






一、元学习到底是啥??
参考:元学习(Meta-learning)——让机器学习如何学习
1、元学习是什么?
是一个常见的深度学习模型,目的是学习一个用于预测的数学模型。元学习面向的不是学习的结果,而是学习的过程。其学习的不是一个直接用于预测的数学模型,而是学习“如何更快更好地学习一个数学模型”。也就是说,要学会如何学习。
2、我们为什么需要元学习?
在机器学习中,工作量最大最无聊的就是调参。针对每一个任务我们都得从头开始调参,然后再耗费大量时间去训练并测试结果。因此,这个时候我们有一个想法:**为啥不能让机器自己学会调参?**就跟我们平时解数学题一样,遇到相似的题目(任务),能够举一反三,这样我们就不用每次都从头开始调参,也不用使用大量的标记数据进行训练。
3、训练神经网络流程
参考:一文通俗讲解元学习(Meta-Learning)
当训练一个神经网络时,一般步骤有,预处理数据集,选择网络结构,设置超参数,初始化参数,选择优化器,定义损失函数,梯度下降更新参数。
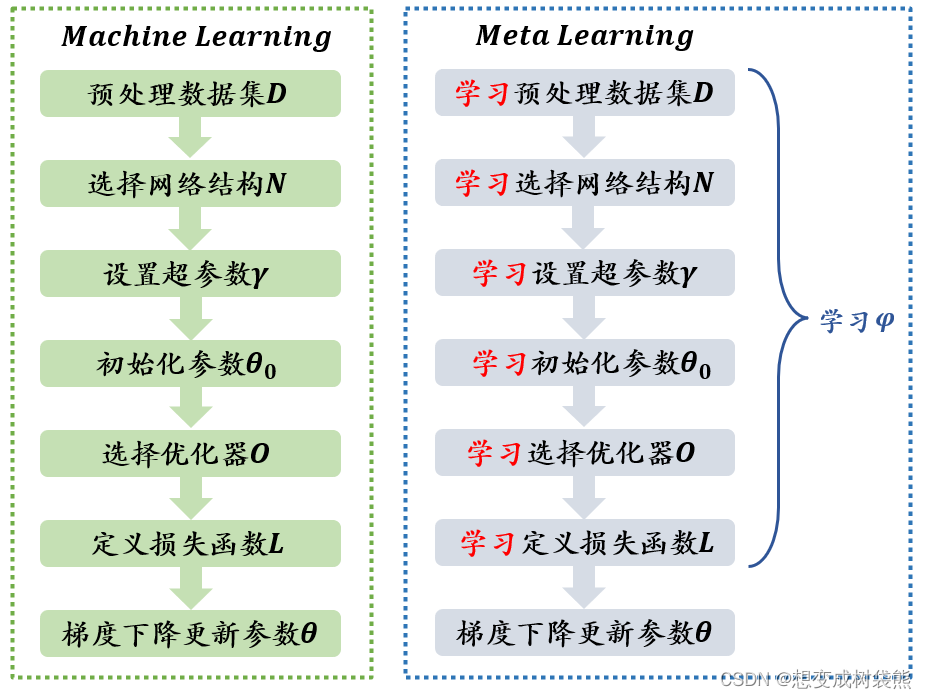
(1)学习预处理数据集
对数据进行预处理时,数据增强会增加模型的鲁棒性。一般的数据增强方式比较死板,只是对图像进行旋转,颜色变换,伸缩变换等等。而元学习可以自动地对数据进行增强。
(2)学习初始化参数
权重参数初始化的好坏可以影响模型最后的分类性能。元学习学习初始化参数的代表作时MAML,它专注于提升模型整体的学习能力,而不是解决某个具体问题的能力。训练时,不停地在不同的任务上切换,从而达到初始化网络参数的目的,最终得到的模型在面对新任务时可以学习得更快。
(3)学习网络结构
神经网络的结构设定很复杂,网络的深度是多少,每一层的宽度是多少,每一层的卷积核是多少个,每个卷积核的大小又该怎么定,需不需要dropout等问题。到目前为止没有一个定论或定理能够清晰准确地回答以上问题,因此神经网络结构搜索NAS应运而生。
神经网络结构其实是元学习的一个子类领域。网络结构的探索不能通过梯度下降法获得,这是一个不可导问题,一般情况下会采用强化学习或进化算法来解决。
(4)学习选择优化器
神经网络训练的过程中很重要的一环就是优化器的选择,不同的优化器会对优化参数时对梯度的走向有重要影响。熟知的优化器有Adam,RMsprop,SGD,NAG等。
4、元学习目标
平时机器学习时,都是针对某个特定的任务找到一个能实现这个任务的function,比如猫/狗的分类任务。而元学习的目标就是找到一个function,这个function能够让机器自动地去学习原先人为确定的一些超参数,比如初始化参数θ0、学习速率η、网络架构(比如convnet4、resnet12之类的)。这个function用FΦ表示,FΦ不是针对某个特定任务的,而是针对一群类似任务。比如这个任务可能包括猫和狗的分类、橘子和苹果的分类、自行车和摩托车的分类等等。
总结一下,元学习的目标就是!利用FΦ找到最优的超参数Φ,使每个任务在超参数Φ的基础上训练出最优参数后测试得到的损失值的和最小。
通俗地讲,就比如对于橘子和苹果的分类,在超参数Φ的基础上利用训练数据集进行训练,得到一个最优参数,然后再利用测试数据集对训练后的模型进行测试,测试得到一个损失值l1;同理,猫和狗的分类任务的测试损失值是l2,以及其他的分类任务的测试损失值ln,那么元学习就是要让所有任务的测试损失值之和最小。
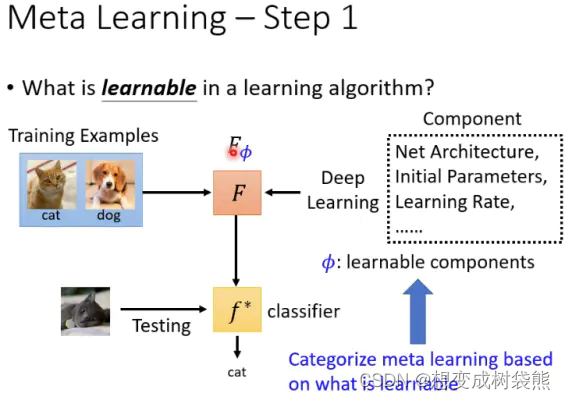
5、support set 、query set、validation set
我们可以看到,每个训练任务中都包含了训练数据和测试数据,在元学习中,把训练数据称为support set(支持集),把测试数据称为query set(查询集)。
查询集和验证集的不同??
6、元基线(meta-baseline)
元基线包括预训练和元学习两个阶段。
(1)预训练阶段
模型通过在大规模的数据集上进行训练来获取初始参数或特征表示。通常使用常规的无监督或有监督学习方法,例如自编码器、卷积神经网络(CNN)或递归神经网络(RNN)进行预训练。这一阶段的目标是使模型能够学习一般化的特征表示,以便在元学习阶段能够更好地适应新任务。
(2)元学习阶段
预训练的模型将通过在多个不同任务上进行快速适应来学习如何学习。每个任务都由一小部分训练样本组成,称为“支持集”(support set),以及一个用于评估模型性能的验证集。通过在支持集上进行少量的梯度更新或参数调整,模型能够快速适应当前任务的特定特征。然后,模型在验证集上进行评估,以衡量其在新任务上的性能。元学习的目标是使模型能够通过少量的样本和迭代更新来实现快速学习和泛化能力。
二、论文速读:A New Baseline for Few-Shot Learning
1、基本概念
(1)few-shot learning
小样本学习,是指从极少地样本中学习出一个模型。
(2)N-way K-shot
N-way指训练数据(support set)种有N个类别,K-shot指每个类别下有K个被标记数据。
2、论文介绍
(1)简述
参考:论文阅读:A New Meta-Baseline for Few-Shot Learning
该论文提出了一个分类器-基线(Classifier Baseline),在基类上预先训练一个分类器来学习视觉表示,然后删除最后一个依赖于类的全连接(FC)层。具体做法:给定一个具有少量样本的新类,我们计算给定样本的平均特征,并利用特征空间中的余弦距离,用最近质心对查询样本(验证集)进行分类,即余弦最近质心。这一过程也可看做是估计新类的最后FC权重,但不需要为新类训练参数。
后来作者提出用元学习改善分类器-基线,于是提出Meta-Beaseline。 在Meta-Baseline中,我们使用预先训练的分类器-基线初始化模型,并使用余弦最近轮廓度量执行元学习,这是Clssififier-Baseline中的评估度量 。(一种基于度量的元学习)。
(2)方法
(2.1)Classifier-Baseline
指在所有基类上训练一个具有分类功能的分类器,并使用余弦最近质心方法执行小样本任务。
具体来说,我们在所有具有标准交叉熵损失的基类上训练一个分类器,然后删除它的最后一个FC层,得到编码器fθ,将输入映射到特征空间。给定一个具有支持集S的小样本任务,让Sc表示c类中的小样本,我们计算平均特征Wc作为c类的质心:
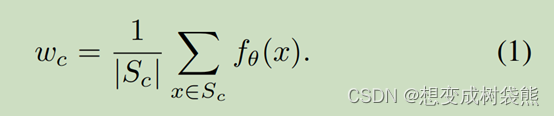
然后,对于小样本任务中的查询样本x,我们预测样本x属于c类的概率作为样本x的特征向量与c类质心之间的余弦相似度:
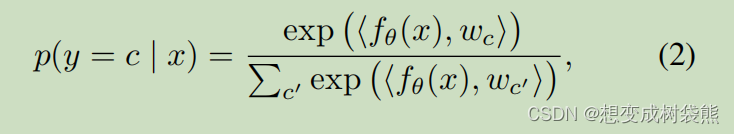
其中<.,.>表示两个向量的余弦相似度。 请注意,Wc也可以看作是新FC层对新概念的预测权重。
(2.2)Meta-Baseline
Generally,Meta-Baseline包含两个训练阶段。
第一阶段是预训练阶段。即训练分类器-基线法(即在所有基类上训练分类器,并删除其最后一个FC层以获得fθ)。
第二阶段是元学习阶段。在元学习阶段同样使用基类中的数据分成多个task,在每个task中对Support set用fθ编码,然后用(1)式求每个类的平均特征表示。同时对Query set也进行编码操作,利用(2)式余弦相似度求query-set和support-set之间的距离,使用softmax进行分类。
【注:hardmax最大特点就是只选出一个最大值,即非黑即白。但往往在实际中这种方式是不合理的,比如对于文本分类来说,一篇文章或多或少包含着各种主题的信息,我们更期望得到文章对于每个可能的文本类别的概率值。所以此时用到soft的概念,softmax的含义就在于不再唯一的确定某一个最大值,而是为每一个输出分类的结果都赋予一个概率值,表示属于每个类别的可能性)。】
为了计算每个任务的损失,在support set中,我们在(1)式中计算定义的N个类的质心,然后用于(2)式中计算定义的query set中每个样本的预测概率分布。损失是由p和query set中样本的标签计算的交叉熵损失。
三、网络结构
网络结构这部分让我很头疼,不同的网络结构训练速度截然不同,有的一下午就能有结果,有的好几天才会有结果,稍微出点差错又得重来,特此记录一下。
1、ResNet(Residual Network)
ResNet是指残差网络,是一种用于深度学习的卷积神经网络结构。resnet的主要创新在于引入了残差连接或跳跃连接,使得网络能够更好地训练和优化深层网络。
在传统地卷积神经网络中,通过堆叠多个卷积层来提取特征,但随着网络层数地增加,会出现梯度消失或梯度爆炸等问题,导致网络难以训练和优化。resnet通过在卷积层之间引入残差块,使得网络可以学习残差映射,即网络只需要学习输入与输出之间的差异,而不是直接学习整个映射函数。这种残差连接允许信息直接通过跳跃连接从一个层传递到另一个层,有效减轻了梯度消失的问题,使得可以训练更深的网络。
2、resnet12
resnet12是resnet的变体,是resnet的一个具体实现。resnet12指的是一个具有12个卷积层的resnet结构。
resnet12的网络结构包含多个残差块,每个残差块由两个或三个卷积层组成。通过堆叠这些残差块,可以构建出一个深度为12的神经网络。
3、convnet和resnet的区别
(1)网络结构
⭐Convnet:一种通用的神经网络结构,主要由卷积层、池化层和全连接层组成。它的主要特点是通过卷积操作和权重共享来提取输入数据的特征,逐渐构建出深层网络结构。
⭐Resnet:一种特定的卷积神经网络结构,引入了残差块和跳跃连接。通过跳跃连接,resnet允许信息直接从一个层传递到另一个层,有效解决了梯度消失和训练深层网络的问题。
(2)解决梯度消失问题
⭐ConvNet:ConvNet 中,随着网络层数的增加,梯度消失或梯度爆炸的问题可能会出现,导致难以训练更深层次的网络。
⭐ResNet:ResNet 通过引入残差连接,允许信息直接从一个层传递到另一个层,使得网络只需要学习输入与输出之间的差异,从而缓解了梯度消失的问题,使得可以训练更深的网络。
(3)模型深度
⭐ConvNet:ConvNet 的深度可以根据任务和需求进行调整,可以是相对较浅的网络结构,也可以是非常深的网络结构。
⭐ResNet:ResNet 以更深层次的网络为特点,例如 ResNet-50、ResNet-101 等,通常包含了数十到数百个卷积层。
四、传统深度学习网络(DNN)和脉冲神经网络(SNN)的区别
1、信息表示方式
(1)DNN:传统DNN使用实数值来表示神经元之间的信息传递。每个神经元的激活状态由实数表示,通常使用激活函数(如ReLU、sigmoid)对连续值进行非线性变换。信息在网络中以连续的激活值进行传递和处理。
(2)SNN:使用脉冲信号表示神经元之间的信息传递。脉冲信号是离散的、时间相关的事件,通过脉冲的时间和强度来编码信息。神经元在特定时间点发放脉冲。
2、计算模型
(1)DNN:通过反向传播算法进行训练和判断。它们使用梯度下降来优化网络权重,通过最小化损失函数来调整模型的参数。在前向传播过程中,输入数据经过一系列层的线性和非线性变换,最终得到输出结果。
(2)SNN:脉冲神经网络的计算模型更接近于生物神经系统的工作原理。脉冲神经网络通常使用时序反向传播算法(Temporal Backpropagation)进行训练。该算法考虑了脉冲信号的时间信息,通过时间差来计算梯度并进行反向传播。脉冲神经网络还利用突触时序可变性(Spike-Timing-Dependent Plasticity,STDP)学习规则来调整神经元之间的突触权重。
五、补充内容
看代码时遇到一些生疏的,特此记录一下。
optimizer_args: {lr: 0.05, weight_decay: 5.e-4, milestones: [90, 125]}
1、学习率(learning rate)
用于控制模型在每次参数更新时的步长大小。它决定了模型参数在每次迭代中更新的幅度。
学习率的选择对于训练过程和模型性能至关重要。如果学习率过大,可能导致参数在更新过程中发生剧烈波动,使模型无法收敛或发散;如果学习率过小,模型的训练速度可能会很慢,甚至无法达到理想的性能。
通常,在训练开始时,较大的学习率有助于快速探索损失函数的最小值附近的参数空间。随着训练的进行,为了更精确地收敛到最优解,可以逐渐减小学习率。这种策略被称为学习率衰减(Learning Rate Decay)。
2、权重衰减(weight decay)
一种用于正则化神经网络模型的技术。通过在损失函数中添加一个正则化项,惩罚较大的权重值,以防止模型过度拟合训练数据。
在神经网络的训练过程中,损失函数通常由两部分组成:数据项和正则化项。数据项用于衡量模型在训练数据上的拟合程度,而正则化项用于控制模型的复杂度。
权重衰减通过向损失函数添加一个权重范数的惩罚项来实现。这个惩罚项会使较大的权重值受到更大的惩罚,从而促使模型倾向于选择较小的权重值。
具体而言,权重衰减在损失函数中引入了一个正则化项,一般形式为 L2 范数(也称为欧几里得范数)的平方。这个正则化项乘以一个权衡因子 λ,用于调节正则化的强度。损失函数变为数据项加上 λ * ||W||^2,其中 W 表示模型的权重参数。
选择合适的权衡因子 λ 是一个重要的调节参数,需要根据具体问题和数据集进行调试和实验。较大的 λ 值会导致更强的权重惩罚,可能使模型更加保守;而较小的 λ 值则会减小正则化的影响,允许模型更自由地学习训练数据的细节。
3、学习率调度里程碑(Learning Rate Schedule Milestones)
是一种在深度学习中用于调整学习率的方法。它基于训练的迭代轮次或步数,通过预定义的里程碑点来改变学习率的取值。
学习率调度里程碑是一种离散的学习率调整方法,它在训练的特定轮次或步数达到预定的里程碑点时改变学习率的取值。
具体而言,学习率调度里程碑通常包括两个主要参数:里程碑点和学习率衰减因子。里程碑点是在训练过程中预设的特定轮次或步数,当训练达到这些里程碑点时,学习率会进行调整。学习率衰减因子表示学习率的衰减程度,它用于将当前学习率乘以一个系数来降低学习率的取值。
例如,假设我们设置了里程碑点为 [30, 60, 90],学习率衰减因子为 0.1。在训练的前30个轮次(或步数)内,学习率保持不变。当训练达到第30个轮次时,学习率会乘以 0.1,降低为原来的十分之一。当训练达到第60个轮次时,学习率再次乘以 0.1,变为原来的十分之一。以此类推,当训练达到第90个轮次时,学习率再次乘以 0.1。通过这种方式,学习率会在训练的不同阶段进行逐渐的衰减。
六、小样本数据集
最近跑了miniImageNet、Omniglot和tieredImageNet,所以在这里对这几个数据集进行一个介绍汇总。
参考:小样本数据集 (Few-shot Learning)
1、miniImgeNet
(1)数据集论文
[1] Matching networks for one shot learning, NIPS 2016. Vinyals et al.
[2] Optimization as a model for few-shot learning, ICLR 2017. Ravi and Larochelle.
(2)数据来源
从 ImageNet ILSVRC-2012 中抽取了 100 个类别的图像组成,每个类别包含 600 张图像,共 60,000 张图像。miniImageNet 在 2016 年由 工作 [1] 提出,作者将 100 个类别随机划分为 64:16:20,分别作为 training、validation 和 testing set,三个 sets 互不重叠。但是 工作 [1] 发表时没有提供他们的数据划分文件,因此 工作 [2] 按照同样的比例重新划分了数据。
(3)数据集使用说明及下载方式
数据划分按照 工作 [2] 的方式,数据标签为train.csv、val.csv和test.csv,分别对应训练、验证和测试的数据名称及标签,是大部分工作所使用的。
下载:mini-ImageNet 百度云下载
.csv文件内容如下:第一列为文件名(和图片名称对应),第二列为标签(和文件名前缀对应)。
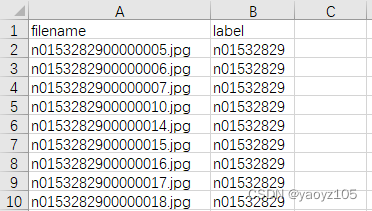
2、tieredImageNet
(1)数据集论文
[1] Meta-learning for semi-supervised few-shot classification, ICLR 2018.
(2)数据来源
tieredImageNet 在 2018 年由 工作[1] 提出,从 ImageNet ILSVRC-2012 中抽取了 34 个超类别(Categories),每个超类别包含 10~30 个不等的子类别(Classes),共 608 个子类别。每个子类别有数量不等的图像,共 779,165 张图像。与 miniImageNet 不同的是,tieredImageNet 考虑了 ImageNet 的类别层级结构。数据按照超类别进行划分,其中 20 个超类(351个子类)作为 training set,6 个超类(97个子类)作为 validation set,8 个超类(160个子类)作为 test set。
与miniImageNet相比:
- tieredImageNet的规模更大
- 训练/验证/测试数据的划分考虑了ImageNet的层级结构,通过划分超类别保证了三个集合的类别没有交叉,因此也更有难度。
| Train | Val | Test | Total | |
|---|---|---|---|---|
| Categories | 20 | 6 | 8 | 34 |
| Classes | 351 | 97 | 160 | 608 |
| Images | 448,695 | 124,261 | 206,209 | 779,165 |
(3)数据集使用说明及下载方式
和miniImageNet几乎一致,元数据压缩包按照train、val和test对数据进行划分,但没有相应的索引文件,建议生成索引文件(按照miniImageNet的索引文件格式)方便训练。
下载:tiered-ImageNet 百度云下载,提供已经生成好的.csv索引文件。
2、Omniglot
(1)数据集论文
Human-level concept learning through probabilistic program induction
(2)数据来源
Omniglot数据集来自 50 种不同语言的手写字符,共包含 1623 个类别(即1623种手写字符),每个类别只有 20 个样本,图像大小为 105 × 105。因此 Omniglot 数据集是一个类别极多,但每个类别的样本数量很少的小样本手写字符数据集。
比如,1623个类别里包含:日语平假名52个,日语片假名47个,韩语元音和辅音分别有21个和19个,最常见的拉丁字母表26个,等等。每个类别的字符有20个不同的手写体。
(3)数据使用说明
-
官方划分Omniglot数据集为background set和evaluation set,分别包含30个类别和20个类别。background set对应的就是我们常说的training set,用于模型的学习,evaluation set对应test set,用于测试模型的性能。
-
官方还提供了2个更有难度的人物设置:background small 1和background small 2作为训练集,而测试集不变。small1和small2分别包含5个background set,用于模拟成年人真实的学习数据量。
-
每个图像都有笔画数据与其配对,坐标序列为(x,y,time),且时间time以毫秒为单位,笔画数据存储在matlab文件中。笔画以‘START’未开始,笔画间的断点标记为‘BREAK’(即抬笔),原始的笔画数据是未经处理的,在时间和空间上的interval不一致,因此若需要用到笔画数据,需要进行一定的插值处理来获取统一的数据分布。
因此对于普通使用,只需要background set和evaluation set即可: -
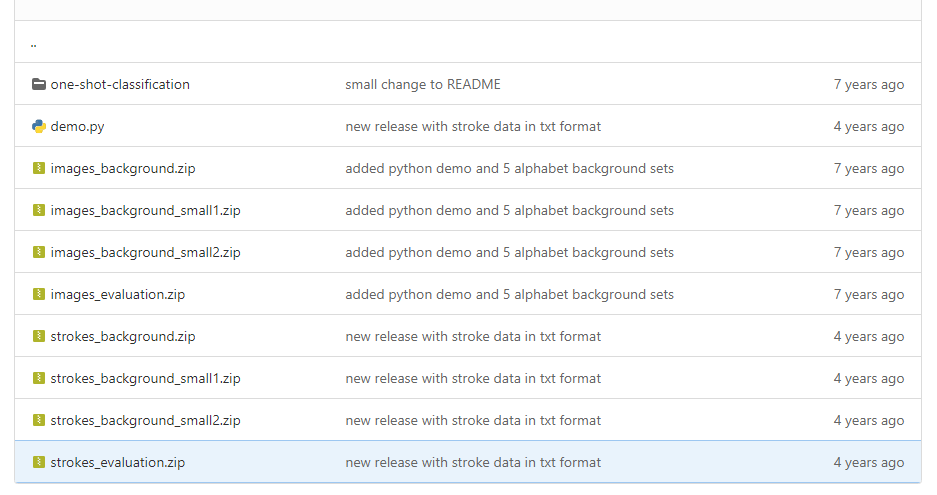
图片对应着下载文件中的image_background.zip和image_evaluation.zip
-
笔画对应着 strokes_background.zip 和 strokes_evaluation.zip
对于更有难度的任务设置,使用small set 1 或者 small set 2(注意测试数据不变): -
图片对应着下载文件中的 images_background_small1.zip(或 2) 和 images_evaluation.zip
-
笔画对应着 strokes_background_small1.zip(或 2) 和 strokes_evaluation.zip
(4)下载方式
github,下载整个项目,数据存放在python目录下















 2610
2610











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









