






前言
对于现在的AI模型来说,数据集是至关重要的,因为模型的性能和泛化能力很大程度上取决于它所训练的数据。数据的质量暂且不论,数据的多少一般情况下能直观的影响模型的性能和稳定性,而手工标注数据需要耗费大量时间,因此,Label Studio(开源数据标签工具)开发了通过Label Studio ML backend进行数据的预标注,极大程度降低了数据标定耗费的时间成本。
一、Label Studio ML backend是什么?
Label Studio ML后端是一个SDK,可让您包装机器学习代码并将其转换为Web服务器。然后,Web服务器可以连接到Label Studio以自动标记任务并从模型中动态检索预注释。简单来说就是从手动标注数据变成了模型预测,只需要手动微调(模型够精准,预测结果可以拿来直接训练)。
二、使用步骤
1.安装
1.1Anaconda
# 创建虚拟环境
conda create -n label-studio-ml
# 激活虚拟环境
conda activate label-studio-ml
# 安装label-studio-ml sdk
git clone https://github.com/HumanSignal/label-studio-ml-backend.git
cd label-studio-ml-backend/
pip install -e .
# 创建自己的机器学习后端
label-studio-ml create my_ml_backend
# 安装环境
pip install -r my_ml_backend
# 启动后端
label-studio-ml start my_ml_backend or python _wsgi.py
1.2Docker
# 安装label-studio-ml sdk
git clone https://github.com/HumanSignal/label-studio-ml-backend.git
cd label-studio-ml-backend/
pip install -e .
# 创建自己的机器学习后端
label-studio-ml create my_ml_backend
# 进入目录
cd my_ml_backend
# 安装机器学习环境
pip install -r requirements.txt
# 容器启动
docker-compose up
2.文件解析
进入my_ml_backend后,文件显示为:
my_ml_backend/
├── Dockerfile
├── docker-compose.yml
├── model.py
├── _wsgi.py
├── README.md
└── requirements.txt
其中,Dockerfile(环境安装)和docker-compose.yml(镜像、容器、端口等信息)文件是docker启动时运行的,本地启动只需安装requirements.txt中的环境,python _wsgi.py。_wsgi.py是启动机器学习后端服务的,内部会调用model.py文件,model.py文件包含predict(预测)和fit(训练)两部分,predict需要调用权重模型将推理结果以官方格式返回(torch和onnx都能成功),fit需要网络框架(训练失败,好像要开通会员),刚接触打开model.py一脸懵,官网也只是对其进行描述,不如进入label_studio_ml/examples/the_simplest_backend看里面的model.py。
import os
import json
import random
import label_studio_sdk
from uuid import uuid4
from label_studio_ml.model import LabelStudioMLBase
LABEL_STUDIO_HOST = os.getenv('LABEL_STUDIO_HOST', 'http://localhost:8080')
LABEL_STUDIO_API_KEY = os.getenv('LABEL_STUDIO_API_KEY', 'you-label-studio-api-key')
class MyModel(LabelStudioMLBase):
"""This simple Label Studio ML backend demonstrates training & inference steps with a simple scenario:
on training: it gets the latest created annotation and stores it as "prediction model" artifact
on inference: it returns the latest annotation as a pre-annotation for every incoming task
When connected to Label Studio, this is a simple repeater model that repeats your last action on a new task
"""
def predict(self, tasks, **kwargs):
""" This is where inference happens:
model returns the list of predictions based on input list of tasks
:param tasks: Label Studio tasks in JSON format
"""
# self.train_output is a dict that stores the latest result returned by fit() method
last_annotation = self.get('last_annotation')
if last_annotation:
# results are cached as strings, so we need to parse it back to JSON
prediction_result_example = json.loads(last_annotation)
output_prediction = [{
'result': prediction_result_example,
'score': random.uniform(0, 1),
# to control the model versioning, you can use the model_version parameter
# it will be displayed in the UI and also will be available in the exported results
'model_version': self.model_version
}] * len(tasks)
else:
output_prediction = []
print(f'Return output prediction: {json.dumps(output_prediction, indent=2)}')
return output_prediction
def download_tasks(self, project):
"""
Download all labeled tasks from project using the Label Studio SDK.
Read more about SDK here https://labelstud.io/sdk/
:param project: project ID
:return:
"""
ls = label_studio_sdk.Client(LABEL_STUDIO_HOST, LABEL_STUDIO_API_KEY)
project = ls.get_project(id=project)
tasks = project.get_labeled_tasks()
return tasks
def fit(self, event, data, **kwargs):
"""
This method is called each time an annotation is created or updated
It simply stores the latest annotation as a "prediction model" artifact
"""
self.set('last_annotation', json.dumps(data['annotation']['result']))
# to control the model versioning, you can use the model_version parameter
self.set('model_version', str(uuid4())[:8])
需要注意的几个地方from uuid import uuid4是给每个任务每个标注进行给定随机id,LABEL_STUDIO_HOST = os.getenv('LABEL_STUDIO_HOST', 'http://localhost:8080')label-studio端口号换成什么就得把8080换成那个端口,LABEL_STUDIO_API_KEY = os.getenv('LABEL_STUDIO_API_KEY', 'you-label-studio-api-key')要将你label-studio中的API Token值替换you-label-studio-api-key,在Account & Settings中。
3.label-studio连接后端
首先,打开label-studio的一个project,进入setting界面选择Machine Learning:

然后,点击Add Model,设置title、URL(label-studio-ml地址),如下所示:
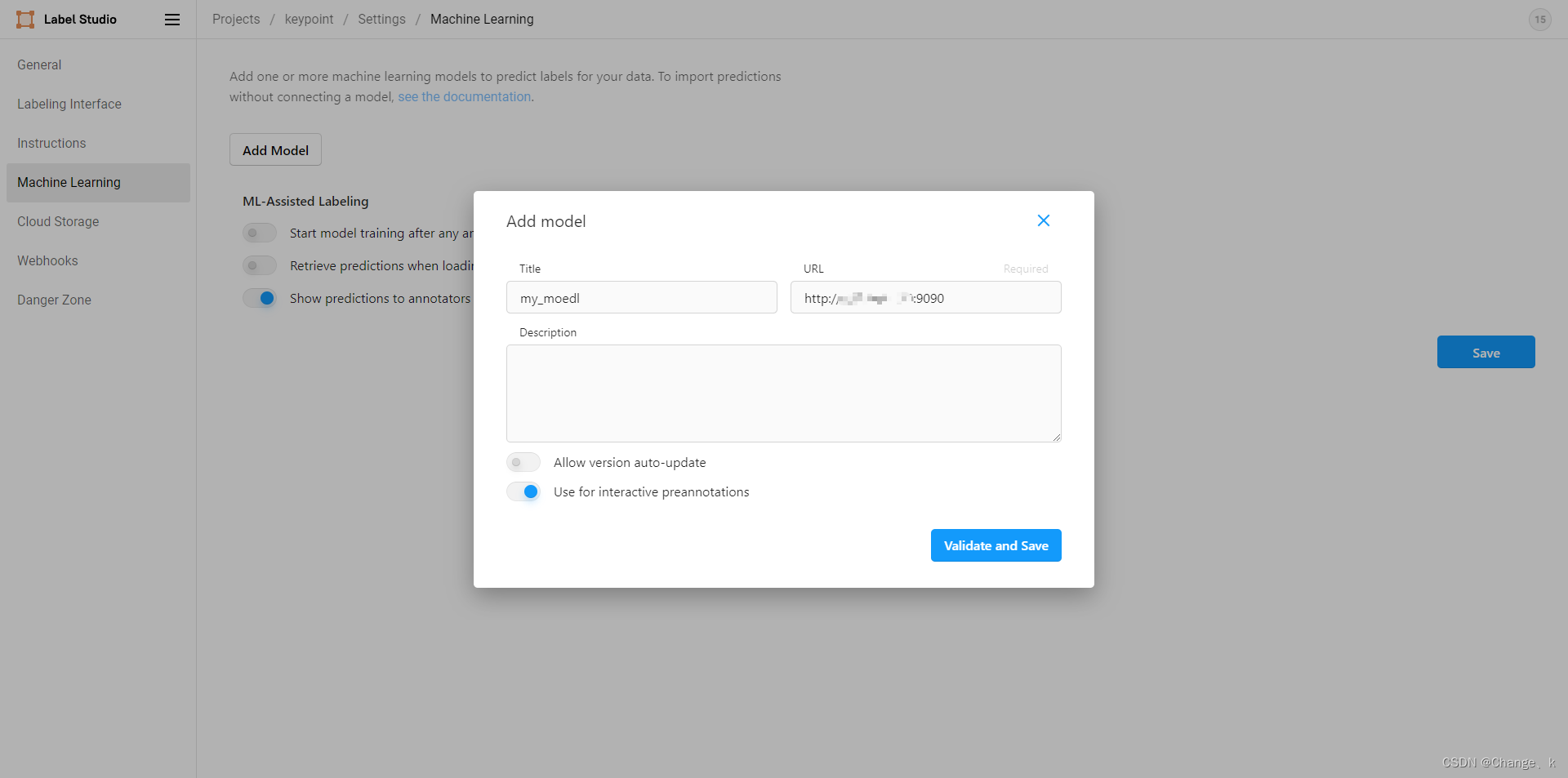
最后,点击validate and save:
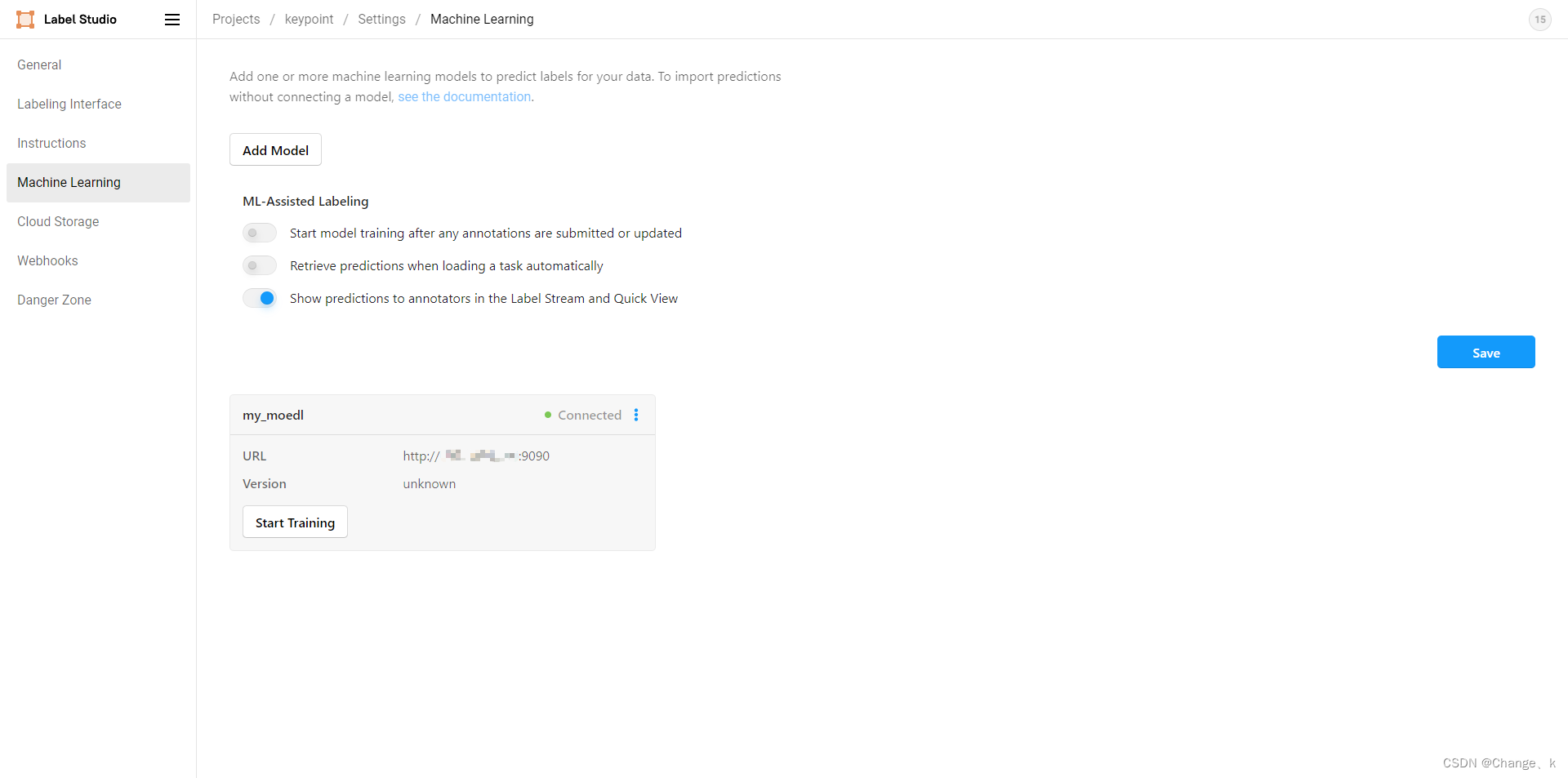
此时,机器学习后端连接成功,配置好template就可以进行预测,下面展示SAM和Keypoint两个预测案例。
三、案例展示
1.SAM
SAM是官方在样例中给出的,路径为:label_studio_ml/examples/segment_anything_model,主要文件:
/label_studio_ml/examples/segment_anything_model/
├── Dockerfile
├── docker-compose.yml
├── model.py
├── download_models.sh
├── onnxconverter.py
├── sam_predictor.py
├── _wsgi.py
├── README.md
└── requirements.txt
与之前样例相比,主要增加了download_models.sh、onnxconverter.py、sam_predictor.py三个文件,其中,download_models.sh在Docker容器构造环境时运行,下载sam(sam_vit_h_4b8939.pth)和mobilesam(mobile_sam.pt)权重模型,提供了两种方式交互推理(自选),通过onnxconverter.py文件将torch的权重模型转换为onnx模型给sam_predictor.py推理,model.py获取sam_predictor.py的结果做一些后处理返回给网页。
官方给出两种方式启动:Docker和手动设置,两种方式都需要参数设置正确,在配置成功前多数报错是参数问题,主要参数:
/label_studio_ml/examples/segment_anything_model/sam_predictor.py
VITH_CHECKPOINT = os.environ.get("VITH_CHECKPOINT", "sam_vit_h_4b8939.pth")
ONNX_CHECKPOINT = os.environ.get("ONNX_CHECKPOINT", "sam_onnx_quantized_example.onnx")
MOBILESAM_CHECKPOINT = os.environ.get("MOBILESAM_CHECKPOINT", "mobile_sam.pt")
LABEL_STUDIO_ACCESS_TOKEN = os.environ.get("LABEL_STUDIO_ACCESS_TOKEN")
LABEL_STUDIO_HOST = os.environ.get("LABEL_STUDIO_HOST")
启动机器学习后端:
# 1.Using Docker Compose
docker-compose up
# 2.Setting up the Backend Manually
# 2.1 download weights
# 2.2 pip install -r requirements.txt
python _wsgi.py or python sever.py
打开label-studio–setting–Machine Learning–Add model,输入URL,返回project打开task。
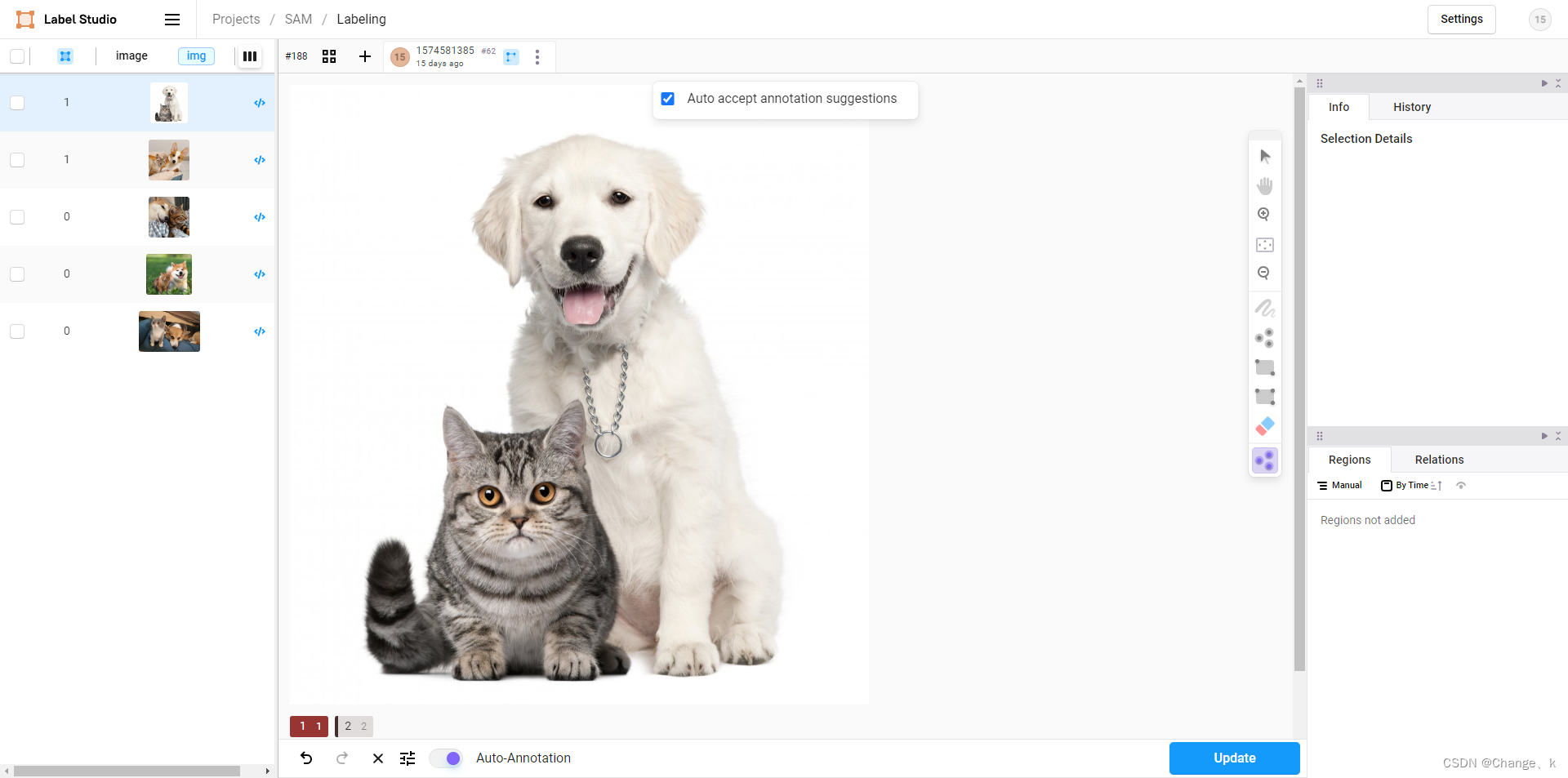
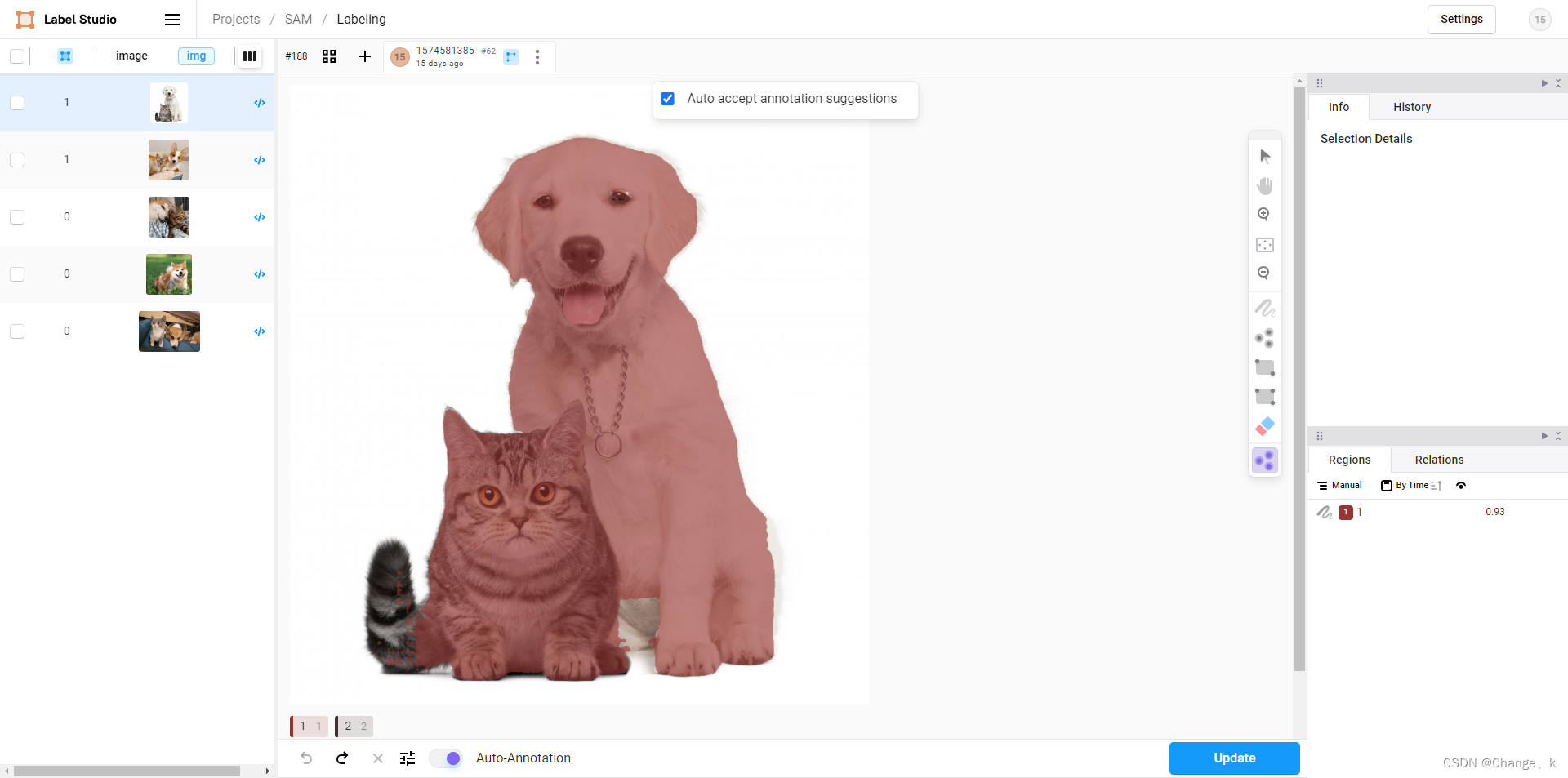
选择keypoint标签,点击自动生成mask图,(默认调用mobilesam模型,检测不太行!)
2.Keypoint
人脸106关键点预测,根据sam中model.py的文件修改的,keypoint的model.py如下:
from typing import List, Dict, Optional
from label_studio_ml.model import LabelStudioMLBase
from uuid import uuid4
import os
import cv2
import numpy as np
import torch
import PIL.Image as Image
from torchvision.transforms import transforms
import onnxruntime as ort
from label_studio_ml.utils import get_image_local_path
from urllib.parse import urlparse, parse_qs
ONNX_CHECKPOINT = os.environ.get("ONNX_CHECKPOINT", "epoch59_normal_0629.onnx")
MOBILESAM_CHECKPOINT = os.environ.get("MOBILESAM_CHECKPOINT", "mobile_sam.pt")
LABEL_STUDIO_ACCESS_TOKEN = os.environ.get("LABEL_STUDIO_ACCESS_TOKEN")
LABEL_STUDIO_HOST = os.environ.get("LABEL_STUDIO_HOST")
LOCAL_FILES_DOCUMENT_ROOT = 'D:/123/images'
LABEL_STUDIO_LOCAL_FILES_DOCUMENT_ROOT = '/label-studio/data/images'# 'D:/123/images'
class PIPNetModel(LabelStudioMLBase):
@property
def model_name(self):
return f'{ONNX_CHECKPOINT}'
def predict(self, tasks: List[Dict], context: Optional[Dict] = None, **kwargs) -> List[Dict]:
# from_name, to_name, value = self.get_first_tag_occurence('Keypointlabels', 'Image') BrushLabels
from_name, to_name, value = self.get_first_tag_occurence('BrushLabels', 'Image')
if not context or not context.get('result'):
# if there is no context, no interaction has happened yet
return []
image_width = context['result'][0]['original_width']
image_height = context['result'][0]['original_height']
# collect context information
point_coords = [] # initialization information
point_labels = [] # initialization information
input_box = None
selected_label = None
for ctx in context['result']:
x = ctx['value']['x'] * image_width / 100
y = ctx['value']['y'] * image_height / 100
ctx_type = ctx['type']
selected_label = ctx['value'][ctx_type][0] # label name
if ctx_type == 'keypointlabels':
point_labels.append(int(ctx['is_positive']))
point_coords.append([int(x), int(y)])
elif ctx_type == 'rectanglelabels':
box_width = ctx['value']['width'] * image_width / 100
box_height = ctx['value']['height'] * image_height / 100
input_box = [int(x), int(y), int(box_width + x), int(box_height + y)]
# 获取标签信息 例如:Point coords are [[605, 693]], point labels are [1], input box is None
print(f'Point coords are {point_coords}, point labels are {point_labels}, input box is {input_box}')
# 加载权重模型
dirname = os.path.dirname(__file__)
model_path = os.path.join(dirname, 'epoch59_normal_0629.onnx')
# 加载图像
img_path = tasks[0]['data'][value]
# image = cv2.imread(image_path)
# image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
predictor_results = PTH_inference(model_path, img_path)
# predictor_results = PREDICTOR.predict(
# img_path=img_path,
# point_coords=point_coords or None,
# point_labels=point_labels or None,
# input_box=input_box
# )
predictions = self.get_results(
predictor_results=predictor_results,
point=predictor_results[0],
width=image_width,
height=image_height,
from_name=from_name,
to_name=to_name,
label=selected_label)
return predictions
def get_results(self, predictor_results, point, width, height, from_name, to_name, label):
results = []
for i in range(0, len(point), 2):
# creates a random ID for your label everytime so no chance for errors
label_id = str(uuid4())[:4]
# converting the mask from the model to RLE format which is usable in Label Studio
results.append({
"original_width": width,
"original_height": height,
"image_rotation": 0,
"value": {
"x": (point[i] * predictor_results[1] * 100 / width).astype(np.float64),
"y": (point[i+1] * predictor_results[2] * 100 / height).astype(np.float64),
"width": 0.6,
"keypointlabels": ["1"]
},
"id": label_id,
"from_name": from_name,
"to_name": to_name,
"type": "keypointlabels",
})
return [{
'result': results, # results
'model_version': f'{ONNX_CHECKPOINT}'
}]
def PTH_inference(model_path, image_file, input_size=256, stride=32, grid_width=8, grid_height=8, nb=10):
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
preprocess = transforms.Compose([transforms.ToTensor()]) # , normalize
# assert os.path.splitext(model_path)[1] == ".pt", "model file should end with pth"
# net = torch.load(model_path, map_location=torch.device('cpu'))
sess = ort.InferenceSession(model_path)
# net = net.eval()
with torch.no_grad():
image_file = get_image_local_path(
image_file,
label_studio_access_token=LABEL_STUDIO_ACCESS_TOKEN,
label_studio_host=LABEL_STUDIO_HOST
)
image = cv2.imread(image_file)
# 获取图像的形状信息
height, width, channels = image.shape
# 创建一个与原始图像相同大小的空白图像
copied_image = np.zeros_like(image)
# 复制图像到新创建的图像中
copied_image[:height, :width, :] = image
# 指定目标大小
target_size = (256, 256) # 你可以替换为自己想要的目标宽度和高度
# 使用 resize 函数调整图像大小
resized_image = cv2.resize(copied_image, target_size)
input = Image.fromarray(resized_image[:, :, ::-1].astype(np.uint8), 'RGB')
input = preprocess(input).unsqueeze(0).numpy()
output_names = [sess.get_outputs()[i].name for i in range(5)]
output_data = sess.run(output_names, {sess.get_inputs()[0].name: input})
outputs_cls, outputs_x, outputs_y, outputs_nb_x, outputs_nb_y = torch.from_numpy(output_data[0]), \
torch.from_numpy(output_data[1]), \
torch.from_numpy(output_data[2]), \
torch.from_numpy(output_data[3]), \
torch.from_numpy(output_data[4])
outputs_cls = outputs_cls.view(106, -1)
# print(outputs_cls.shape)
max_cls, max_ids = torch.max(outputs_cls, 1)
max_ids = max_ids.view(-1, 1)
# print(max_ids)
max_ids_nb = max_ids.repeat(1, nb).view(-1, 1)
outputs_x = outputs_x.view(106, -1)
# print(outputs_x.shape)
outputs_x_select = torch.gather(outputs_x, 1, max_ids)
# print(outputs_x_select.shape)
outputs_x_select = outputs_x_select.squeeze(1)
outputs_y = outputs_y.view(106, -1)
outputs_y_select = torch.gather(outputs_y, 1, max_ids)
outputs_y_select = outputs_y_select.squeeze(1)
outputs_nb_x = outputs_nb_x.view(106 * nb, -1)
outputs_nb_x_select = torch.gather(outputs_nb_x, 1, max_ids_nb)
outputs_nb_x_select = outputs_nb_x_select.squeeze(1).view(-1, nb)
outputs_nb_y = outputs_nb_y.view(106 * nb, -1)
outputs_nb_y_select = torch.gather(outputs_nb_y, 1, max_ids_nb)
outputs_nb_y_select = outputs_nb_y_select.squeeze(1).view(-1, nb)
tmp_x = (max_ids % grid_height).view(-1, 1).float() + outputs_x_select.view(-1, 1)
tmp_y = (max_ids // grid_width).view(-1, 1).float() + outputs_y_select.view(-1, 1)
tmp_x /= 1.0 * input_size / stride
tmp_y /= 1.0 * input_size / stride
tmp_nb_x = (max_ids % grid_height).view(-1, 1).float() + outputs_nb_x_select
tmp_nb_y = (max_ids // grid_width).view(-1, 1).float() + outputs_nb_y_select
tmp_nb_x = tmp_nb_x.view(-1, nb)
tmp_nb_y = tmp_nb_y.view(-1, nb)
tmp_nb_x /= 1.0 * input_size / stride
tmp_nb_y /= 1.0 * input_size / stride
dirname = os.path.dirname(model_path)
meanface_indices, reverse_index1, reverse_index2, max_len = get_meanface(
os.path.join(dirname, "meanface.txt"), nb)
lms_pred = torch.cat((tmp_x, tmp_y), dim=1).flatten()
tmp_nb_x = tmp_nb_x[reverse_index1, reverse_index2].view(106, max_len)
tmp_nb_y = tmp_nb_y[reverse_index1, reverse_index2].view(106, max_len)
lms_pred_x = torch.mean(torch.cat((tmp_x, tmp_nb_x), dim=1), dim=1).view(-1, 1)
lms_pred_y = torch.mean(torch.cat((tmp_y, tmp_nb_y), dim=1), dim=1).view(-1, 1)
lms_pred_merge = torch.cat((lms_pred_x, lms_pred_y), dim=1).flatten().cpu().numpy()
return lms_pred_merge, width, height
def get_meanface(meanface_file, num_nb):
with open(meanface_file) as f:
meanface = f.readlines()[0]
meanface = meanface.strip().split()
meanface = [float(x) for x in meanface]
meanface = np.array(meanface).reshape(-1, 2)
# each landmark predicts num_nb neighbors
meanface_indices = []
for i in range(meanface.shape[0]):
pt = meanface[i, :]
dists = np.sum(np.power(pt - meanface, 2), axis=1)
indices = np.argsort(dists)
meanface_indices.append(indices[1:1 + num_nb])
# each landmark predicted by X neighbors, X varies
meanface_indices_reversed = {}
for i in range(meanface.shape[0]):
meanface_indices_reversed[i] = [[], []]
for i in range(meanface.shape[0]):
for j in range(num_nb):
meanface_indices_reversed[meanface_indices[i][j]][0].append(i)
meanface_indices_reversed[meanface_indices[i][j]][1].append(j)
max_len = 0
for i in range(meanface.shape[0]):
tmp_len = len(meanface_indices_reversed[i][0])
if tmp_len > max_len:
max_len = tmp_len
# tricks, make them have equal length for efficient computation
for i in range(meanface.shape[0]):
tmp_len = len(meanface_indices_reversed[i][0])
meanface_indices_reversed[i][0] += meanface_indices_reversed[i][0] * 10
meanface_indices_reversed[i][1] += meanface_indices_reversed[i][1] * 10
meanface_indices_reversed[i][0] = meanface_indices_reversed[i][0][:max_len]
meanface_indices_reversed[i][1] = meanface_indices_reversed[i][1][:max_len]
# make the indices 1-dim
reverse_index1 = []
reverse_index2 = []
for i in range(meanface.shape[0]):
reverse_index1 += meanface_indices_reversed[i][0]
reverse_index2 += meanface_indices_reversed[i][1]
return meanface_indices, reverse_index1, reverse_index2, max_len
主要从获取图像信息的地方开始:
# 加载权重模型
dirname = os.path.dirname(__file__)
model_path = os.path.join(dirname, 'epoch59_normal_0629.onnx')
# 加载图像
img_path = tasks[0]['data'][value]
# image = cv2.imread(image_path)
# image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
根据自己的需求进行数据前处理,另外是预测信息的结果返回,不知道如何构建的话,可以手工标注一个task,export它的json文件,按照“result”的信息构建:
def get_results(self, predictor_results, point, width, height, from_name, to_name, label):
results = []
for i in range(0, len(point), 2):
# creates a random ID for your label everytime so no chance for errors
label_id = str(uuid4())[:4]
# converting the mask from the model to RLE format which is usable in Label Studio
results.append({
"original_width": width,
"original_height": height,
"image_rotation": 0,
"value": {
"x": (point[i] * predictor_results[1] * 100 / width).astype(np.float64),
"y": (point[i+1] * predictor_results[2] * 100 / height).astype(np.float64),
"width": 0.6,
"keypointlabels": ["1"]
},
"id": label_id,
"from_name": from_name,
"to_name": to_name,
"type": "keypointlabels",
})
return [{
'result': results, # results
'model_version': f'{ONNX_CHECKPOINT}'
}]
关键点信息是106个点,因此,需要传入106个点的信息,每个点的id是随即编码的。后端连接成功后,进行预测结果如下:
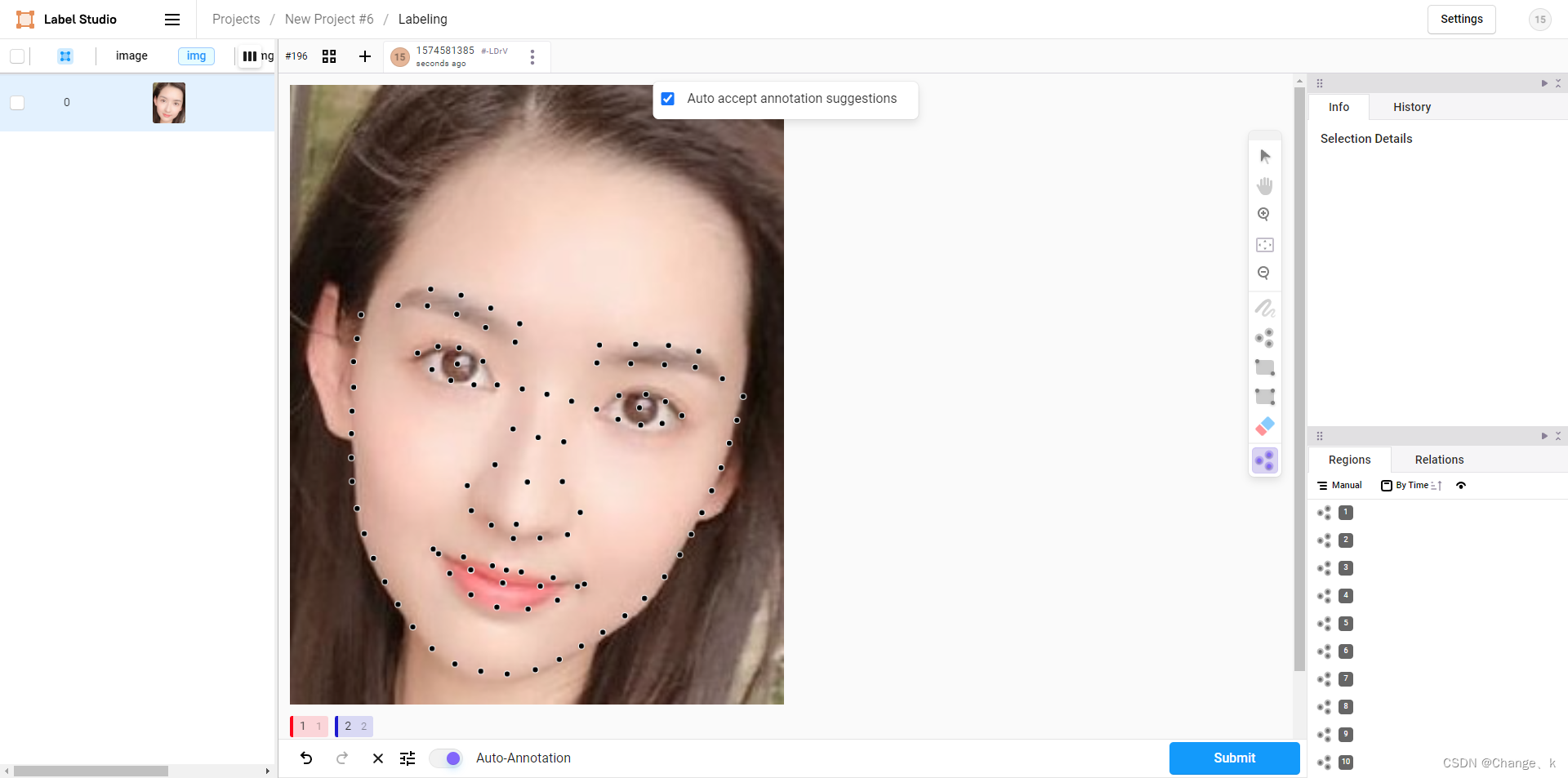
最后,根据结果进行微调。
总结
本文仅仅简单介绍了label-studio-ml在computer vision方面的简单使用,而label-studio-ml提供了大量数据任务模板,能使我们快速便捷地制作数据集。

















 883
883

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









