






一篇非常基础非常基础的Agent博客
大型语言模型(LLMs)经过causal language modeling训练后,可以处理各种任务,但它们通常在逻辑、计算和搜索等基本任务上表现不佳。最糟糕的情况是,它们在某个领域(如数学)表现不佳,但仍然试图自行处理所有计算。
为了克服这一弱点,除了其他方法,可以将LLM集成到一个系统中,使其能够调用工具:这样的系统称为LLM Agent。
在本文中,我们将解释ReAct代理的内部工作原理,然后展示如何使用最近集成到LangChain中的ChatHuggingFace类来构建它们。最后,我们将对比几个开源LLM与GPT-3.5和GPT-4。
LLM Agent的定义非常广泛:LLM Agent是所有利用LLM作为引擎并可以根据环境产生的observation产生action的系统。它们可以使用感知⇒反思⇒行动循环的多个迭代来完成任务,并经常通过规划或知识管理系统进行增强以提高性能。
在这里,我们将重点放在ReAct代理上。ReAct是一种构建代理的方法,基于“reasoning”和“acting”这两个词的连接。在提示词中,会包含模型可以使用哪些工具,并要求它“一步一步”地思考(也称为思维链行为),以规划和执行下一个行动以达到最终答案。
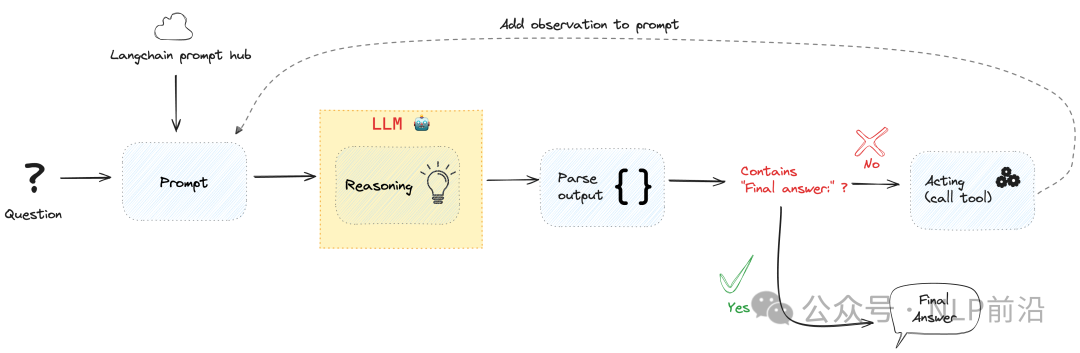
图片
上面的图看起来非常高级,但背后的原理其实非常简单。
在下面这个colab notebook中:使用 Transformers 库实现了一个简单的工具代理。
LLM 在循环中被调用,其中包含一个基本的提示词。
然后可以解析LLM的输出:
如果它包含字符串‘Final Answer:’,循环结束并打印答案,
否则,LLM应该输出一个工具调用:你可以解析这个输出以获取工具名称和参数,然后使用这些参数调用该工具。然后将此工具调用的输出附加到提示中,并使用这些扩展信息再次调用LLM,直到它有足够的信息最终提供问题的最终答案。
例如,当回答问题:1:23:45 有多少秒时,LLM 的输出可能是这样的。
由于此输出不包含字符串'Final Answer:',它在调用一个工具:因此我们解析此输出并获取工具调用参数:使用参数{"time": "1:23:45"} 调用工具convert_time。运行此工具调用返回{'seconds': '5025'}。因此我们将整个这段文字追加到提示词中。
现在的新提示词是(一个略微更详细的版本):
我们再次调用LLM,使用这个新提示词。鉴于它可以访问观察中调用结果的工具,LLM现在很可能会输出:
任务已完成!
一般来说,运行LLM引擎的代理系统中困难的部分包括:
从提供的工具中选择一个能够帮助实现预期目标的工具:例如,当被问到“大于30,000的最小质数是多少?”时,代理可以使用搜索工具进行调用,但这并不会有所帮助。
以严谨的参数格式调用工具:例如,当尝试计算一辆汽车在10分钟内行驶3公里的速度时,必须调用计算器工具来将距离除以时间:即使你的计算器工具接受JSON格式的调用:{”tool”: “Calculator”, “args”: “3km/10min”},也存在许多陷阱,例如:
拼写错误工具名称:“calculator”或“Compute”都跟工具名对不上
给出参数的名称而不是它们的值:“args”: “distance/time”
非标准化的格式:“args”: "3km in 10minutes”
高效地提取和利用前面观察到的信息,无论是初始背景还是使用工具后返回的观察结果。
说白了,一种就是模型能吐出来一个action,action_input,可能会出现模型吐出来的工具名可能跟实际的工具名对不上,或者参数名不对,或者参数值不标准。另外一种就是模型可能吐不出有效的action,对结果帮助不大
那么,一个完整的代理系统设置会是什么样子呢?
创建ChatModel并为其提供工具的代码非常简单,您可以在Langchain文档中查看所有类说明
你可以通过给 chat_model 提供 ReAct 风格的提示和工具来将其转化为一个代理。
并且代理将处理输入:
我们希望衡量开源LLM作为通用推理代理的表现。因此,我们选择需要使用逻辑和基本工具(计算器和互联网搜索)的问题。最终数据集是从其他3个数据集中抽取的样本的组合:
用于测试互联网搜索能力:我们从HotpotQA中选择了一些问题:这原本是一个检索数据集,但可以用于一般性问题回答,可以访问互联网。一些问题最初需要结合来自各种来源的信息:在我们的设置中,这意味着执行几个步骤的互联网搜索来结合结果。
对于计算器的使用,我们添加了来自GSM8K的问题:这个数据集测试小学数学能力,完全可以通过正确利用4种运算符(加、减、乘、除)来解决。
我们还从GAIA中挑选了一些问题,这是一个对通用人工智能助理来说非常困难的基准测试。原始数据集中的问题可能需要许多其他不同的工具,比如代码解释器或pdf阅读器:我们精选了不需要其他工具而只需搜索和计算器的问题。
评估是使用基于Prometheus提示格式的GPT-4作为打分模型。代码使用以下仓库
评测的几个英文模型,具体的就不贴了,结果如下:
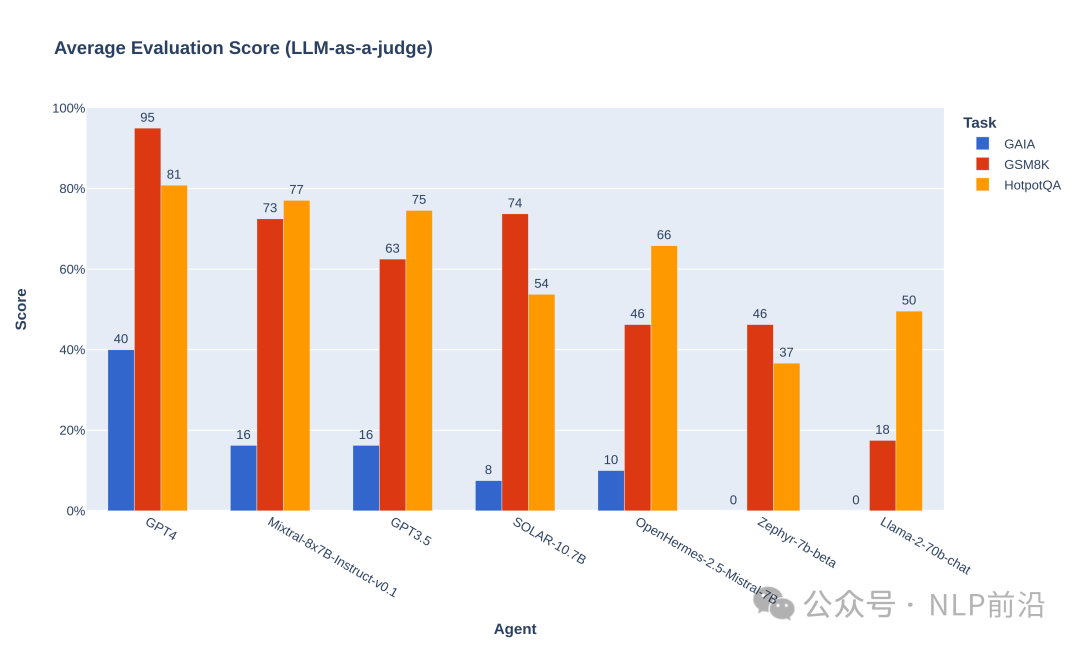
图片
简单结果看就是llama2-70b比较菜,在agent场景,mixtral 7b*8略优于gpt3.5















 3182
3182

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









