







混淆矩阵Confusion Matrix
混淆矩阵定义
混淆矩阵是机器学习中总结分类模型预测结果的情形分析表,以矩阵形式将数据集中的记录按照真实的类别与分类模型预测的类别判断两个标准进行汇总。其中矩阵的行表示真实值,矩阵的列表示预测值,下面我们先以二分类为例,看下矩阵表现形式,如下:
| 预测/真实 | 1(Postive) | 0(Negative) |
|---|---|---|
| 1 (Postive) | TP(True Postive:真阳) | FP (False Postive:假阳) |
| 0(Negative) | FN (False Negative:假阴) | TN (True Negative:真阴) |
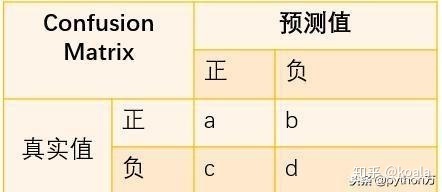
在讲矩阵之前,我们先复习下之前在讲分类评估指标中定义的一些符号含义,如下:
- TP(True Positive):将正类预测为正类数,真实为0,预测也为0
- FN(False Negative):将正类预测为负类数,真实为0,预测为1
- FP(False Positive):将负类预测为正类数, 真实为1,预测为0
- TN(True Negative):将负类预测为负类数,真实为1,预测也为1
刚才分析的是二分类问题,那么对于多分类问题,混淆矩阵表示的含义也基本相同,这里我们以三类问题为例,看看如何根据混淆矩阵计算各指标值。
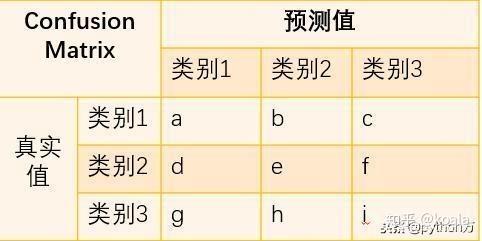
与二分类混淆矩阵一样,矩阵行数据相加是真实值类别数,列数据相加是分类后的类别数,那么相应的就有以下计算公式;
- 精确率_类别1=a/(a+d+g)
- 召回率_类别1=a/(a+b+c)
python 实现混淆矩阵
混淆矩阵(Confusion Matrix),是一种在深度学习中常用的辅助工具,可以让你直观地了解你的模型在哪一类样本里面表现得不是很好。
示例代码一如下:
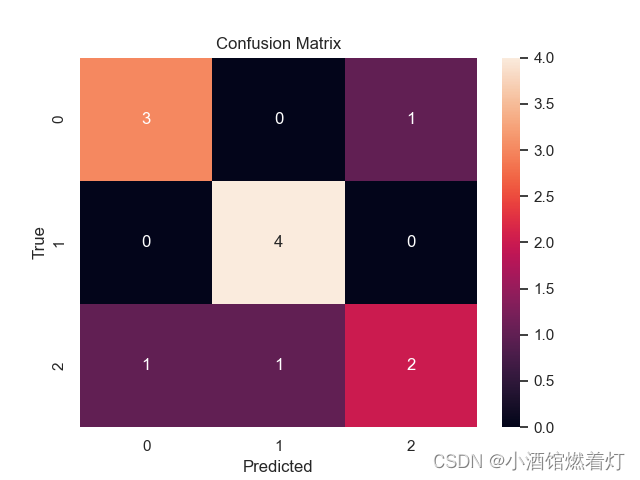
import seaborn as sns
from sklearn.metrics import confusion_matrix
import matplotlib.pyplot as plt
# 使用 seaborn 风格设置
sns.set()
# 创建混淆矩阵
C2 = confusion_matrix([0, 1, 2, 0, 1, 2, 0, 2, 2, 0, 1, 1], [0, 1, 1, 2, 1, 0, 0, 2, 2, 0, 1, 1])
# 创建子图
f, ax = plt.subplots()
# 打印混淆矩阵
print(C2)
# 绘制热力图
sns.heatmap(C2, annot=True, ax=ax)
# 设置标题和轴标签
ax.set_title('Confusion Matrix') # 标题
ax.set_xlabel('Predicted') # x轴
ax.set_ylabel('True') # y轴
# 显示图像
plt.show()
示例代码二如下:
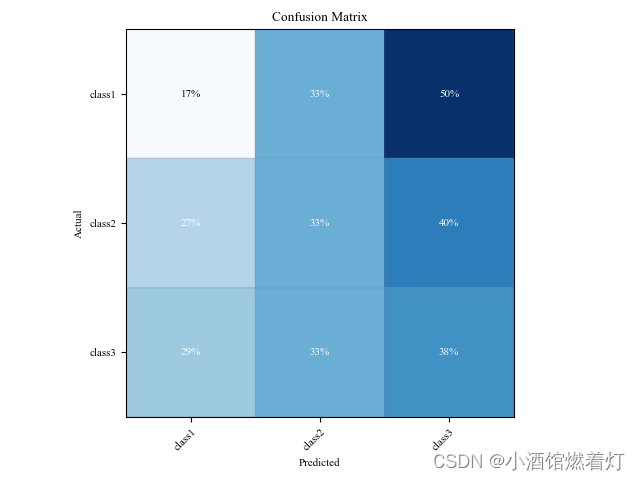
import matplotlib.pyplot as plt
import numpy as np
def plot_Matrix(cm, classes, title=None, cmap=plt.cm.Blues):
plt.rc('font', family='Times New Roman', size='8') # 设置字体样式、大小
# 按行进行归一化
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
print("Normalized confusion matrix")
str_cm = cm.astype(np.str).tolist()
for row in str_cm:
print('\t'.join(row))
# 占比1%以下的单元格,设为0,防止在最后的颜色中体现出来
for i in range(cm.shape[0]):
for j in range(cm.shape[1]):
if int(cm[i, j] * 100 + 0.5) == 0 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 172
172

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











