






常见参数高效微调方法(Parameter-Efficient Fine-Tuning,PEFT)有哪些呢?主要是Prompt系列和LoRA系列。本文主要介绍P-Tuning v2微调方法。如下所示:
一.P-Tuning v2工作原理
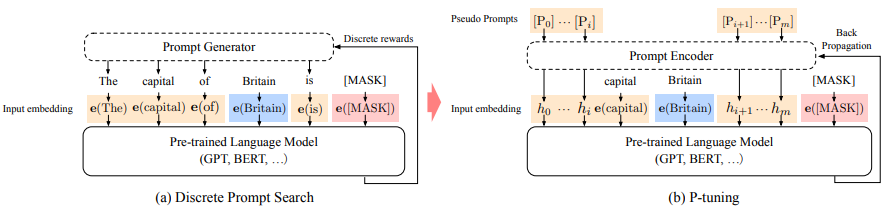
1.Hard/Soft Prompt-Tuning如何设计
提示工程发展经过了从人工或半自动离散空间的hard prompt设计,到采用连续可微空间soft prompt设计的过程,这样的好处是可通过端到端优化学习不同任务对应的prompt参数。
2.P-Tuning工作原理和不足
主要是将continuous prompt应用于预训练模型的输入层,预训练模型后面的每一层都没有合并continuous prompt。
一.P-Tuning v2工作原理1.Hard/Soft Prompt-Tuning如何设计 提示工程发展经过了从人工或半自动离散空间的hard prompt设计,到采用连续可微空间soft prompt设计的过程,这样的好处是可通过端到端优化学习不同任务对应的prompt参数。2.P-Tuning工作原理和不足 主要是将continuous prompt应用于预训练模型的输入层,预训练模型后面的每一层都没有合并continuous prompt。3.P-Tuning v2如何解决P-Tuning不足 P-Tuning v2把continuous prompt应用于预训练模型的每一层,而不仅仅是输入层。
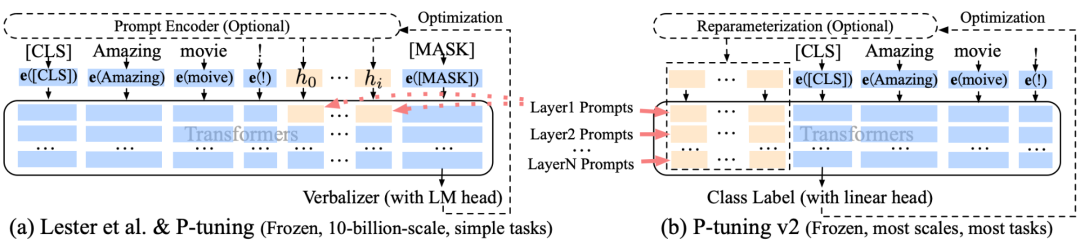
3.P-Tuning v2如何解决P-Tuning不足
P-Tuning v2把continuous prompt应用于预训练模型的每一层,而不仅仅是输入层。
一.P-Tuning v2工作原理1.Hard/Soft Prompt-Tuning如何设计 提示工程发展经过了从人工或半自动离散空间的hard prompt设计,到采用连续可微空间soft prompt设计的过程,这样的好处是可通过端到端优化学习不同任务对应的prompt参数。2.P-Tuning工作原理和不足 主要是将continuous prompt应用于预训练模型的输入层,预训练模型后面的每一层都没有合并continuous prompt。3.P-Tuning v2如何解决P-Tuning不足 P-Tuning v2把continuous prompt应用于预训练模型的每一层,而不仅仅是输入层。
二.P-Tuning v2实现过程
1.整体项目结构
源码参考文献[4],源码结构如下所示:
![二.P-Tuning v2实现过程1.整体项目结构 源码参考文献[4],源码结构如下所示:参数解释如下所示:(1)--model_name_or_path L:/20230713_HuggingFaceModel/20231004_BERT/bert-base-chinese:BERT模型路径(2)--task_name qa:任务名字(3)--dataset_name squad:数据集名字(4)--do_train:训练过程(5)--do_eval:验证过程(6)--max_seq_length 128:最大序列长度(7)--per_device_train_batch_size 2:每个设备训练批次大小(8)--learning_rate 5e-3:学习率(9)--num_train_epochs 10:训练epoch数量(10)--pre_seq_len 128:前缀序列长度(11)--output_dir checkpoints/SQuAD-bert:检查点输出目录(12)--overwrite_output_dir:覆盖输出目录(13)--hidden_dropout_prob 0.1:隐藏dropout概率(14)--seed 11:种子(15)--save_strategy no:保存策略(16)--evaluation_strategy epoch:评估策略(17)--prefix:P-Tuning v2方法执行代码如下所示:](https://img-blog.csdnimg.cn/img_convert/5ce610d5c08f8e9356d2d6cddd7f122e.png)
二.P-Tuning v2实现过程1.整体项目结构 源码参考文献[4],源码结构如下所示:参数解释如下所示:(1)--model_name_or_path L:/20230713_HuggingFaceModel/20231004_BERT/bert-base-chinese:BERT模型路径(2)--task_name qa:任务名字(3)--dataset_name squad:数据集名字(4)--do_train:训练过程(5)--do_eval:验证过程(6)--max_seq_length 128:最大序列长度(7)--per_device_train_batch_size 2:每个设备训练批次大小(8)--learning_rate 5e-3:学习率(9)--num_train_epochs 10:训练epoch数量(10)--pre_seq_len 128:前缀序列长度(11)--output_dir checkpoints/SQuAD-bert:检查点输出目录(12)--overwrite_output_dir:覆盖输出目录(13)--hidden_dropout_prob 0.1:隐藏dropout概率(14)--seed 11:种子(15)--save_strategy no:保存策略(16)--evaluation_strategy epoch:评估策略(17)--prefix:P-Tuning v2方法执行代码如下所示:
参数解释如下所示:
(1)--model_name_or_path L:/20230713_HuggingFaceModel/20231004_BERT/bert-base-chinese:BERT模型路径
(2)--task_name qa:任务名字
(3)--dataset_name squad:数据集名字
(4)--do_train:训练过程
(5)--do_eval:验证过程
(6)--max_seq_length 128:最大序列长度
(7)--per_device_train_batch_size 2:每个设备训练批次大小
(8)--learning_rate 5e-3:学习率
(9)--num_train_epochs 10:训练epoch数量
(10)--pre_seq_len 128:前缀序列长度
(11)--output_dir checkpoints/SQuAD-bert:检查点输出目录
(12)--overwrite_output_dir:覆盖输出目录
(13)--hidden_dropout_prob 0.1:隐藏dropout概率
(14)--seed 11:种子
(15)--save_strategy no:保存策略
(16)--evaluation_strategy epoch:评估策略
(17)--prefix:P-Tuning v2方法
执行代码如下所示:
2.代码执行流程(1)P-tuning-v2/run.py
(2)P-tuning-v2/tasks/qa/get_trainer.py
(3)P-tuning-v2/model/utils.py选择P-tuning-v2微调方法,返回BertPrefixForQuestionAnswering模型,如下所示:
(4)P-tuning-v2/model/question_answering.py(重点)
主要是
BertPrefixForQuestionAnswering(BertPreTrainedModel)
模型结构,包括构造函数、前向传播和获取前缀信息。
(5)P-tuning-v2/model/prefix_encoder.py(重点)
BertPrefixForQuestionAnswering(BertPreTrainedModel)
构造函数中涉及到前缀编码器
PrefixEncoder(config)
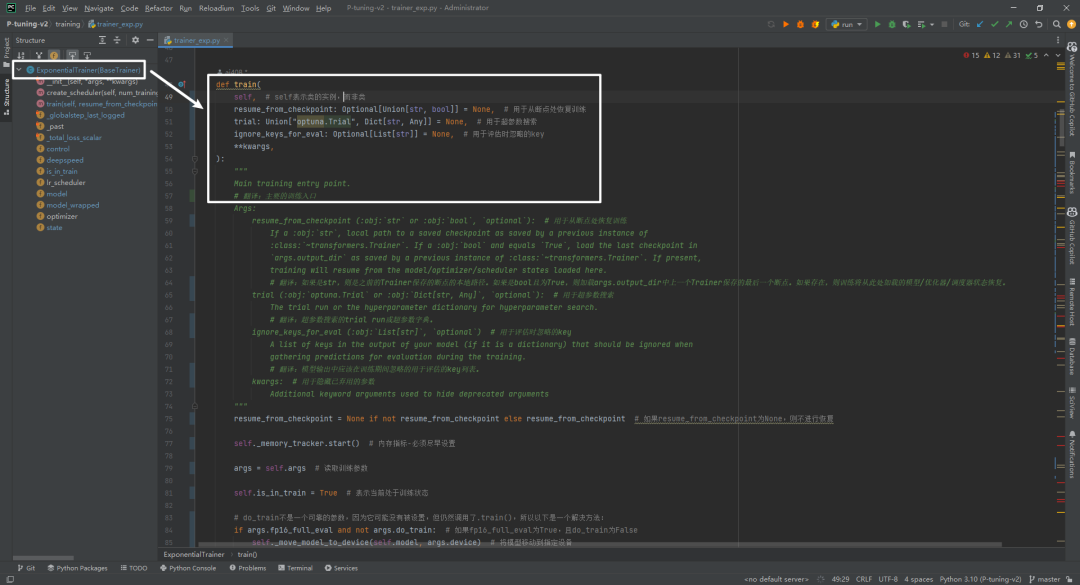
(6)P-tuning-v2/training/trainer_qa.py
继承关系为
QuestionAnsweringTrainer(ExponentialTrainer)->ExponentialTrainer(BaseTrainer)->BaseTrainer(Trainer)->Trainer
,最核心训练方法如下所示:
(4)P-tuning-v2/model/question_answering.py(重点)主要是BertPrefixForQuestionAnswering(BertPreTrainedModel)模型结构,包括构造函数、前向传播和获取前缀信息。(5)P-tuning-v2/model/prefix_encoder.py(重点)在BertPrefixForQuestionAnswering(BertPreTrainedModel)构造函数中涉及到前缀编码器PrefixEncoder(config)。(6)P-tuning-v2/training/trainer_qa.py继承关系为QuestionAnsweringTrainer(ExponentialTrainer)->ExponentialTrainer(BaseTrainer)->BaseTrainer(Trainer)->Trainer,最核心训练方法如下所示:
3.P-tuning-v2/model/prefix_encoder.py实现 该类作用主要是根据前缀prefix信息对其进行编码,假如不考虑batch-size,那么编码后的shape为(prefix-length, 2*layers*hidden)。假如prefix-length=128,layers=12,hidden=768,那么编码后的shape为(128,2*12*768)。
这里面可能会有疑问,为啥还要乘以2呢?因为past_key_values前半部分要和key_layer拼接,后半部分要和value_layer拼接,如下所示:
说明:代码路径为transformers/models/bert/modeling_bert.py->class BertSelfAttention(nn.Module)的forward()函数中。
4.P-tuning-v2/model/question_answering.py 简单理解,BertPrefixForQuestionAnswering就是在BERT上添加了PrefixEncoder,get_prompt功能主要是生成past_key_values,即前缀信息的编码表示,用于与主要文本序列一起输入BERT模型,以帮助模型更好地理解问题和提供答案。因为选择的SQuAD属于抽取式QA数据集,即根据question从context中找到answer的开始和结束位置即可。
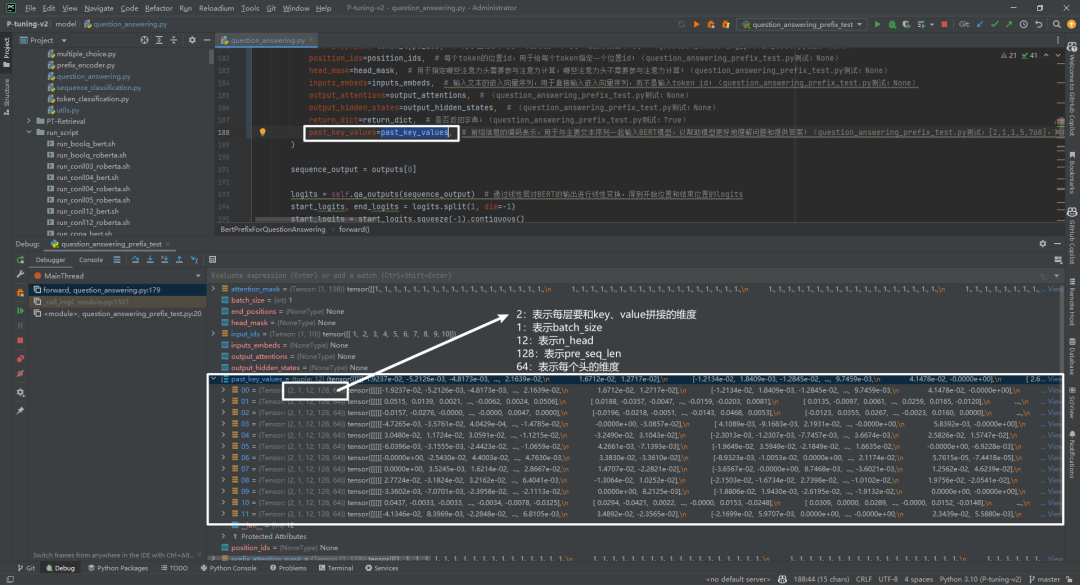
重点是
outputs = self.bert(past_key_values=past_key_values)
,将past_key_values传入BERT模型中,起作用的主要是
transformers/models/bert/modeling_bert.py->class BertSelfAttention(nn.Module)的forward()函数中
。接下来看下past_key_values数据结构,如下所示:
重点是outputs = self.bert(past_key_values=past_key_values),将past_key_values传入BERT模型中,起作用的主要是transformers/models/bert/modeling_bert.py->class BertSelfAttention(nn.Module)的forward()函数中。接下来看下past_key_values数据结构,如下所示:
5.BertSelfAttention实现 BERT网络结构参考附件1,past_key_values主要和BertSelfAttention部分中的key和value进行拼接,如下所示:
具体past_key_values和key、value拼接实现参考代码,如下所示:
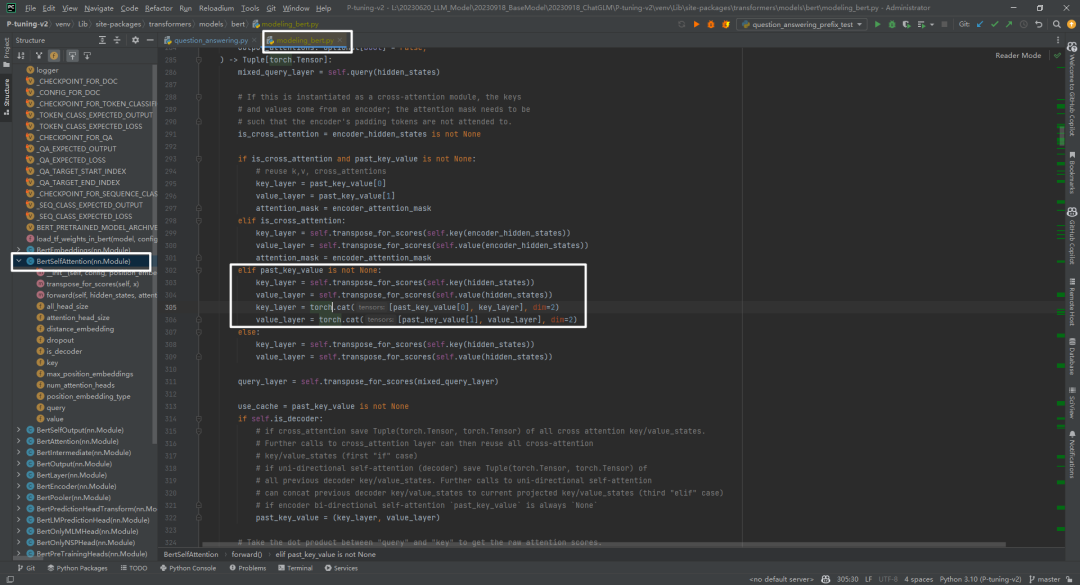
具体past_key_values和key、value拼接实现参考代码,如下所示: 经过BertSelfAttention部分后,输出outputs的shape和原始输入的shape是一样的,即都不包含前缀信息。
经过BertSelfAttention部分后,输出outputs的shape和原始输入的shape是一样的,即都不包含前缀信息。
附件1:BERT网络结构 打印出来BERT模型结构,如下所示:
BERT模型相关类结构在文件
D:\Python310\Lib\site-packages\transformers\models\bert\modeling_bert.py
中,如下所示:
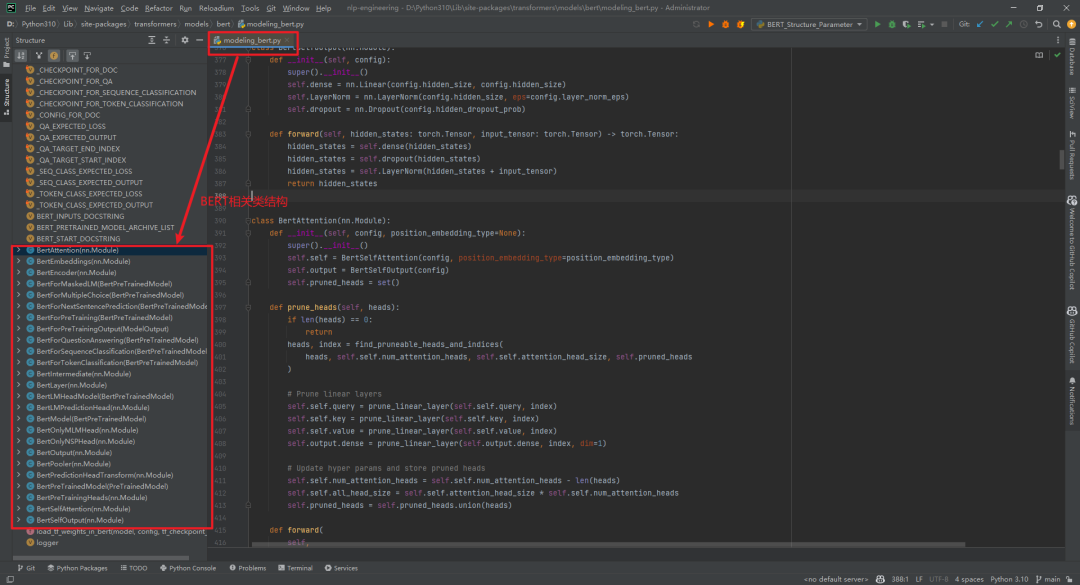
BERT模型相关类结构在文件D:\Python310\Lib\site-packages\transformers\models\bert\modeling_bert.py中,如下所示:
打个断点看下dataset数据结构如下所示:
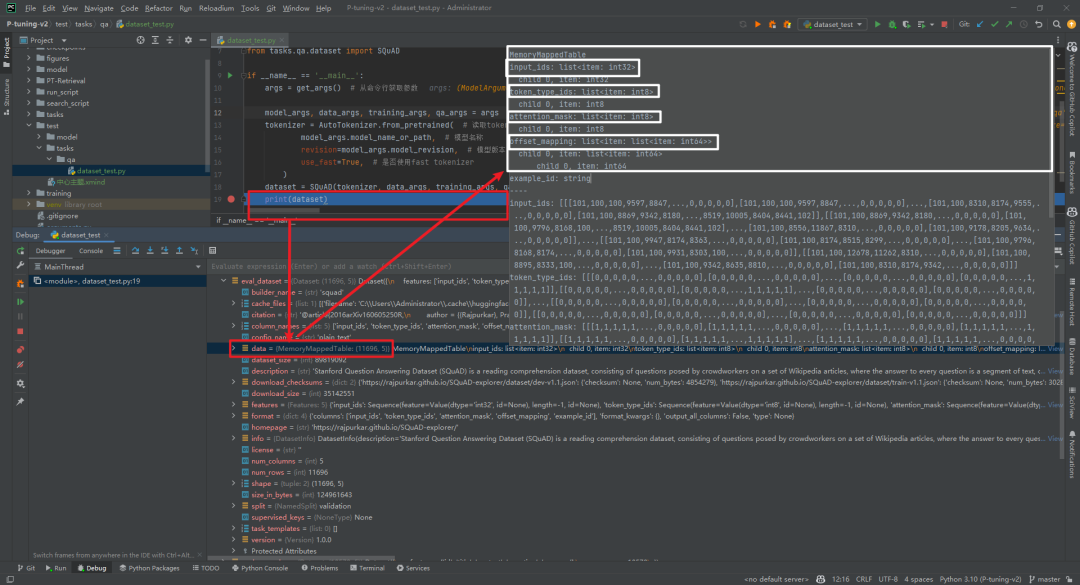
打个断点看下dataset数据结构如下所示:
觉得P-Tuning v2里面还有很多知识点没有讲解清楚,只能后续逐个讲解。仅仅一个P-Tuning v2仓库代码涉及的知识点非常之多,首要就是把Transformer和BERT标准网络结构非常熟悉,还有对各种任务及其数据集要熟悉,对BERT变体网络结构要熟悉,对于PyTorch和Transformer库的深度学习模型训练、验证和测试流程要熟悉,对于Prompt系列微调方法要熟悉。总之,对于各种魔改Transformer和BERT要了如指掌。
参考文献:[1]P-Tuning论文地址:https://arxiv.org/pdf/2103.10385.pdf[2]P-Tuning代码地址:https://github.com/THUDM/P-tuning[3]P-Tuning v2论文地址:https://arxiv.org/pdf/2110.07602.pdf[4]P-Tuning v2代码地址:https://github.com/THUDM/P-tuning-v2[5]BertLayer及Self-Attention详解:https://zhuanlan.zhihu.com/p/552062991[6]https://rajpurkar.github.io/SQuAD-explorer/[7]https://huggingface.co/datasets/squad















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









