







 文章介绍了SIGIR2022会议上提出的GAR框架,该框架通过对抗训练解决了推荐系统中冷启动问题。传统方法在处理新物品推荐时效果不佳,GAR通过生成器和推荐器的对抗训练,使得冷门物品嵌入能与正常物品嵌入分布一致,避免了推荐效果的跷跷板效应。实验显示,GAR在多个数据集上优于协同过滤和图神经网络模型。
文章介绍了SIGIR2022会议上提出的GAR框架,该框架通过对抗训练解决了推荐系统中冷启动问题。传统方法在处理新物品推荐时效果不佳,GAR通过生成器和推荐器的对抗训练,使得冷门物品嵌入能与正常物品嵌入分布一致,避免了推荐效果的跷跷板效应。实验显示,GAR在多个数据集上优于协同过滤和图神经网络模型。
嘿,记得给“机器学习与推荐算法”添加星标
冷启动问题一直以来都是推荐系统中长期存在的一个棘手问题。传统的基于嵌入的推荐模型通过从历史交互中学习每个用户和物品的嵌入来提供推荐。因此,这种基于嵌入的推荐模型对于训练集中没有出现过的冷门物品表现很差。最常见的解决方案是为冷门物品从其内容特征中生成冷门嵌入。然而,由于内容特征和历史交互特征的分布不同,使得从内容生成的冷嵌入与之前的嵌入具有不同的分布。
在这种情况下,目前的冷启动方法面临着一个有趣的跷跷板(seesaw)现象,即当它改善了冷物品的推荐效果的同时,它就损害了正常物品的推荐效果;相反,当其提高了暖物品的性能的同时会损害冷物品的推荐效果。
基于此,本文提出了一个名为生成对抗式的推荐通用框架(GAR)。通过对生成器和推荐器进行对抗性训练,生成的冷门物品嵌入可以具有与常规嵌入相似的分布,甚至可以欺骗推荐器让其认为这两者的分布一致。同时,推荐器被微调以正确排列"假的"正常嵌入和真正的正常嵌入。因此,正常物品和冷门物品的推荐效果都不会相互影响,从而避免了跷跷板现象。
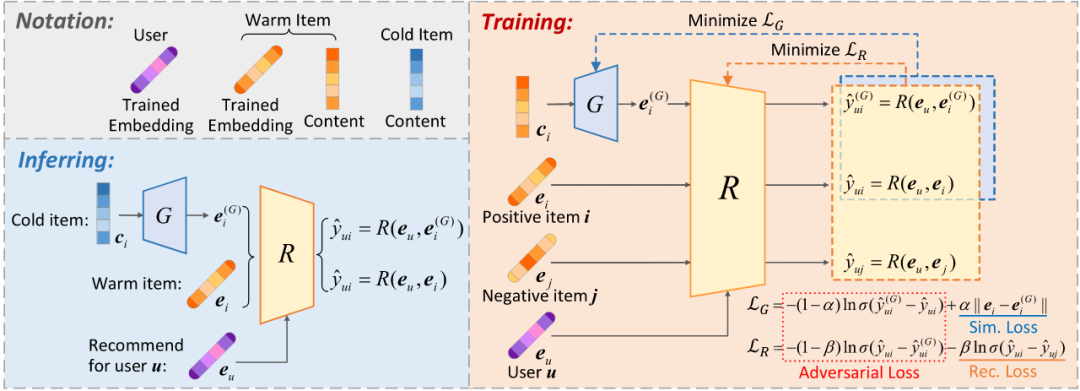
值得一提的是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 775
775

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









