






最近,又有一家机构AI2(Allen Institute for AI)开源了一个LLM:OLMo,它的英文全称就叫Open Language Model。相比之前开源的大模型,OLMo的独特之处是完全开源,除了训练的模型,OLMo还开源了训练数据,训练代码以及模型评估代码。换句话说,只要你有GPU卡,再基于OLMo开源的数据和代码,就可以自己快速从零训练一个自己的LLM。

图片
除了数据,代码和模型,OLMo还直接公开了训练模型的日志:
博客:https://blog.allenai.org/olmo-open-language-model-87ccfc95f580
代码:GitHub - allenai/OLMo: Modeling, training, eval, and inference code for OLMo
数据:GitHub - allenai/dolma: Data and tools for generating and inspecting OLMo pre-training data.
论文:https://arxiv.org/abs/2402.00838
模型:https://huggingface.co/allenai/OLMo-7B
评估:https://github.com/allenai/OLMo-Eval
微调:https://github.com/allenai/open-instruct
日志:https://wandb.ai/ai2-llm/OLMo-7B/reports/OLMo-7B--Vmlldzo2NzQyMzk5
OLMo的训练数据Dolma是一个开放的数据集,包含3万亿个来自不同类型网络内容、学术出版物、代码、书籍和百科资料的词汇。Dolma不仅完全开源,而且同时也公开了构建数据集的工具包。
OLMo目前开源的模型主要有三个规模:
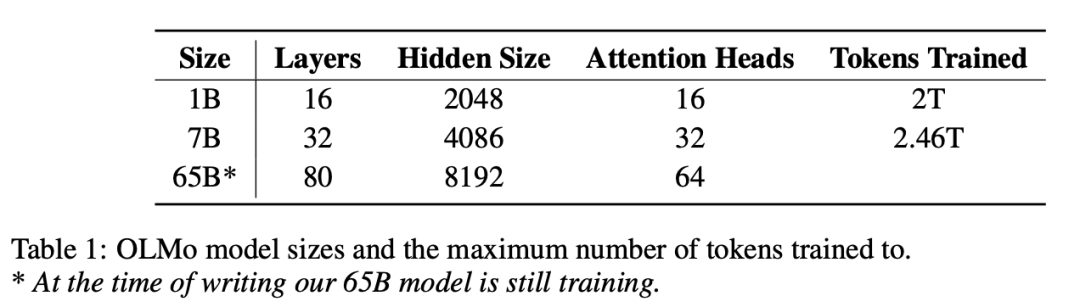
图片
其中65B的模型还在训练中,目前开源的最大模型是OLMo 7B:
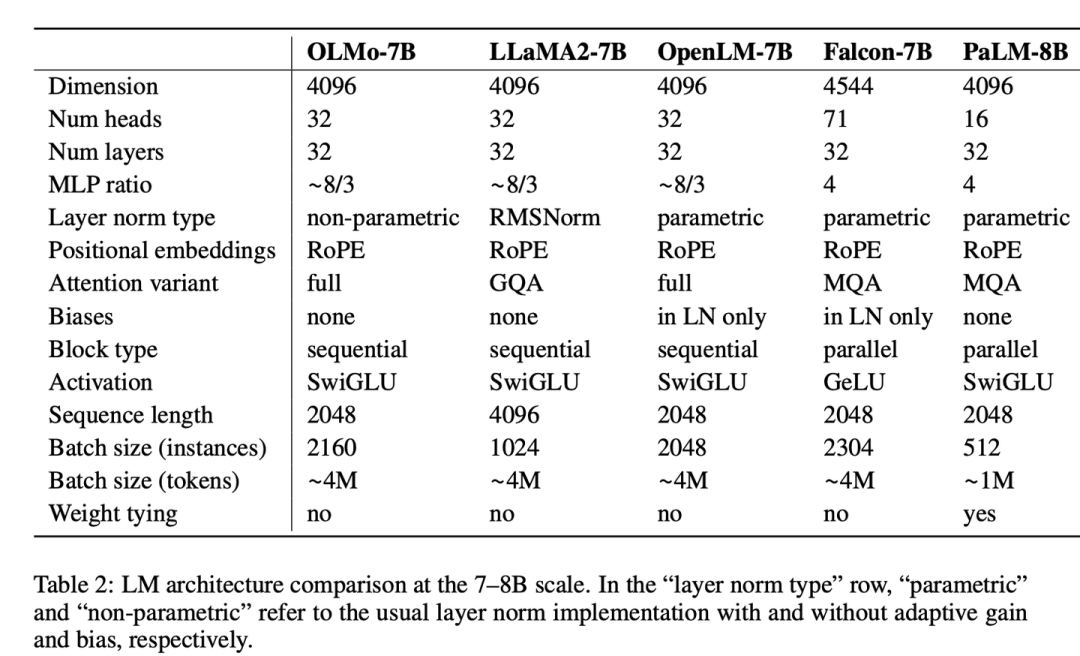
图片
OLMo 7B在大部分的评测上和Meta开源的Llama 2 7B相当:
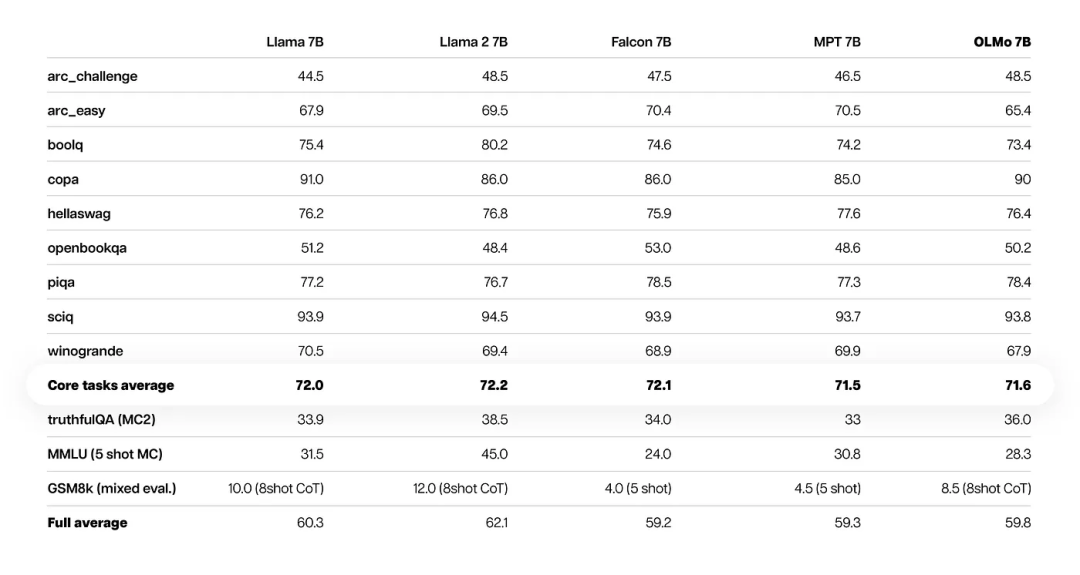
图片
除了预训练模型,OLMo 7B还提供了对应的微调版本OLMo 7B Instruct:
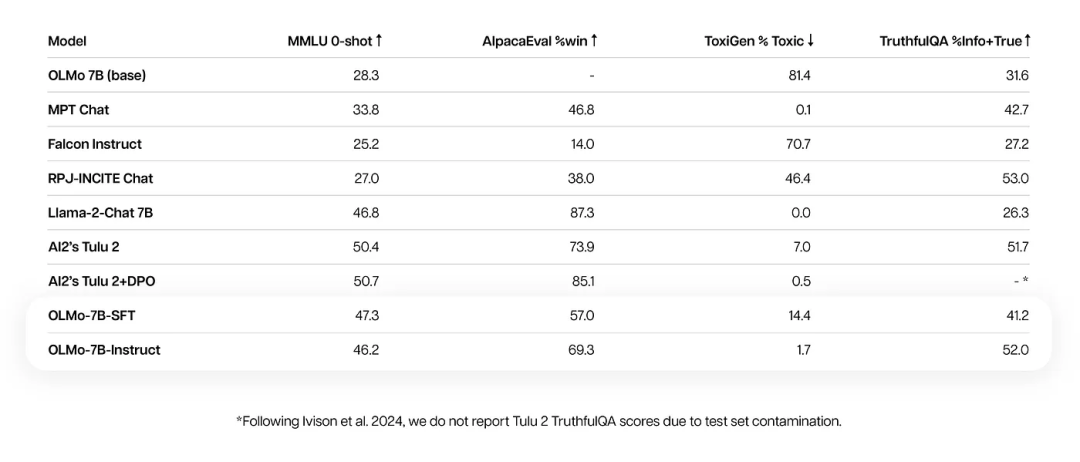
图片
虽然目前AI2开源的OLMo在效果上并没有那么惊艳,但是OLMo是完全的开源,对于LLM的入门选手,OLMo可能是一个快速的开始。而且AI2还会持续开源,OLMo只是一个开始:
This release is just the beginning for OLMo and the framework. Work is already underway on different model sizes, modalities, datasets, safety measures, and evaluations for the OLMo family. Our goal is to collaboratively build the best open language model in the world, and today we have taken the first step.
未来,开源是大势所趋。















 331
331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









