







github地址:https://github.com/pytorch/vision/blob/master/torchvision/models/resnet.py
论文地址:https://arxiv.org/pdf/1512.03385.pdf
解决什么问题
Is learning better networks as easy as stacking more layers? An obstacle to answering this question was the notorious problem of vanishing/exploding gradients [1, 9], which hamper convergence(收敛) from the beginning.
This problem, however, has been largely addressed by normalized initialization [23, 9, 37, 13] and intermediate normalization layers [16], which enable networks with tens of layers to start converging for stochastic gradient descent (SGD) with backpropagation [22].
梯度消失和梯度爆炸的问题阻止了刚开始的收敛,这一问题通过初始化归一化和中间层归一化得到了解决。
a degradation problem has been exposed: with the network depth increasing, accuracy gets saturated (which might be unsurprising) and then degrades rapidly. Unexpectedly, such degradation is not caused by overfitting, and adding more layers to a suitably deep model leads to higher training error.
解决了收敛的问题后又出现了退化的现象:随着层数加深,准确率升高然后急剧下降。且这种退化不是由过拟合造成,且向网络中添加适当多层导致了更大的训练误差。
总结一下,随着网络深度的增加,模型精度并不总是提升,并且这个问题并不是由过拟合(overfitting)造成的,因为网络加深后不仅测试误差变高了,它的训练误差竟然也变高了。作者提出,这可能是因为更深的网络会伴随梯度消失/爆炸问题,从而阻碍网络的收敛。这种加深网络深度但网络性能却下降的现象被称为退化问题。
也就是说,随着深度的增加出现了明显的退化,网络的训练误差和测试误差均出现了明显的增长,ResNet就是为了解决这种退化问题而诞生的。
如何解决
Let us consider a shallower architecture and its deeper counterpart that adds more layers onto it. There exists a solution by construction to the deeper model: the added layers are identity mapping and the other layers are copied from the learned shallower model. The existence of this constructed solution indicates that a deeper model should produce no higher training error than its shallower counterpart.
于是作者提出了解决方案:在一个较浅的架构上添加更多层。 对于更深层次的模型:添加的层是恒等映射(identity mapping),其他层则从学习的浅层模型复制。在这种情况下,更深的模型不应该产生比其对应的较浅的网络更高的训练误差。
残差学习基本单元:
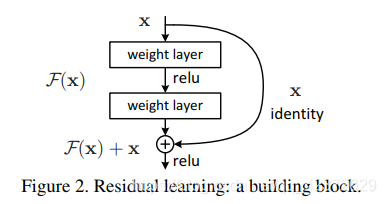
Formally, denoting the desired underlying mapping as H(x), we let the stacked nonlinear layers fit another mapping of F(x) := H(x)−x. The original mapping is recast into F(x)+x. We hypothesize that it is easier to optimize the residual mapping than to optimize the original, unreferenced mapping.
原先的网络输入x,希望输出H(x)。现在我们令H(x)=F(x)+x,那么我们的网络就只需要学习输出一个残差F(x)=H(x)-x。
假设输入为 x,有两层全连接层学习到的映射为H(x),也就是说这两层可以渐进(asymptotically)拟合H(x)。假设 H(x)与x维度相同,那么拟合 H(x) 与拟合残差函数 H(x)-x 等价,令残差函数 F(x)=H(x)-x,则原函数变为 F(x)+x ,于是直接在原网络的基础上加上一个跨层连接,这里的跨层连接也很简单,就是 将x的**恒等映射(Identity Mapping)**传递过去。
本质也就是不改变目标函数 H(x) ,将网络结构拆成两个分支,一个分支是残差映射F(x),一个分支是恒等映射x ,于是网络仅需学习残差映射F(x) 即可。
为何有效
- 自适应深度:网络退化问题就体现了多层网络难以拟合恒等映射这种情况,也就是说 H(x)难以拟合 x ,但使用了残差结构之后,拟合恒等映射变得很容易,直接把网络参数全学习到为0,只留下那个恒等映射的跨层连接即可。于是当网络不需要这么深时,中间的恒等映射就可以多一点,反之就可以少一点。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1813
1813











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









