






转载自:AI科研技术派
强烈推荐做时间序列预测的伙伴,多多关注这个潜力方向:大模型+时间序列。随着大模型的广泛应用,该领域发展迅速。
为帮助大家掌握大模型时代时间序列预测的研究方法,今天给大家分享58篇必读论文,原文和代码都有。
这些文章主要代表了该领域的2大主流研究方向,一是如何用大模型做时间序列预测的任务,本次给大家整理了5种方法,比如时间序列-文本对齐、基于Prompt的方法等等。二则是训练一个时间序列领域专属的大模型。
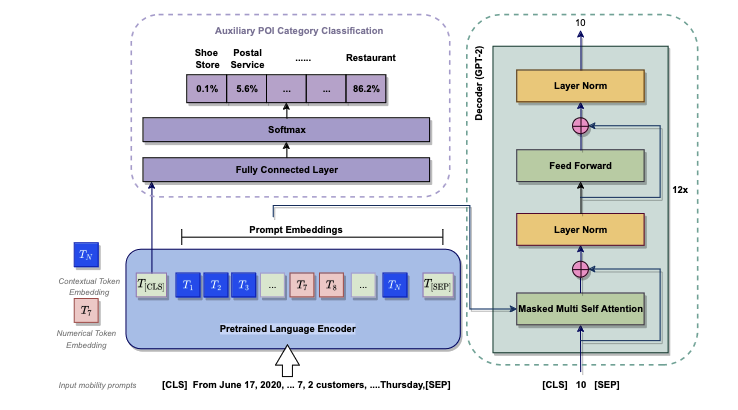
Leveraging Language Foundation Models for HumanMobility Forecasting
「简述」 在本文中,作者提出了一种新的管道,利用语言基础模型进行时序模式挖掘,例如人类流动性预测任务。例如,在预测兴趣地点(POI)客户流量的任务中,通常从历史日志中提取访问次数,并且仅使用数值数据来预测访问者流量。在本研究中,我们直接在自然语言输入上执行预测任务,该输入包括各种信息,如数值和上下文语义信息。引入特定的提示将数字时间序列转换为句子,以便可以直接应用现有的语言模型。我们设计了一个AuxMobLCast管道来预测每个POI中的访问者数量,将辅助POI分类任务与编码器-解码器架构集成在一起。本研究为所提出的auxmoblcast管道在移动预测任务中发现顺序模式的有效性提供了经验证据。
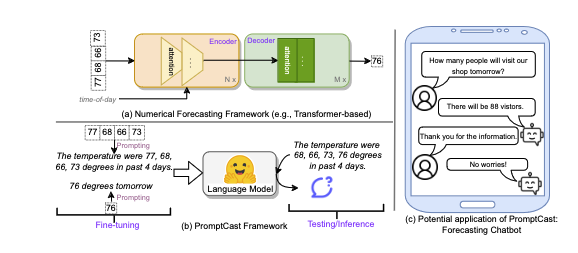
PromptCast: A New Prompt-based Learning Paradigm for Time Series Forecasting
「简述」 本文从一个全新的角度研究了时间序列预测问题。在现有的SOTA时间序列表示学习方法中,预测模型采用数值序列作为输入,yield值作为输出。现有的SOTA模型主要基于transformer体系结构,并使用多种编码机制进行修改,以结合历史数据周围的上下文和语义。在本文中,作者从基于提示的自然语言建模的范式来研究时间序列的表示学习。受预训练语言基础模型成功的启发,我们提出了一个问题,即这些模型是否也可以用于解决时间序列预测。因此,我们提出了新的预测范式:基于提示的时间序列预测(PromptCast)。在这个新颖的任务中,数字输入和输出被转换成提示符。为了支持和促进这项任务的研究,我们还提出了一个大型数据集(PISA),其中包括三个现实世界的预测场景。我们评估了不同的基于SOTA数字的时间序列预测方法和语言生成模型(如Bart),单步和多步预测设置的基准结果表明,基于提示的语言生成模型的时间序列预测是一个很有前途的研究方向。
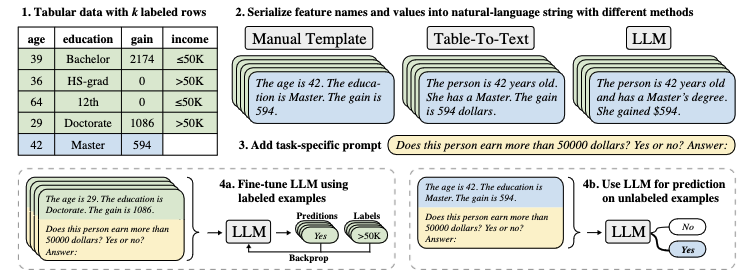
TabLLM: Few-shot Classification of Tabular Data with Large Language Models
「简述」 作者通过将表格数据序列化为自然语言字符串,以及对分类问题的简短描述来提示大型语言模型。在少数镜头设置中,使用一些标记示例微调大型语言模型。我们评估了几种序列化方法,包括模板、表到文本模型和大型语言模型。尽管它简单,但发现该技术在几个基准数据集上优于先前基于深度学习的表格分类方法。在大多数情况下,即使是零镜头分类也能获得非平凡的性能,说明了该方法利用大型语言模型中编码的先验知识的能力。
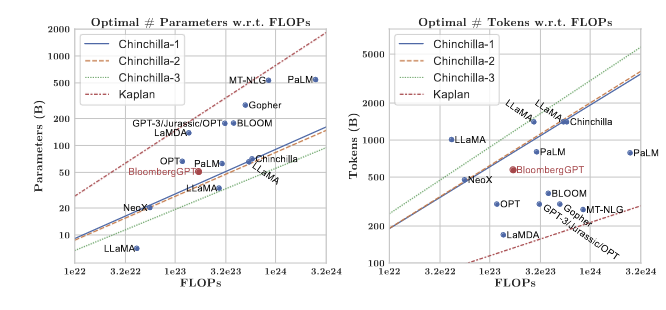
BloombergGPT: A Large Language Model for Finance
「简述」 在这项工作中,作者提出了BloombergGPT,这是一个500亿参数的语言模型,它是在广泛的金融数据上训练的。基于彭博广泛的数据源构建了3630亿个令牌数据集,这可能是迄今为止最大的领域特定数据集,并从通用数据集中增加了3450亿个令牌。在标准LLM基准测试、开放金融基准测试和一套最准确地反映预期使用情况的内部基准测试上验证BloombergGPT。
The Wall Street Neophyte: A Zero-Shot Analysis of ChatGPT Over MultiModal Stock Movement Prediction Challenges
「简述」 。在本文中,作者对ChatGPT在多模式股票运动预测方面的能力进行了广泛的零shot分析,涉及三个推文和历史股票价格数据集。研究结果表明,ChatGPT是一个“华尔街新手”,在预测股票走势方面成功有限,因为它不仅表现不如最先进的方法,而且不如使用价格特征的线性回归等传统方法。
Large Language Models are Few-Shot Health Learners
Where Would I Go Next? Large Language Models as Human Mobility Predictors
Large Language Models for Spatial Trajectory Patterns Mining
Large Language Models Are Zero-Shot Time Series Forecasters
Utilizing Language Models for Energy Load Forecasting
Large Language Models as General Pattern Machines
AudioLM: a Language Modeling Approach to Audio Generation
「简述」 AudioLM将输入音频映射到离散标记序列,并将音频生成转换为该表示空间中的语言建模任务。我们展示了现有的音频标记器如何在重建质量和长期结构之间提供不同的权衡,并且作者提出了一种混合标记化方案来实现这两个目标。也就是说,利用预先在音频上训练的蒙面语言模型的离散激活来捕获长期结构,并利用神经音频编解码器产生的离散代码来实现高质量的合成。通过对大量原始音频波形的语料库进行训练,AudioLM学会了在给定短提示的情况下生成自然和连贯的延续。当训练语音时,没有任何文本或注释,AudioLM生成语法和语义上似乎合理的语音延续,同时还保持说话人的身份和看不见的说话人的韵律。

AUDIOGEN: TEXTUALLY GUIDED AUDIO GENERA TION
「简述」 作者提出了一种混合不同音频样本的增强技术,驱动模型内部学习分离多个源。我们策划了10个包含不同类型音频和文本注释的数据集,以处理文本音频数据点的稀缺。为了更快的推断,我们探索了多流建模的使用,允许使用更短的序列,同时保持相似的比特率和感知质量。我们应用无分类器引导来提高文本的依从性。
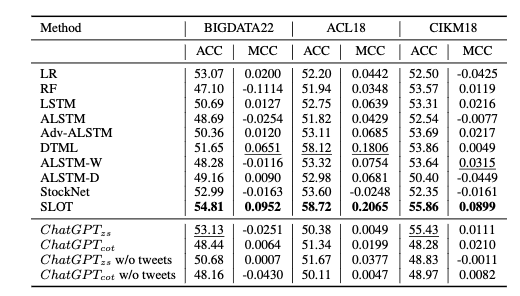
TEXT-TO-ECG: 12-LEAD ELECTROCARDIOGRAMSYNTHESIS CONDITIONEDONCLINICALTEXTREPORT
「简述」 作者提出了一个文本到ECG的任务,其中文本输入用于产生ECG输出。然后,我们首次提出了auto - tte,这是一种以临床文本报告为条件的自回归生成模型,用于合成12导联心电图。将我们的模型与文本到语音和文本到图像的其他代表性模型的性能进行了比较。

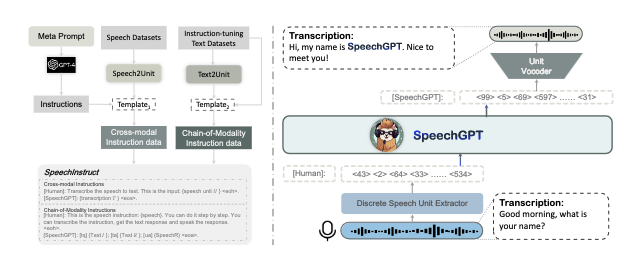
SpeechGPT:Empowering Large Language Models with Intrinsic Cross-Modal Conversational Abilities
「简述」 在这篇论文中,作者提出了SpeechGPT,一种具有内在跨模态对话能力的大型语言模型,能够感知和生成多模型内容。通过离散语音表示,我们首先构建了一个大规模的跨模态语音指令数据集SpeechInstruct。此外,采用了三阶段训练策略,包括modality adaptation pretraining,cross model speech instruction finetuning 和chain of modality instruction finetuning。
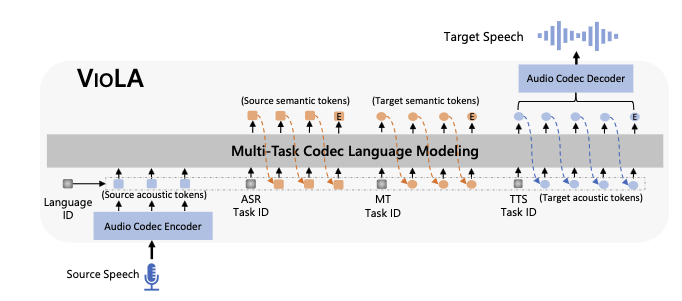
VIOLA: Unified Codec Language Models for Speech Recognition, Synthesis, and Translation
「简述」 最近的研究表明,在不同模态的不同任务中,模型架构、训练目标和推理方法有很大的收敛。在本文中,作者提出了VIOLA,一个单一的自回归变压器解码器网络,它统一了涉及语音和文本的各种跨模任务,如语音到文本、文本到文本、文本到语音和语音到语音任务,作为一个条件编解码器语言模型任务,通过多任务学习框架。为了实现这一点,首先使用离线神经编解码器将所有语音转换为离散的令牌(类似于文本数据)。通过这种方式,所有这些任务都被转换为基于记号的序列转换问题,这些问题可以用一个条件语言模型自然地处理。进一步将任务id (TID)和语言id (LID)集成到所提出的模型中,以增强处理不同语言和任务的建模能力。
Temporal Data Meets LLM Explainable Financial Time Series Forecasting
AudioPaLM: A Large Language Model That Can Speak and Listen
MODELING TIME SERIES AS TEXT SEQUENCE: A FREQUENCY-VECTORIZATION TRANSFORMER FOR TIME SERIES FORECASTING
TIME SERIES MODELING AT SCALE: A UNIVERSAL REPRESENTATION ACROSS TASKS AND DOMAINS
DeWave: Discrete EEG Waves Encoding for Brain Dynamics to Text Translation
UNIAUDIO: AN AUDIO FOUNDATION MODEL TOWARD UNIVERSAL AUDIO GENERATION
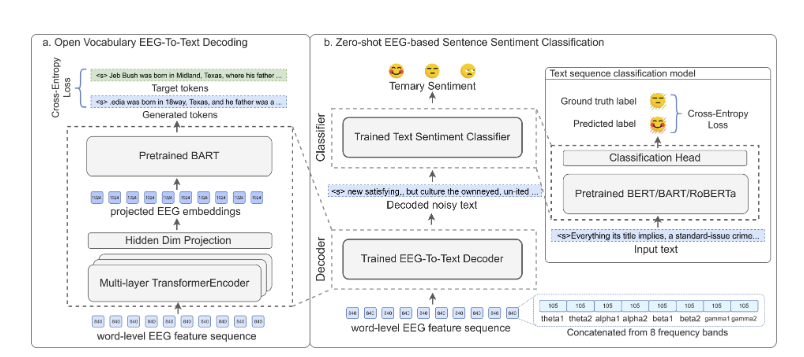
Open Vocabulary Electroencephalography-To-Text Decoding and Zero-shot Sentiment Classification
「简述」 在本文中,作者将该问题扩展到自然阅读任务中的开放词汇脑电图-文本序列-序列解码和零镜头句情感分类。假设人类大脑的功能是一个特殊的文本编码器,并提出了一个利用预先训练的语言模型(例如BART)的新框架。模型实现了40.1%的BLEU-1分数onEEG-To-Text解码和55.6%的F1分数基于零镜头脑电图的三元情感分类,这显著优于监督基线。
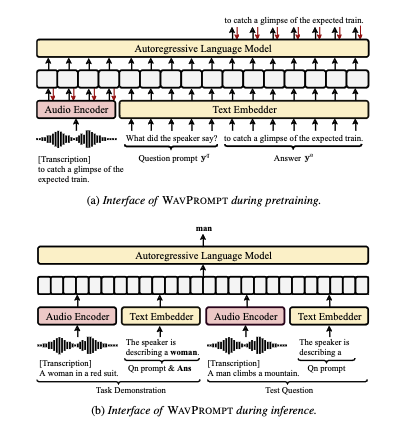
WAVPROMPT: Towards Few-Shot Spoken Language Understanding with Frozen Language Models
「简述」 。为了探索将少量学习能力转移到音频文本设置的可能性,作者提出了一个新的语音理解框架,WavPrompt,对wav2vec模型进行微调,以生成语言模型可以理解的音频嵌入序列。研究表明,WavPrompt是一种短时学习器,可以比原生文本基线更好地执行语音理解任务。对不同成分和超参数进行了详细的消融研究,以经验确定最佳模型配置。
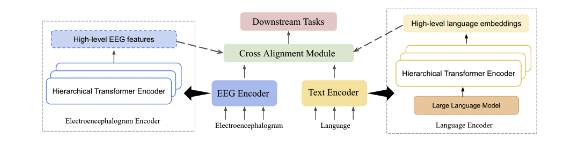
Can Brain Signals Reveal Inner Alignment with Human Languages?
「简述」 在本研究中,我们探讨了脑电与语言之间的关系和依赖关系。为了在表示层面进行研究,我们引入了textbfMTAM,一个textbfM多模态textbfT变压器textbfa木块textbfM模型,观察两模态之间的协调表示。我们使用各种关系对齐寻求技术,如典型相关分析和Wasserstein距离,作为损失函数来变形特征。在下游应用、情感分析和关系检测方面,我们在ZuCo和K-EmoCon两个数据集上取得了最新的结果。我们的方法在K-EmoCon数据集上的f1得分提高了1.7%,在情感分析的Zuco数据集上提高了9.3%,在关系检测的Zuco数据集上提高了7.4%。
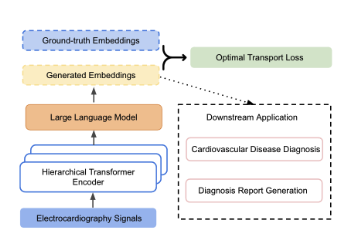
Transfer Knowledge from Natural Language to Electrocardiography: Can We Detect Cardiovascular Disease Through Language Models?
「简述」 在这项工作中,作者的目标是通过将LLMs的知识转移到临床心电图(ECG)来弥合这一差距。提出了一种用于心血管疾病诊断和心电诊断报告自动生成的方法。我们还通过最优传输(OT)引入了一个额外的损失函数来对齐ECG和语言嵌入之间的分布。学习到的嵌入在两个下游任务上进行评估:(1)自动生成心电图诊断报告,(2)零次心血管疾病检测。
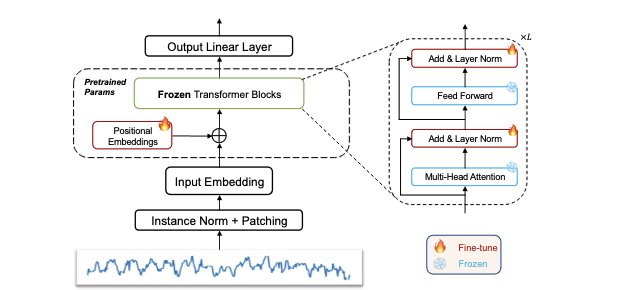
One Fits All: Power General Time Series Analysis by Pretrained LM
「简述」 在这项工作中,作者通过利用从数十亿代币中预训练的语言或CV模型进行时间序列分析来解决这一挑战。具体来说,我们避免改变预训练语言或图像模型中残差块的自注意和前馈层。这个模型被称为冷冻预训练变压器(FPT),通过对涉及时间序列的所有主要类型的任务进行微调来评估。我们的研究结果表明,在自然语言或图像上进行预训练的模型可以在所有主要的时间序列分析任务中产生相当的或最先进的性能。
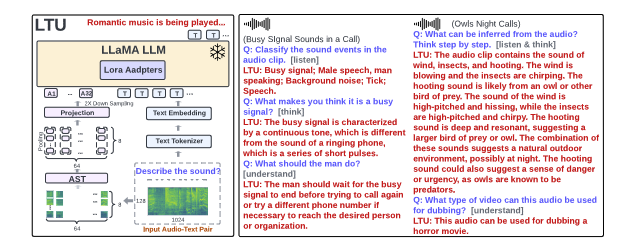
LISTEN, THINK, AND UNDERSTAND
「简述」 因此,作者提出了一个问题:能否建立一个既具有音频感知能力又具有推理能力的AI模型?在本文中,我们提出了一种新的音频基础模型,称为LTU (Listen, Think, and Understand)。为了训练LTU,我们创建了一个新的OpenAQA-5M数据集,该数据集由190万个封闭式和370万个开放式、多样化(音频、问题、答案)元组组成,并使用了自回归训练框架和感知到理解的课程。
TEST: TEXT PROTOTYPE ALIGNED EMBEDDING TO ACTIVATE LLM’S ABILITY FOR TIME SERIES
LLM4TS: Aligning Pre-Trained LLMs as Data-Efficient Time-Series Forecasters
MUSICUNDERSTANDINGLLAMA: ADVANCINGTEXT-TO-MUSICGENERATION WITHQUESTIONANSWERINGANDCAPTIONING
ETP: LEARNINGTRANSFERABLEECGREPRESENTATIONSVIAECG-TEXT PRE-TRAINING
END-TO-ENDSPEECHRECOGNITIONCONTEXTUALIZATIONWITHLARGE LANGUAGEMODELS
TIME-LLM: TIME SERIES FORECASTING BY REPROGRAMMING LARGE LANGUAGE MODELS
TEMPO: PROMPT-BASED GENERATIVE PRE-TRAINED TRANSFORMER FOR TIME SERIES FORECASTING
Lag-Llama: Towards Foundation Models for Probabilistic Time Series Forecasting
UniTime: A Language-Empowered Unified Model for Cross-Domain Time Series Forecasting
SALMONN: TOWARDS GENERIC HEARING ABILI TIES FOR LARGE LANGUAGE MODELS
JoLT: Jointly Learned Representations of Language and Time-Series
TENT: Connect Language Models with IoT Sensors for Zero-Shot Activity Recognition
GATGPT: A PRE-TRAINED LARGE LANGUAGE MODEL WITH GRAPH ATTENTION NETWORK FOR SPATIOTEMPORAL IMPUTATION
Multimodal Pretraining of Medical Time Series and Notes
Spatial-Temporal Large Language Model for Traffic Prediction
How Can Large Language Models Understand Spatial-Temporal Data?
Large Language Model Guided Knowledge Distillation for Time Series Anomaly Detection
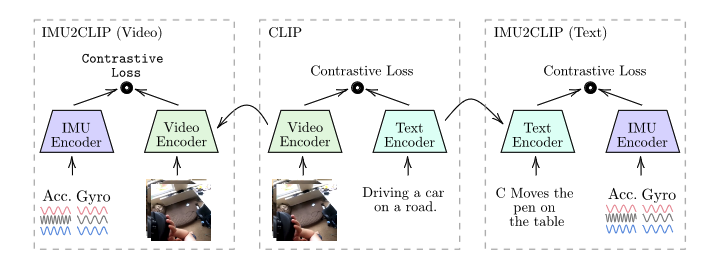
IMU2CLIP: Multimodal Contrastive Learning for IMU Motion Sensors from Egocentric Videos and Text
「简述」 作者提出了IMU2CLIP,一种新的预训练方法,通过将惯性测量单元(IMU)运动传感器记录与视频和文本对齐,将它们投射到对比语言-图像预训练(CLIP)的联合表示空间中。所提出的方法允许IMU2CLIP将人体运动(由IMU传感器测量)转换为相应的文本描述和视频,同时保留这些模态的及物性。我们探索了IMU2CLIP支持的几个新的基于imu的应用程序,例如基于情感的媒体检索和带有运动数据的自然语言推理任务。
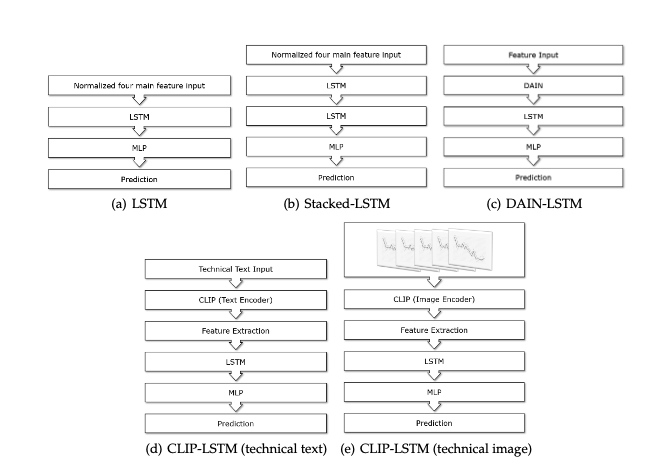
Leveraging Vision-Language Models for Granular Market Change Prediction
「简述」 。这项工作提出了用一种全新的方法建模和预测市场运动,即利用最近引入的视觉语言模型处理的股票数据的图像和基于字节的数字表示。我们对德国股票指数的每小时股票数据进行了大量的实验,并使用历史股票数据对股票价格预测的各种架构进行了评估。
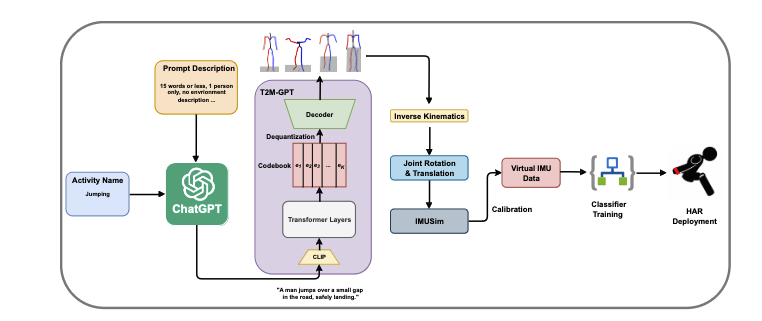
Generating Virtual On-body Accelerometer Data from Virtual Textual Descriptions for Human Activity Recognition
「简述」 。受文本描述和连接大型语言模型(llm)到各种人工智能模型的运动合成最新进展的启发,我们引入了一个自动化管道,首先使用ChatGPT生成活动的各种文本描述。然后,这些文本描述通过运动合成模型T2M-GPT生成3D人体运动序列,然后转换为虚拟IMU数据流。我们在三个HAR数据集(RealWorld, PAMAP2和USC-HAD)上对我们的方法进行了基准测试,并证明使用我们的新方法生成的虚拟IMU训练数据与仅使用真实IMUdata相比,显著提高了HAR模型的性能。
IMAGEBIND: One Embedding Space To Bind Them All
「简述」 作者提出了ImageBind,一个学习六种不同模态的方法-图像、文本、音频、深度、温度和IMU数据,证明这些成对的组合数据室对于训练联合编码是不必要的,而且只有图像对数据室足够将模态绑定的。ImageBind可以使用最近大规模视觉语言模型,并且扩展他们的zero-shot能力去新模态,只需要通过使用他们和图像自然配对关系即可。它使新颖的应用“开箱即用”,包括跨模态检索,用算法组合模态,跨模态检测和生成。随着图像编码器的增强,新型能力得到了提高,我们在跨模式的新型zero-shot识别任务上建立了一个SOTA,优于专家监督模型。

PandaGPT: One Model To Instruction-Follow Them All
AnyMAL:AnEfficient and Scalable Any-Modality Augmented Language Model
Insight Miner: A Time Series Analysis Dataset for Cross-Domain Alignment with Natural Language
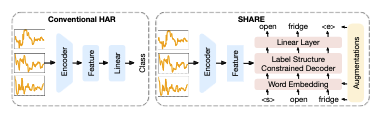
Unleashing the Power of Shared Label Structures for Human Activity Recognition
「简述」 在本文中,作者提出了SHARE,这是一个HAR框架,它考虑了不同活动的标签名称的共享结构。为了利用共享结构,SHARE包括用于从输入感觉时间序列中提取特征的编码器和用于生成作为标记序列的标签名称的解码器。我们还提出了三种标签增强技术,以帮助模型更有效地捕获跨活动的语义结构,包括基本的标记级增强,以及利用预训练模型功能的两种增强的嵌入级和序列级增强。
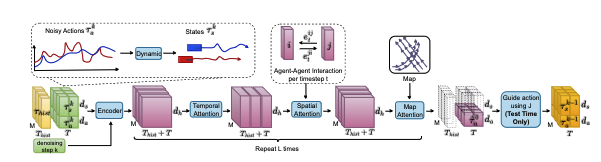
Language-Guided Traffic Simulation via Scene-Level Diffusion
「简述」 。为了解决这个问题,我们提出了ctg++,一个可以由语言指令指导的场景级条件扩散模型。开发这个需要解决两个挑战:需要一个现实和可控的流量模型主干,以及一个使用语言与流量模型接口的有效方法。为了解决这些挑战,我们首先提出了一个场景级扩散模型,该模型配备了aspatipatia -temporal transformer主干,可以产生真实可控的流量。然后,我们利用大型语言模型(LLM)将用户的查询转换为损失函数,引导扩散模型向查询兼容的生成。
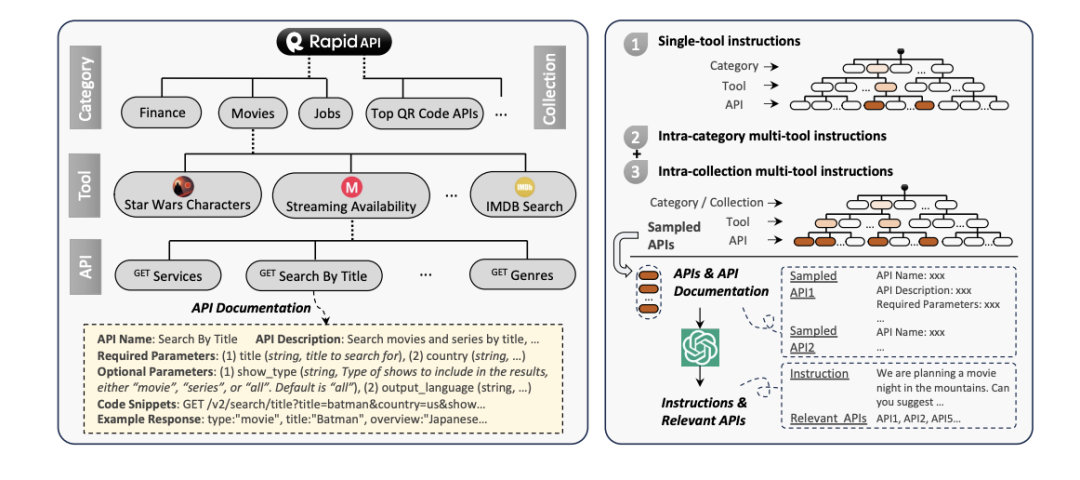
TOOLLLM: FACILITATING LARGE LANGUAGE MODELS TO MASTER 16000+ REAL-WORLD APIS
「简述」 作者首先介绍ToolBench,这是一个用于工具使用的指令调优数据集,它是使用ChatGPT自动创建的。具体来说,从RapidAPI Hub收集了横跨49个类别的16,464个真实的RESTful api,然后提示ChatGPT生成涉及这些api的各种人工指令,涵盖单工具和多工具场景。最后,使用ChatGPT为每个指令搜索有效的解决方案路径(API调用链)。为了提高搜索过程的效率,我们开发了一种新的基于深度优先搜索的决策树(DFSDT),使llm能够评估多个推理轨迹并扩展搜索空间。我们发现DFSDT显著提高了llm的规划和推理能力。为了有效的工具使用评估,开发了一个自动评估器:ToolEval。在ToolBench上对LLaMA进行了微调,得到了ToolLLaMA。
Integrating Stock Features and Global Information via Large Language Models for Enhanced Stock Return Prediction
GG-LLM: Geometrically Grounding Large Language Models for Zero-shot Human Activity Forecasting in Human-Aware Task Planning
TimeGPT-1
「简述」 在本文中,我们介绍了TimeGPT,时间序列的第一个基础模型,能够对训练期间未见的各种数据集生成准确的预测。我们根据已建立的统计、机器学习和深度学习方法评估了我们的预训练模型,证明了TimeGPT零射击推理在性能、效率和简单性方面表现出色。我们的研究提供了令人信服的证据,证明其他人工智能领域的见解可以有效地应用于时间序列分析。
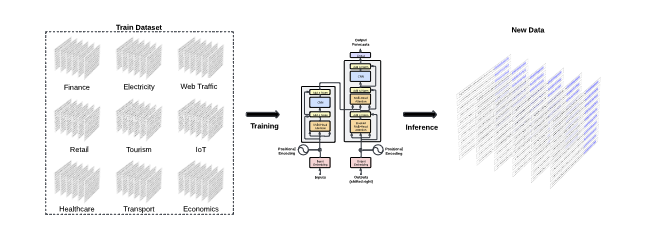
Towards Foundation Models for Time Series Forecasting
「简述」 为了建立时间序列预测的基础模型并研究它们的尺度行为,我们在这里介绍了我们正在进行的Lag-Llama,一个基于大量时间序列数据集训练的通用单变量概率时间序列预测模型。该模型在未见过的“非分布”时间序列数据集上显示出良好的零概率预测能力,优于监督基线。我们使用平滑破幂律来拟合和预测模型的缩放行为。


















 3046
3046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









