







 超级会员免费看
超级会员免费看
与早期的预训练语言模型相比,大语言模型需要更多的训练数据,这些数据需要涵盖广泛的内容范围。多领域、多源化的训练数据可以帮助大模型更加全面地学习真实世界的语言与知识,从而提高其通用性和准确性。根据其内容类型进行分类,这些语料库可以划分为:网页、书籍、维基百科、代码以及混合型数据集。
通用网页数据
网页是大语言模型训练语料中最主要的数据来源,包含了丰富多样的文本内容,例如新闻报道、博客文章、论坛讨论等,这些广泛且多元的数据为大语言模型深入理解人类语言提供了重要资源。下面介绍重要的网页数据资源。
通用网页数据,首先介绍面向各种语言(主要以英文为主)的通用网页数据集合。
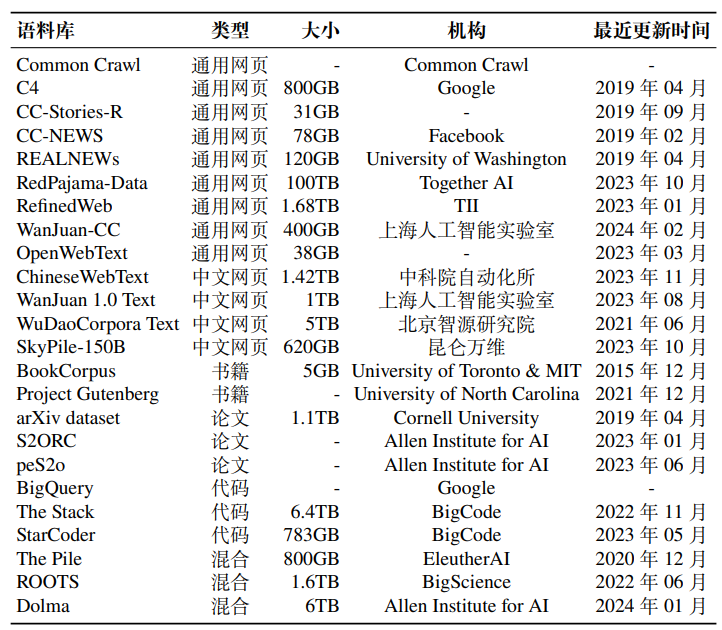
Common Crawl,该数据集是一个规模庞大的、非结构化的、多语言的网页数据集,其时间跨度很长,从 2008 年至今一直在定期更新,包含原始网页数据、元数据和提取的文本数据等,总数据量达到 PB 级别。由于这个数据集规模过于庞大,现有的研究工作主要提取其特定时间段或者符合特殊要求的子集进行使用,后文也将介绍多个基于 Common Crawl 的网页数据集。值得注意的是,该数据集内部充斥着大量的噪声和低质量数据,在使用前必须进行有效的数据清洗,以确保数据质量和准确性,常用的自动清洗工具有 CCNet 等。
C

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 1797
1797

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











