







随着输入长度的增加,大型语言模型(LLMs)中的键值(KV)缓存需要存储更多的上下文信息以维持性能,这导致内存消耗和计算时间急剧上升。KV缓存的增长对内存和时间效率的挑战主要表现在两个方面:一是在处理长文本时,模型需要更多的内存资源来存储KV缓存,这不仅增加了硬件成本,还可能因内存限制而影响模型规模的扩展;二是在生成文本时,模型需要对KV缓存中的每个键值对进行注意力计算,随着缓存的增大,这个过程变得更加耗时,从而降低了模型的解码速度。
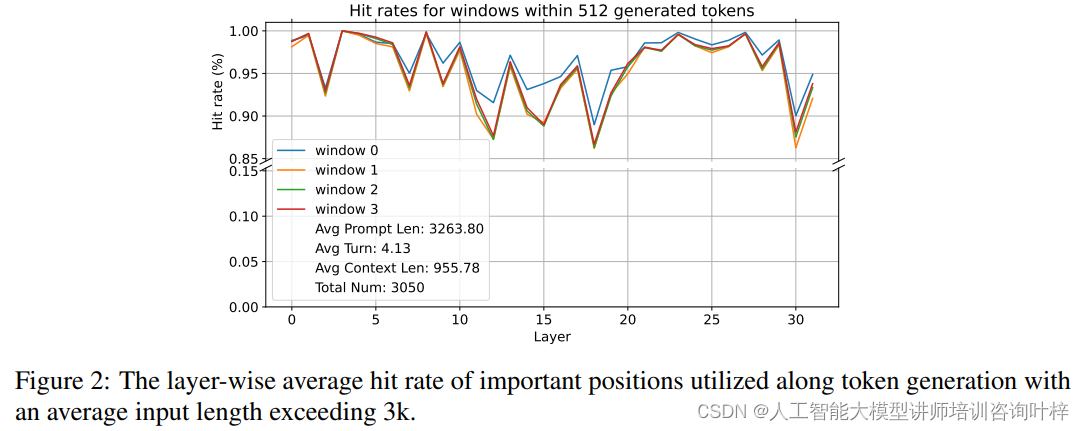
在深入分析大型语言模型(LLMs)的注意力机制时,研究者发现了一些关键模式,这些模式对于优化KV缓存至关重要。某些键在令牌生成期间始终吸引着模型的注意力,无论上下文的长度如何,这些“活跃”的键展现出稳定的高注意力权重。在长摘要和问答任务中,问题的位置(无论是在提示的开头还是结尾)对模型的注意力分配模式影响不大,显示出模型在处理长文本时的鲁棒性。研究者还发现注意力模式高度依赖于上下文,与用户的具体指令密切相关,这意味着不同的指令会引导模型关注不同的信息。
这些观察结果促成了SnapKV的开发,它是一种创新的KV缓存压缩方法。SnapKV的创新之处在于它提出了一种无需微调的压缩方法,通过观察模型在生成过程中的注意力分配模式,自动识别并压缩KV缓存中的关键信息。SnapKV通过“投票”机制选出每个注意力头关注的关键KV位置,并通过聚类算法保留这些关键特征周围的信息,从而在不牺牲准确性的前提下显著减少KV缓存的大小。这种方法不仅减少了计算开销,还提高了内存效率,使得模型在处理长文本时更为高效。SnapKV在解码速度上实现了3.6倍的提升,在内存效率上实现了8.2倍的提升,同时在多个长序列数据集上保持了与基线模型相当的性能。SnapKV还能够与现有的深度学习框架轻松集成,仅需少量代码调整,为长文本处理提供了一种实用的解决方案。
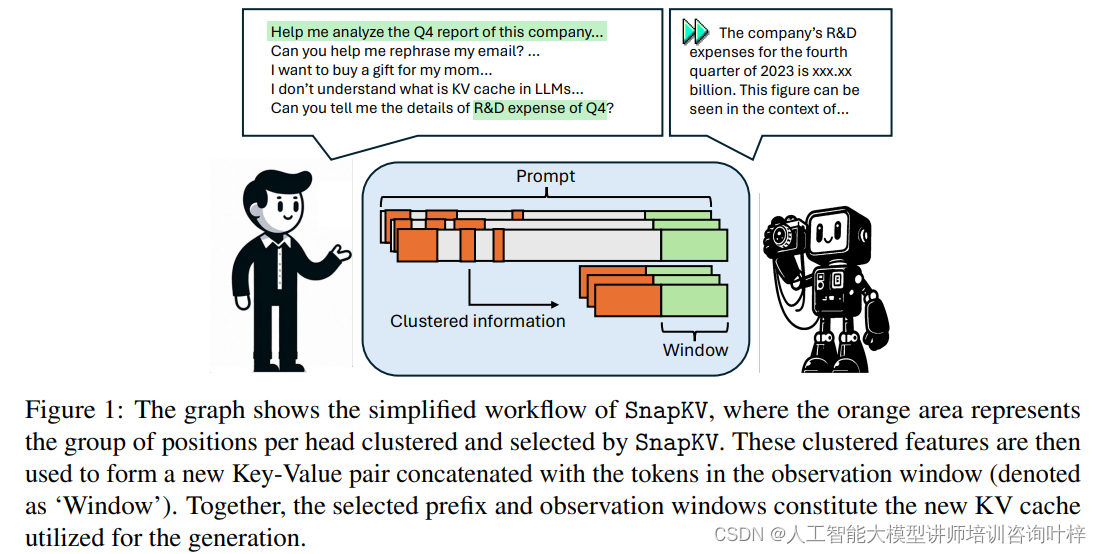
SnapKV 的核心思想是在生成过程中保持提示(prompt)的 KV 缓存数量恒定,从而显著减少长上下文 LLMs 的服务时间。这是通过识别和选择每个注意力头(attention head)最关键的注意力特征(attention features)来实现的,以此创建一个新的、更小的 KV 缓存。
实现步骤
SnapKV 的实现分为两个主要阶段:
-
投票选择重要特征(Voting for Important Previous Features):
- 利用定义好的投票过程(如公式1所示),基于观察窗口(observation window)——即提示的最后部分——来选择重要的特征。
- 通过分析发现,这些特征在整个序列生成过程中表现出显著的一致性,表明它们对后续生成至关重要。
- 此外,实施聚类算法以保留选定特征周围的特征,这有助于保留信息的完整性并避免丢失上下文。
-
更新和存储截断的键和值(Update and Store Truncated Key and Value):
- 将选定的特征与观察窗口的特征连接起来,这些特征包含了所有提示信息。
- 将连接后的 KV 缓存存储起来,以供后续生成使用,同时节省内存使用。
代码示例
def snap_kv(query_states, key_states, value_states, window_size, max_capacity_prompt, kernel_size):
bsz, num_heads, q_len, head_dim = query_states.shape
# 确保当前是处理提示阶段
assert key_states.shape[-2] == query_states.shape[-2]
if q_len < max_capacity_prompt:
return key_states, value_states
else:
# 计算观察窗口的查询和前缀上下文的键的注意力权重
attn_weights = compute_attn(query_states[..., -window_size:, :], key_states, attention_mask)
# 沿着查询维度对权重求和
attn_weights_sum = attn_weights[..., -window_size:, :-window_size].sum(dim=-2)
# 应用1D池化进行聚类
attn_cache = pool1d(attn_weights_sum, kernel_size=kernel_size, padding=kernel_size // 2, stride=1)
# 基于池化后的权重选择每个头的top-k索引,以识别重要位置
indices = attn_cache.topk(max_capacity_prompt - window_size, dim=-1).indices
# 扩展索引以匹配头维度进行聚集
indices = indices.unsqueeze(-1).expand(-1, -1, -1, head_dim)
# 根据选定的索引聚集压缩的过去键和值状态
k_past_compress = key_states[..., :-window_size, :].gather(dim=2, index=indices)
v_past_compress = value_states[..., :-window_size, :].gather(dim=2, index=indices)
k_obs = key_states[..., -window_size:, :]
v_obs = value_states[..., -window_size:, :]
# 将压缩后的过去键和观察窗口的键拼接在一起
key_states = torch.cat([k_past_compress, k_obs], dim=2)
# 将压缩后的过去值和观察窗口的值拼接在一起
value_states = torch.cat([v_past_compress, v_obs], dim=2)
return key_states, value_statessnap_kv函数接受查询状态query_states、键状态key_states、值状态value_states,以及其他参数如窗口大小window_size、最大提示容量max_capacity_prompt和池化核大小kernel_size。- 首先,检查是否处于处理提示的阶段,如果不是,则直接返回原始的键和值状态。
- 然后,计算观察窗口内查询和前缀上下文键之间的注意力权重
attn_weights。 - 对这些权重进行求和
attn_weights_sum,然后应用一维池化pool1d来聚类,以便选择重要的特征。 - 使用
topk方法根据池化后的权重选择每个头的重要位置indices。 - 根据这些索引聚集压缩后的键和值状态
k_past_compress和v_past_compress。 - 最后,将压缩的键和值状态与观察窗口的键和值状态拼接起来,形成新的键和值状态,这些状态将用于后续的生成过程。
SnapKV方法论包含两个主要阶段:首先是通过一个称为“投票”的过程来识别重要的先前特征,其次是更新并存储截断的键和值。
在第一阶段,SnapKV利用了一个观察窗口,这个窗口位于提示的末端,它的作用是捕捉模型在生成过程中所关注的关键特征。通过计算观察窗口中每个查询的注意力权重,并在所有注意力头上聚合这些权重,SnapKV能够突出显示被认为是最重要的前缀位置。这个过程称为投票,它帮助系统识别出那些在生成文本时需要特别关注的KV位置。
第二阶段中,SnapKV将这些选出的重要特征与观察窗口中的特征结合起来,形成一个新的键值对。这个新的键值对随后被用于生成过程,同时通过仅保留这些关键特征,系统能够显著减少所需的内存和计算资源。此外,为了保持信息的完整性并避免因过度压缩而导致的细节丢失,SnapKV采用了一种基于池化的聚类算法。这个算法通过池化层对信息进行细粒度的压缩,确保了在压缩KV缓存的同时,依然能够保留足够的上下文信息,从而维持模型的准确性。
SnapKV的实现是高效的,因为它只需要对现有的深度学习框架进行少量的代码调整。这意味着它可以轻松地集成到现有的系统中,而无需进行大规模的重构。在实验中,SnapKV显示出了卓越的性能,它不仅在解码速度上实现了显著的提升,还在内存效率上达到了大幅度的增强。这些改进使得SnapKV成为一个在处理长文本方面极具潜力的解决方案,特别是在需要处理大量输入序列的应用场景中,如聊天机器人、代理服务、文档处理等。SnapKV通过其创新的方法论,为长文本处理中的内存和时间效率问题提供了一个有效的解决方案。
在对SnapKV进行的实验中,研究团队采取了一系列严谨的测试,旨在评估该方法在不同模型和长文本数据集上的性能。实验的目的是验证SnapKV在减少计算和内存负担的同时,是否能够保持或甚至提升模型的生成质量和效率。
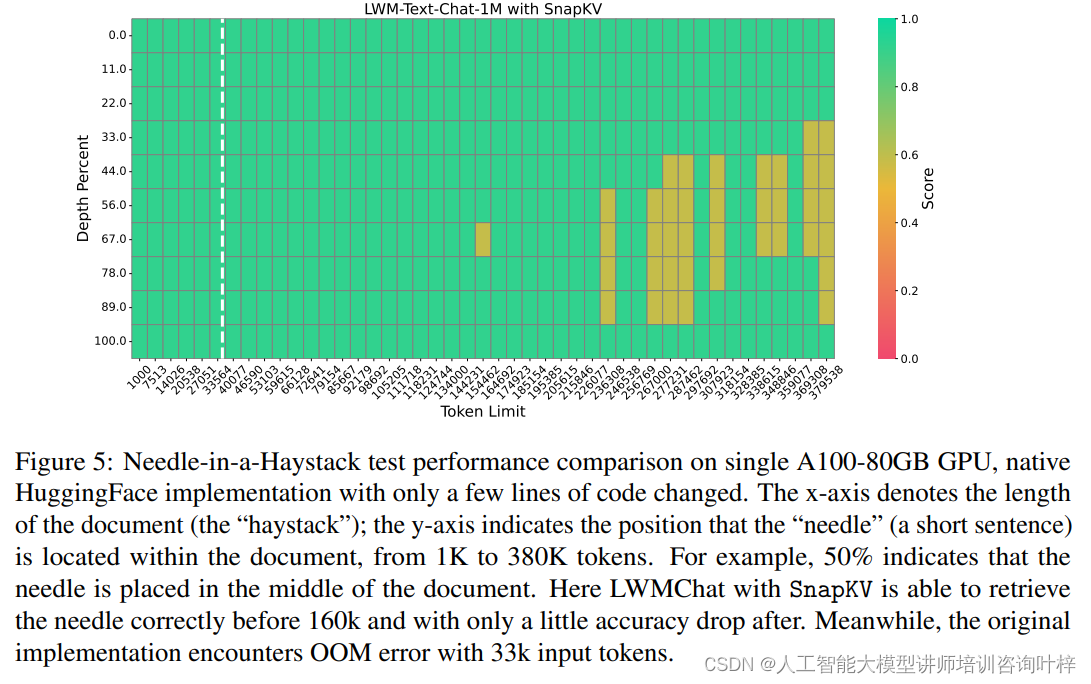
实验首先在LWM-Text-Chat-1M模型上进行了压力测试,这是当时最先进的模型之一,能够处理长达一百万个令牌的上下文。测试中,SnapKV展现了其算法效率,特别是在硬件优化方面。通过“Needle-in-a-Haystack”测试,即在长达380K令牌的文档中准确检索特定句子的能力,SnapKV证明了其在极端条件下处理长文本的能力,即便在极高的压缩比下也能保持精确性。
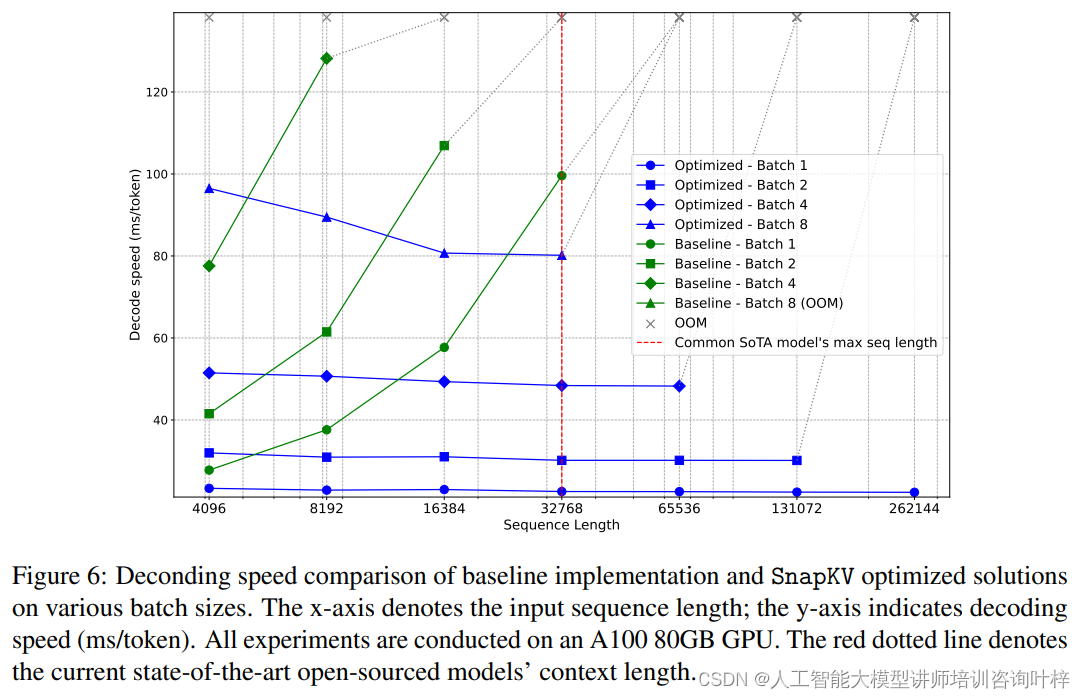
实验通过不同的批处理大小对LWM-Text-Chat-1M模型进行了解码速度和内存限制的基准测试。结果表明,SnapKV优化的模型在解码速度上保持了稳定,与输入序列长度的增加无关,这与基线实现形成了鲜明对比,后者的解码速度随输入长度的增加而指数级增长。SnapKV显著提高了模型处理长序列的能力,显著减少了内存消耗。
为了进一步验证SnapKV的有效性,研究团队还对Mistral-7B-Instruct-v0.2模型进行了消融研究,以理解池化技术对模型信息检索性能的影响。消融研究结果表明,通过池化增强了检索准确性,这可能是因为强大的注意力机制倾向于关注令牌序列的初始部分。
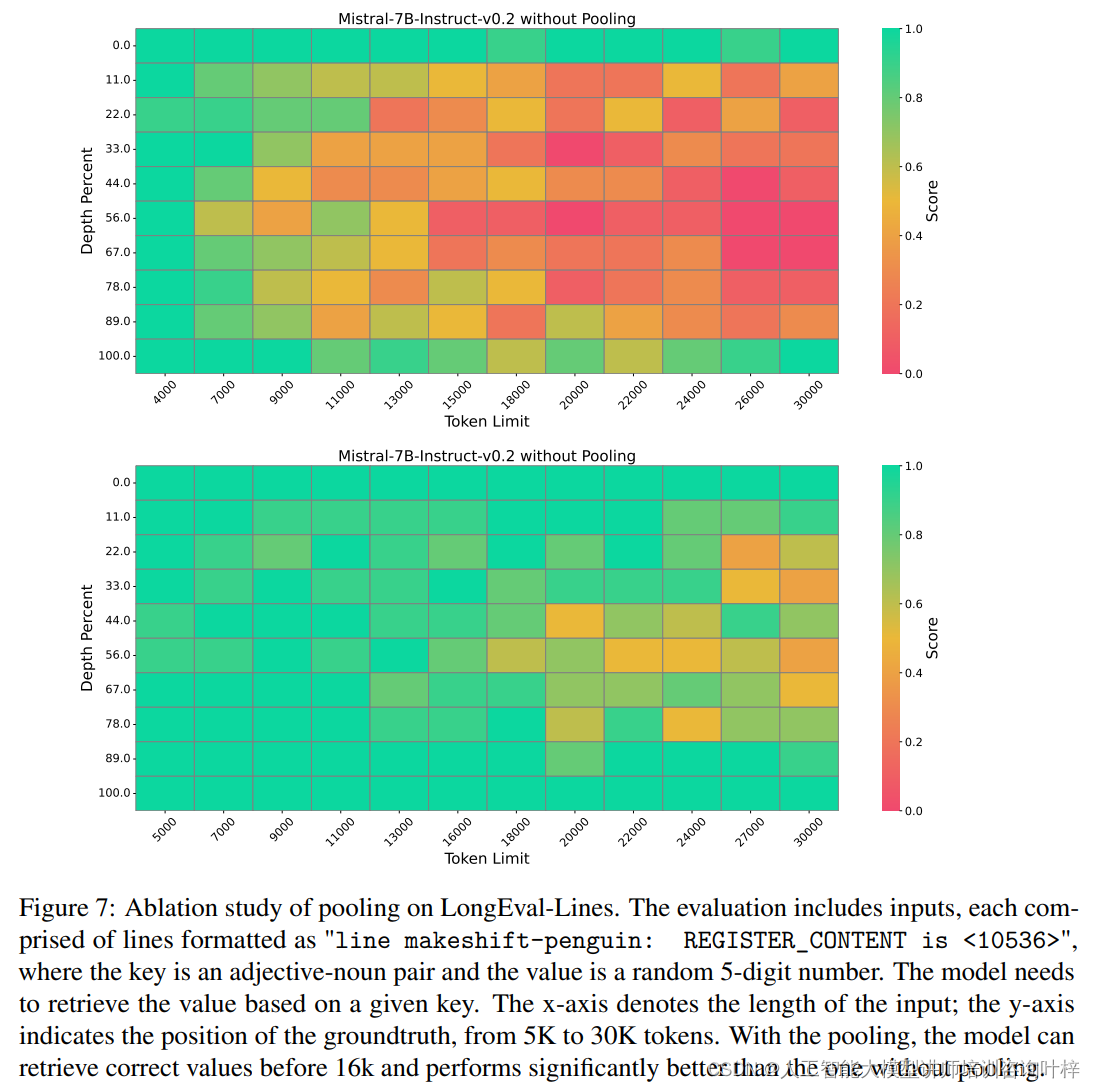
最后,实验使用了LongBench,这是一个多任务基准测试,旨在全面评估长文本理解能力。SnapKV在多个不同设置下进行了测试,包括压缩KV缓存到1024、2048和4096个令牌,并使用最大池化和观察窗口。测试结果显示,即使在压缩率高达92%的情况下,SnapKV与原始实现相比,在16个不同数据集上的性能下降可以忽略不计,某些情况下甚至超过了基线模型。
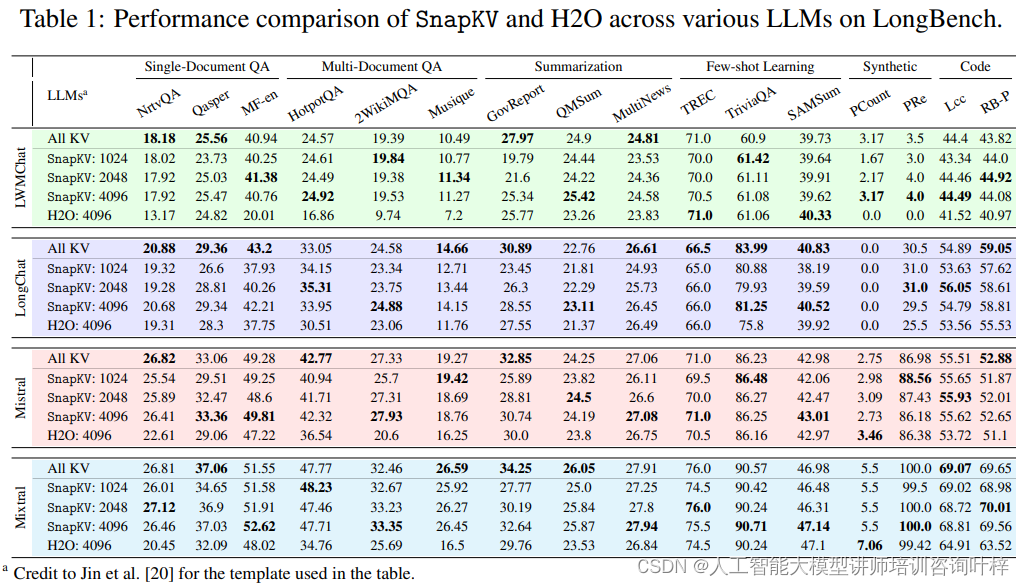
实验结果,SnapKV证明了其作为一种有效的KV缓存压缩方法,在保持大型语言模型处理长文本的能力的同时,显著提升了效率和减少了资源消耗。这些发现不仅证实了SnapKV的实用性,还为未来的研究和应用提供了有价值的见解。
SnapKV代码可在https://github.com/FasterDecoding/SnapKV上找到
论文链接:https://arxiv.org/abs/2404.14469



















 1940
1940

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











