






来自:CodeFuse

图片
论文链接:
https://arxiv.org/abs/2311.07989
Repo:
https://github.com/codefuse-ai/Awesome-Code-LLM
Twitter 大V转发:
https://twitter.com/_akhaliq/status/1724630901441585521
与此前已有的多篇综述不同,本文从跨学科视角出发,全面调研 NLP 与软件工程(SE)两个学科社区的工作,既覆盖以 OpenAI GPT 系列与 Meta LLaMA 系列为代表的生成式大模型与代码生成任务,也覆盖 CodeBERT 等专业代码小模型及代码翻译等其他下游任务,并重点关注 NLP 与 SE 的融合发展趋势。
本文分为技术背景、代码模型、下游任务、机遇挑战四部分。第一部分介绍语言模型的基本原理与常见训练目标,以及对 Transformer 基本架构的最新改进。第二部分介绍 Codex、PaLM 等通用大模型及 CodeGen、StarCoder 等专业代码模型,并包括指令微调、强化学习等 NLP 技术以及 AST、DFG、IR 等程序特征在代码模型中的应用。第三部分简单介绍 30+ 个代码下游任务,并列出常见数据集。第四部分给出当下代码大模型的机遇与挑战。
在2017年的论文 Attention Is All You Need 中,Transformer 的每一层定义如下:

图片
其中LN为层正则化(Layer Normalization),Attention为多头自注意力(MHA)子层,FFN为全连接(Feed-Forward Network)子层。
2019年,GPT-2将层正则化移到了每一子层的输入:
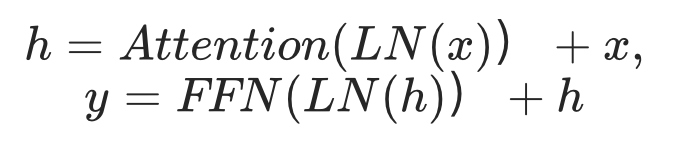
图片
后续 decoder-only 工作基本效仿了这一架构让训练更加稳定,在encoder-decoder模型方面,T5系列也采用了这一架构。
2021年,GPT-J 将自注意力与全连接层的顺序计算改为了并行以提高训练效率:
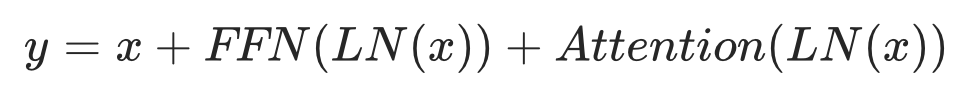
图片
由于自注意力无法区分输入词元间的位置关系,位置编码是 Transformer 架构的重要组成部分,其外推能力也决定了模型能处理的序列长度。
经典 Transformer 使用不可学习的余弦编码,加在模型底层的词向量输入上。GPT、BERT将其改为可学习的绝对位置编码,并沿用到了RoBERTa、BART、GPT-2、GPT-3等经典模型。Transformer-XL 与 XLNet 使用相对位置编码,根据自注意力中 k 与 q 的相对位置关系将对应可学习的向量加在 k 上,而 T5 则对此做了简化,将每个相对位置的编码作为可学习的标量加在 k 与 q 的点积结果上。
RoPE(Rotary Position Embedding)与 ALiBi(Attention with Linear Biases)是两种最新的位置编码技术。RoPE 将 q 与 k 乘以分块对角旋转矩阵来注入位置信息:
而 ALiBi 直接对注意力矩阵进行先行衰减:
因此,大模型中针对自注意力的加速优化通常出发点并不是注意力的计算过程,而是硬件的读写。MQA 就是基于此思想,在多头自注意力中让不同头之间共享 K 与 V,而每个头保留自己的 Q。此优化对训练速度几乎无影响,而对推理速度则直接提升 h 倍(h为注意力头数,如 BERT-large 为 16,GPT-3 175B为96)。此加速的来源是推理阶段所有词元需要自回归生成,而在生成过程中每一步的计算都涉及此前所有词元的 q 与 k。将这些 q 与 k从显存加载到GPU计算核心的过程构成了性能瓶颈。
至于GQA则顾名思义,是MHA与MQA的中间产品:
在主流大模型中,PaLM 使用 MQA,而 LLaMA 2 及其变体 Code LLaMA 使用 GQA。
另一相关技术是FlashAttention。该技术通过分布式计算中的 tiling 技术对注意力矩阵的计算进行优化。值得注意的是,与其他优化技术不同,FlashAttention 并不是近似方法,不会改变计算结果。
提起代码大模型,大部分人最熟悉的就当数 Codex 了。Codex 是基于 GPT-3 在 Python 数据上进行了 100B 词元自监督加训获得的模型。与 Codex 类似的还有对 PaLM 做了 39B 词元加训的 PaLM Coder,以及对 LLaMA 2做了超过 500B 词元加训的 Code LLaMA。
当然,大模型并不一定需要加训才能处理代码。如今的大模型预训练数据量动辄数万亿词元,其中就经常包括代码。例如,最常用的公开预训练数据集之一Pile就包括了95GB的代码,而BLOOM的预训练数据集ROOTS也包括了163GB、13种编程语言的代码。
通用大模型在HumanEval与MBPP上的性能:
自从GPT、BERT掀起预训练模型热潮后,软件工程领域就已有不少工作在代码上复现了这些模型。
与此前综述不同,我们不仅关注各模型的训练目标与数据等高层设计,也详细讨论了包括位置编码、注意力实现在内的技术细节,并总结进一图概览供大家查阅:
CodeBERT 是软工领域最有影响力的模型之一。它从 RoBERTa 初始化,用 MLM+RTD(RTD 是 ELECTRA 的预训练目标 Replaced Token Detection)的目标在代码上进行了训练。从上表可以看出,此后的多个 encoder 代码模型,包括 GraphCodeBERT, SynCoBERT, Code-MVP,都是基于 CodeBERT 开发。
在 NLP 中,BERT 预训练时还使用了 NSP(Next-Sentence Prediction)任务。虽然以 RoBERTa 为代表的后期工作大都认为该任务并没有帮助,但该任务的格式也为 encoder 预训练开拓了思路,在代码模型中催生出了很多变种。由于代码不同于自然语言,可以通过自动化方法抽取抽象语法树(AST)及注释等伴随特征,以 NSP 的格式进行对比学习成了一种常见方法。SynCoBERT 在代码-AST,注释-代码-AST等不同特征之间进行对比学习,DISCO则分别使用bug注入和保持语义的变换来构建正负样本,而Code-MVP则还额外加入了控制流(CFG)信息。
说起 decoder,大家第一个想到的当然就是 GPT 模式的自回归预训练了。确实,自从2020年以来已经出现了包括 GPT-C, CodeGPT, PolyCoder, CodeGen, PyCodeGPT, PanGu-Coder, CodeGeeX, Phi-1, CodeFuse, CodeShell, DeepSeek Coder 在内的众多自回归 decoder,大小从 100M 到 16B 不等。
但是,以 InCoder、FIM、SantaCoder、StarCoder 为代表的部分工作也探索了使用非传统自回归目标来训练 decoder 的可能。这些工作首先将输入数据转换为填空的形式:将整段输入随机切分为前缀-中部-后缀三段,并将其重新排序为前缀-后缀-中部(PSM 格式)或后缀-前缀-中部(SPM 格式),然后再将数据送进模型进行自回归训练。需要注意的是,在数据转换之后三段都参与自回归预训练。
在 NLP 中,以 BART 与 T5 为代表的 encoder-decoder 模型即使在如今的大模型时代也仍占据着一席之地,代码处理自然也少不了它们的身影。
由于编码器-解码器架构能够天然处理序列到序列建模问题,因此在代码模型的训练过程中除了 BART 的 DAE(Denoising Auto-Encoding)与 T5 的 Span Corruption 这两个标准任务,许多代码特有的特征也被用来进行序列到序列的预训练学习。例如 DOBF 就是用反混淆任务,来训练模型将混淆后的代码转换为原始代码。类似的,NatGen 提出了“自然化”任务,从人工转换产生的非自然代码来复原原始代码。
标识符预测也是代码预训练中的另一常见的任务。CodeT5 以序列标注的形式来在预训练过程中学习每个词元是否为标识符,而 SPT-Code 则直接以序列到序列生成的形式来预测方法名。
此外,随着 NLP 中 UL2 将自回归预训练与去噪预训练统一到了 encoder-decoder 架构下,最新的 encoder-decoder 代码模型 CodeT5+ 也采用了类似的预训练方式。
在 NLP 中,指令微调(instruction finetuning)与人类反馈强化学习(RLHF)在 ChatGPT 等对话模型的人类对齐过程中起到了必不可少的作用。指令微调通过在多样的指令数据集上训练模型来解锁跨任务泛化的能力,而强化学习则通过奖励模型的自动化反馈来训练模型向人类的偏好(如帮助性 Helpfulness,以及安全性 Safety 等)对齐。
这两项技术也在代码处理中得到了应用。WizardCoder 与 PanGu-Coder 2 都使用 NLP 中 WizardLM 模型提出的 Evol-Instruct 方法,用 ChatGPT 等模型来从现有的指令数据中进化出更多样的指令集,并用生成的指令来微调 StarCoder。OctoCoder 与 OctoGeeX 则没有使用大模型生成的指令,而是使用了 GitHub 上的 commit 记录及前后代码来作为指令微调 StarCoder 与 CodeGeeX。最近,蚂蚁集团开源的 MFTCoder 框架还在指令数据中显式加入了多种下游任务,来定点提升微调模型在这些任务上的性能。
而在强化学习方面,代码处理相较自然语言处理存在着天然优势 - 编译器可以代替人类来自动化地生成精准的反馈。CompCoder、CodeRL、PPOCoder、RLTF 等工作就利用了这一特性来微调 CodeGPT 或 CodeT5,PanGu-Coder 2 也将强化学习应用在了更大的 StarCoder 中。
在论文中,我们也罗列了部分任务的现有标准数据集:
这些数据集的网址链接都在 GitHub repo 中给出,而其他任务,尤其是单元测试生成、断言生成、代码反混淆等软件测试相关任务,目前还没有大规模的标准数据集,大语言模型在其中的应用也较少,是 NLP 与 SE 未来工作可以重点考虑的方向。














 1216
1216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









