







最终,清华大学评估了25个主流的LLM在上述8个任务上的表现来评估各大模型作为Agent的最终得分。结果如下:
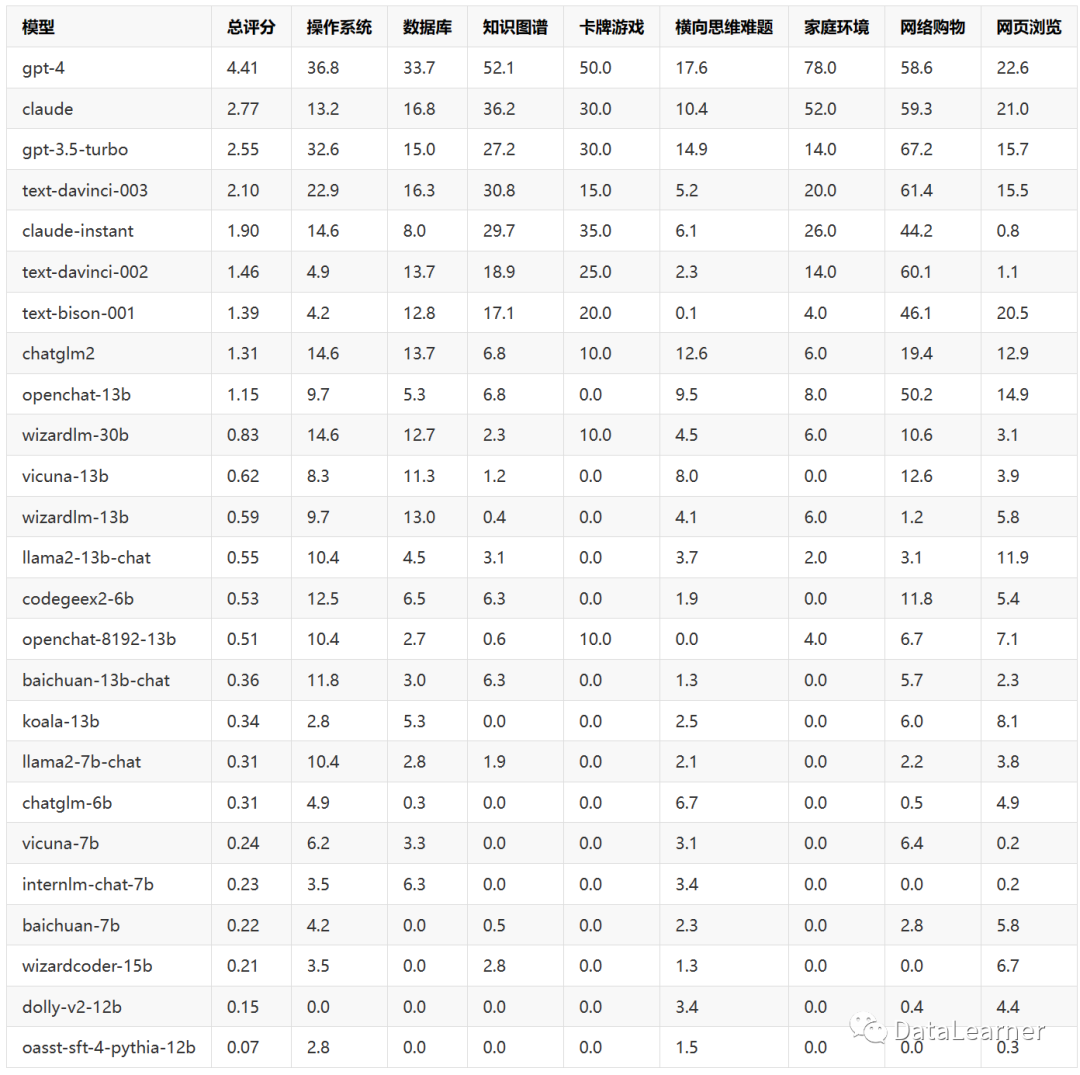
从上面的评测结果,我们也可以看出几个非常重要的结论:
- 商业顶级模型(如GPT-4)展现出在复杂环境中完成代理任务的强大能力,它们能够理解指令并进行多轮交互。这显示了LLM作为代理的潜力。
- 但是,目前开源模型与商业模型之间还存在显著的差距,开源模型在AgentBench上普遍表现较弱。这提示开源LLM的代理能力仍有提升空间。
- 不同环境有不同的挑战,如操作系统和数据库考察编码能力,知识图谱需要复杂推理,网页浏览需要处理庞大inputs。不同模型之间也存在明显的优劣。
- 一些共性问题影响了当前模型的表现,如多轮一致性、动作有效性等。这些也是未来的研究方向。
- 代码训练确实能增强编程相关环境的表现,但可能以牺牲其他能力为代价。模型的训练方式需要针对目标任务进行优化。
- 国产模型中,ChatGLM2-6B的综合得分最高,也是开源模型最高得分,但也低于谷歌的模型(text-bison-001)
- 开源模型大多数综合得分不足1分,而GPT-4的得分则超过4分,达到4.41分!ChatGLM-6B第一代与BaiChuan-7B的表现都很差,
上述结论都是基于表的数据分析得到,例如,通过对两个规模相近的模型chatglm2和codegeex2-6b在AgentBench(agentbench.com.cn)上的表现,可以看出代码训练的价值。其中,codegeex2-6b经过代码训练,在操作系统和数据库两个编程相关环境上明显优于chatglm2。但在需要逻辑推理的横向思维难题上,codegeex2-6b的表现下降。
下图展示了几个模型的对比结果:
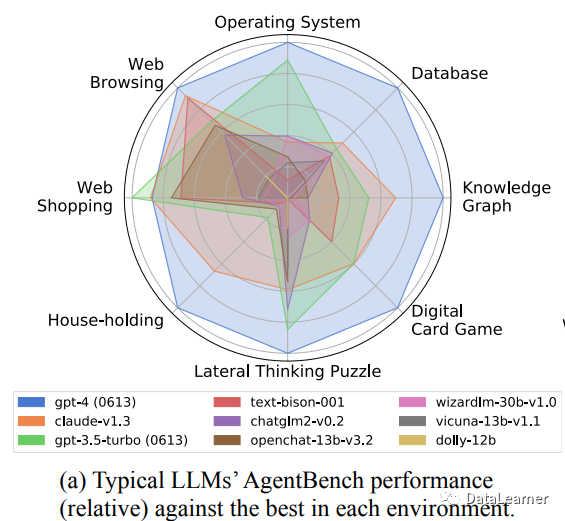
GPT-4几乎像全能战士一样,超越所有模型!


















 648
648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











