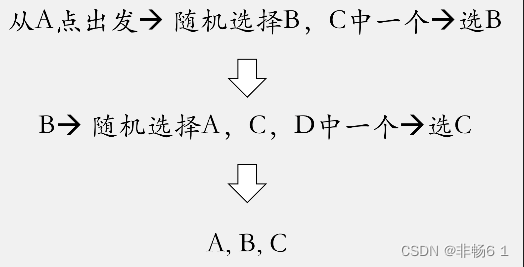
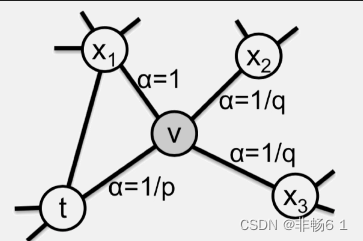
node2vec
可以改善random walk,更好地反映同质性与结构相似性
以下图为例,选择 t 为初始节点,并引入两个参数 p和q
返回概率参数(Return parameter)p,对应BFS,p控制回到原来节点的概率,如图中从t跳到v以后,有1/p的概率在节点v处再跳回到t
离开概率参数(In outparameter)q,对应DFS,q控制跳到其他节点的概率
















 3837
3837











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









