






文章目录
前言
label-studio是标注数据的,label-studio-ml是机器学习预测的,但大多数project需要较多的数据量,label-studio通过URL或本地上传有文件个数限制,超过限制数量会报错,即使将报错的位置注释掉,同时加载几千几万张会使浏览器崩溃。因此,大量导入数据需要利用cloud and external storage,官方文档有具体说明,本文仅记录一下自己实现过程。
一、Sync data from external storage是什么?
通过将Label Studio与流行的云和外部存储系统集成,可以收集到这些存储系统中上传的新项,并将标注结果返回,以便在机器学习流程中使用。具体来说,这可能涉及监视云存储桶、容器、数据库或目录,以便在这些存储中有新数据上传时触发Label Studio进行标注。标注的结果可以用于训练机器学习模型或进行其他相关的分析和应用。
有以下几种可以设置的方式:
1.Amazon S3
2.Google Cloud Storage
3.Microsoft Azure Blob storage
4.Redis database
5.Local storage
二、Local storage

如果要从特定目录添加到Label Studio的本地文件,可以在LS作为源存储或目标存储运行的机器上设置特定的本地目录。Label Studio递归遍历目录以读取任务。需要增加两个变量:
LABEL_STUDIO_LOCAL_FILES_SERVING_ENABLED=true
LABEL_STUDIO_LOCAL_FILES_DOCUMENT_ROOT=/home/user (linux)
or LABEL_STUDIO_LOCAL_FILES_DOCUMENT_ROOT=D:\\123\\data (window)
1.label-studio启动
docker run -it -p 8080:8080 \
-v $(pwd)/mydata:/label-studio/data \
--env LABEL_STUDIO_LOCAL_FILES_SERVING_ENABLED=true \
--env LABEL_STUDIO_LOCAL_FILES_DOCUMENT_ROOT=/label-studio/data/images \
heartexlabs/label-studio:latest
mydata替换成自己的路径,如果出错就检查本地路径与容器路径是否匹配。
2.label-studio-ml启动
机器学习后端也需要指定数据集路径,不然报错推理给的是空值(未找到数据,我的是这样的)。
# 方法一
LOCAL_FILES_DOCUMENT_ROOT=D:\\123\\data
# 方法二
LABEL_STUDIO_LOCAL_FILES_DOCUMENT_ROOT=D:\\123\\data
这样也会将本地存储的数据传递给机器学习后端进行预测。
三、操作流程
新建或打开一个project进入setting,选择Cloud Storage

点击add source storage:
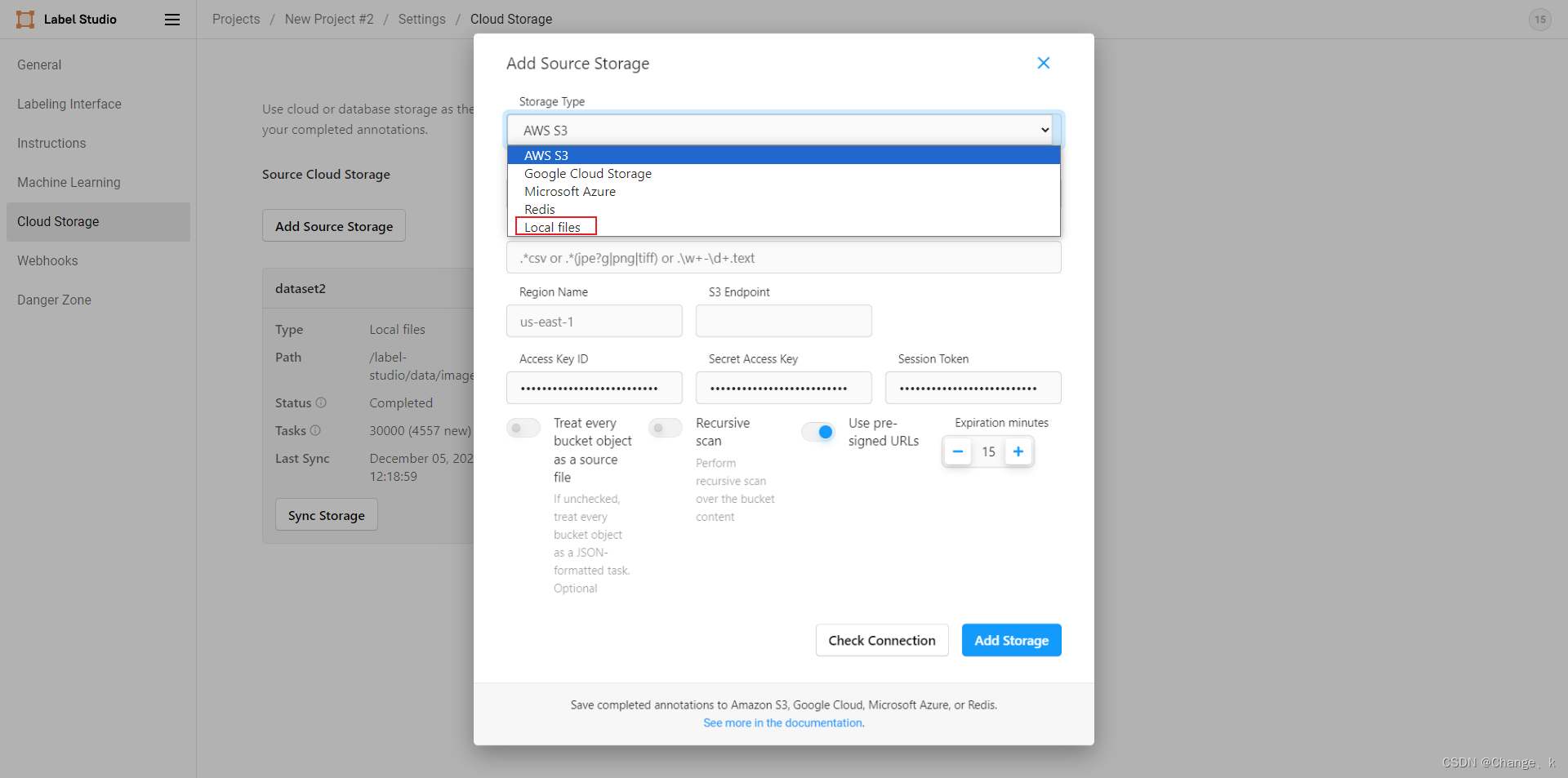
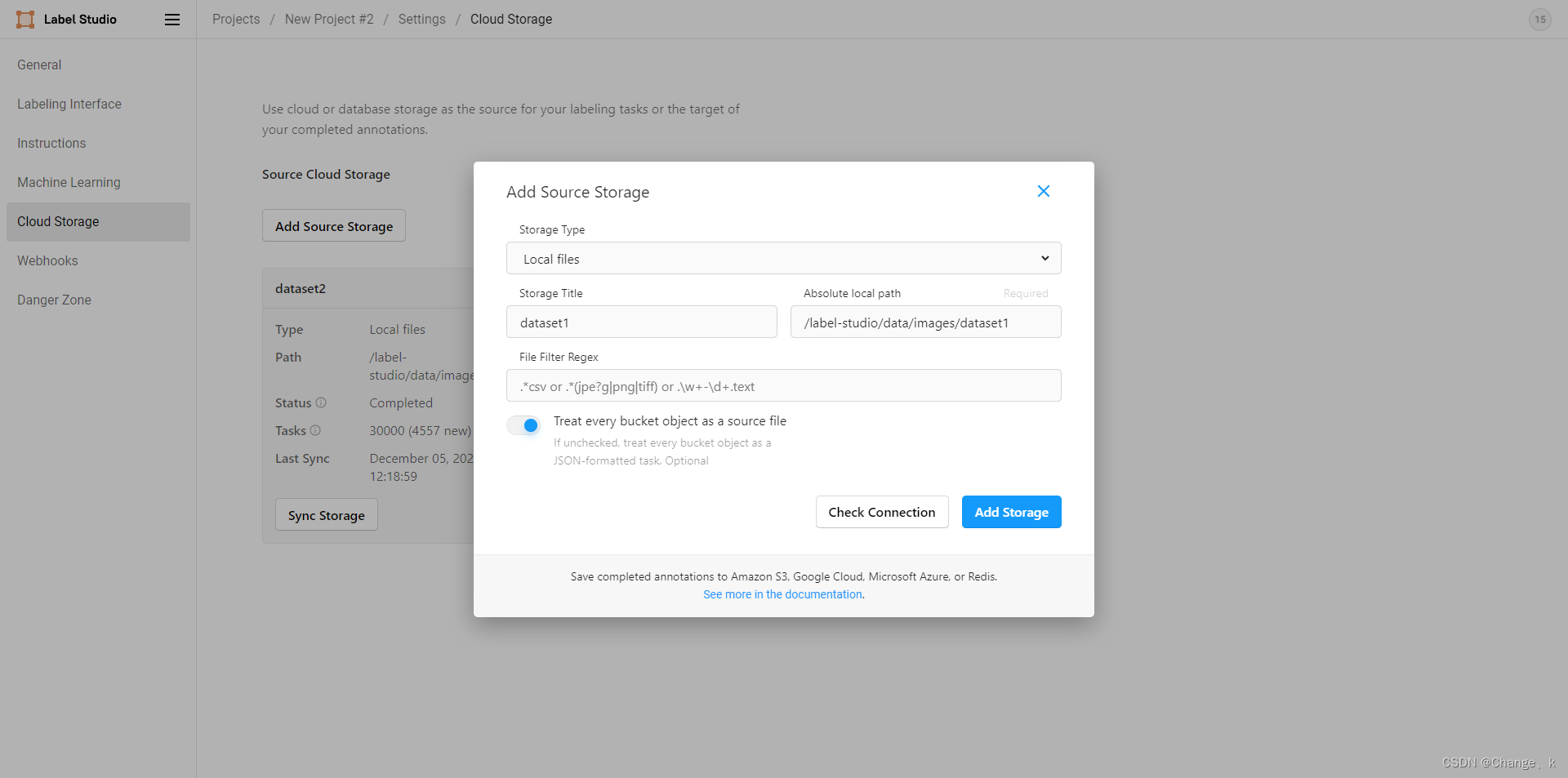
选择local storage,其余选择如下图所示:
点击check connection:
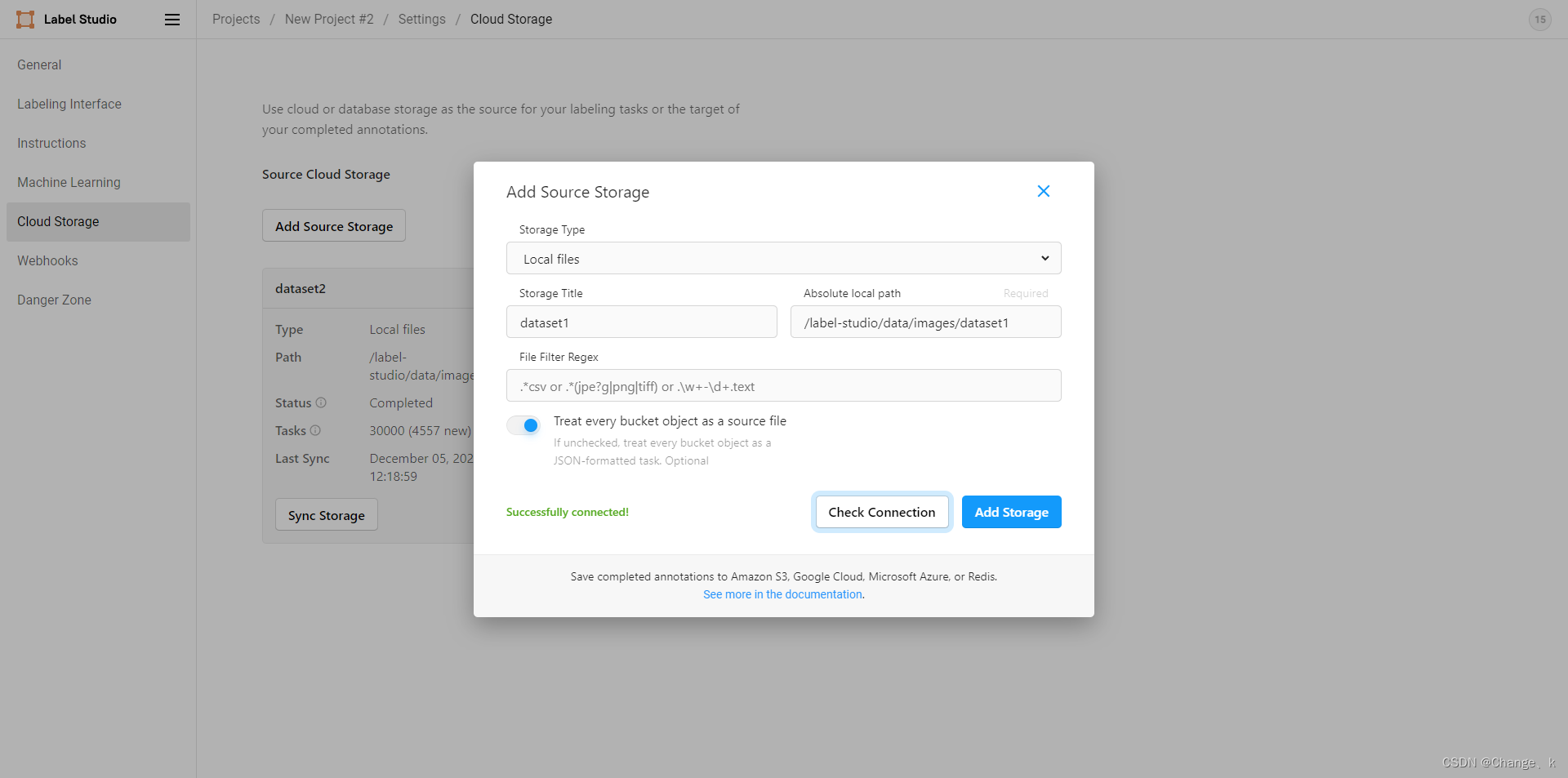
在点击add storage:
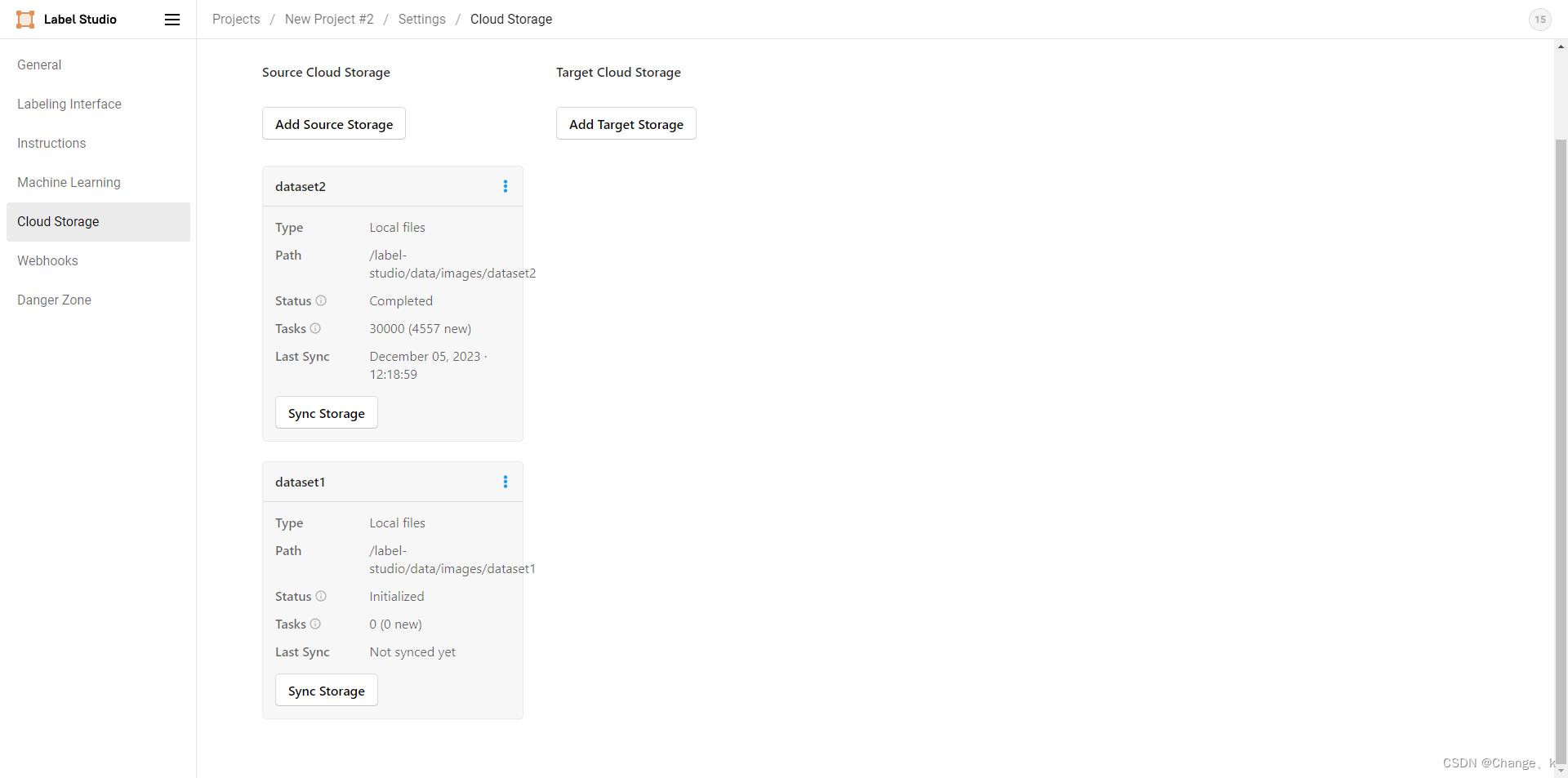
最后点击dataset1的sync storage进行同步存储,刷新能看到加载进度:
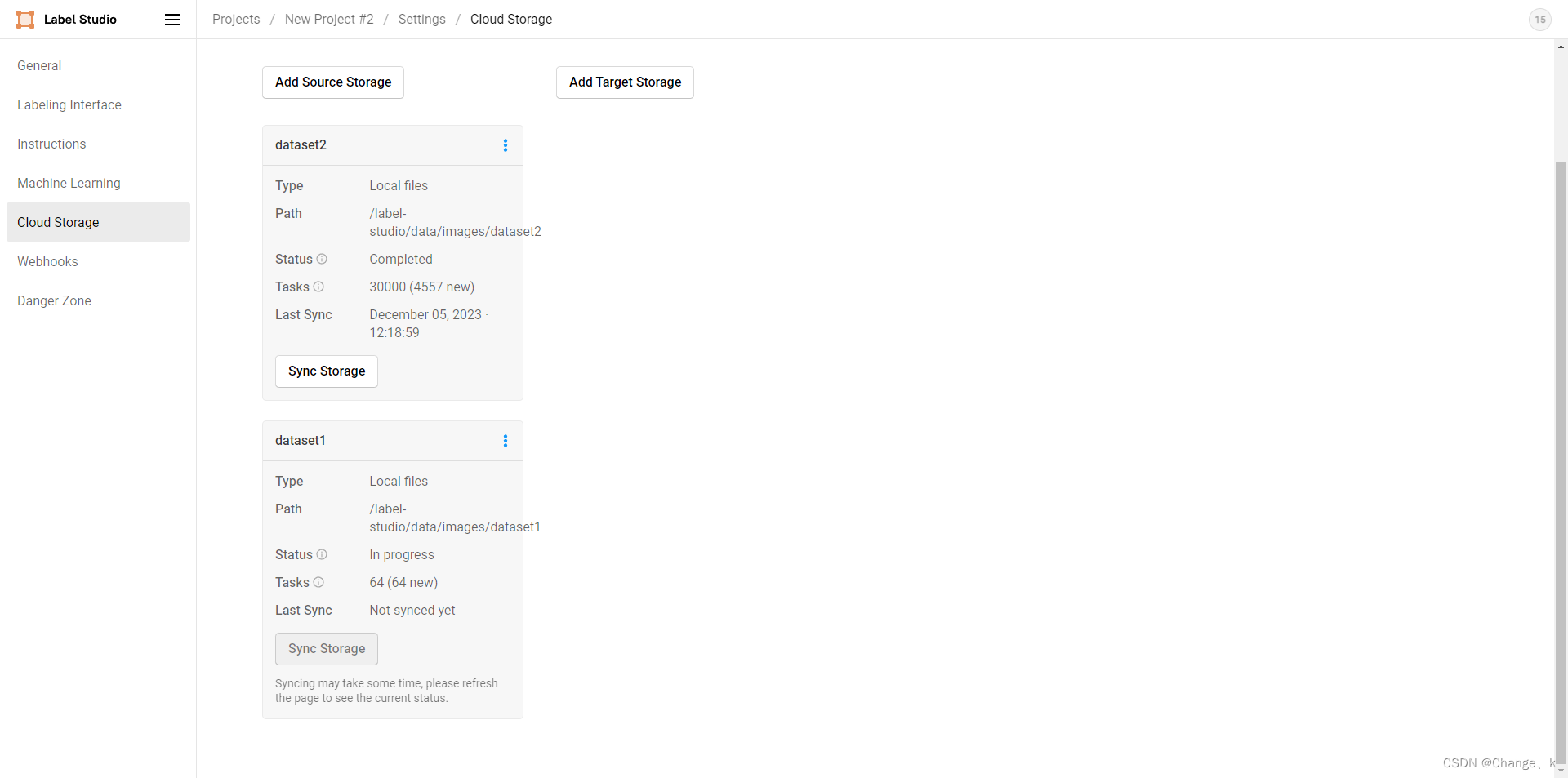
在加载的时候,不要进行数据标定,我尝试过标注,加载会中断。
四、结果展示
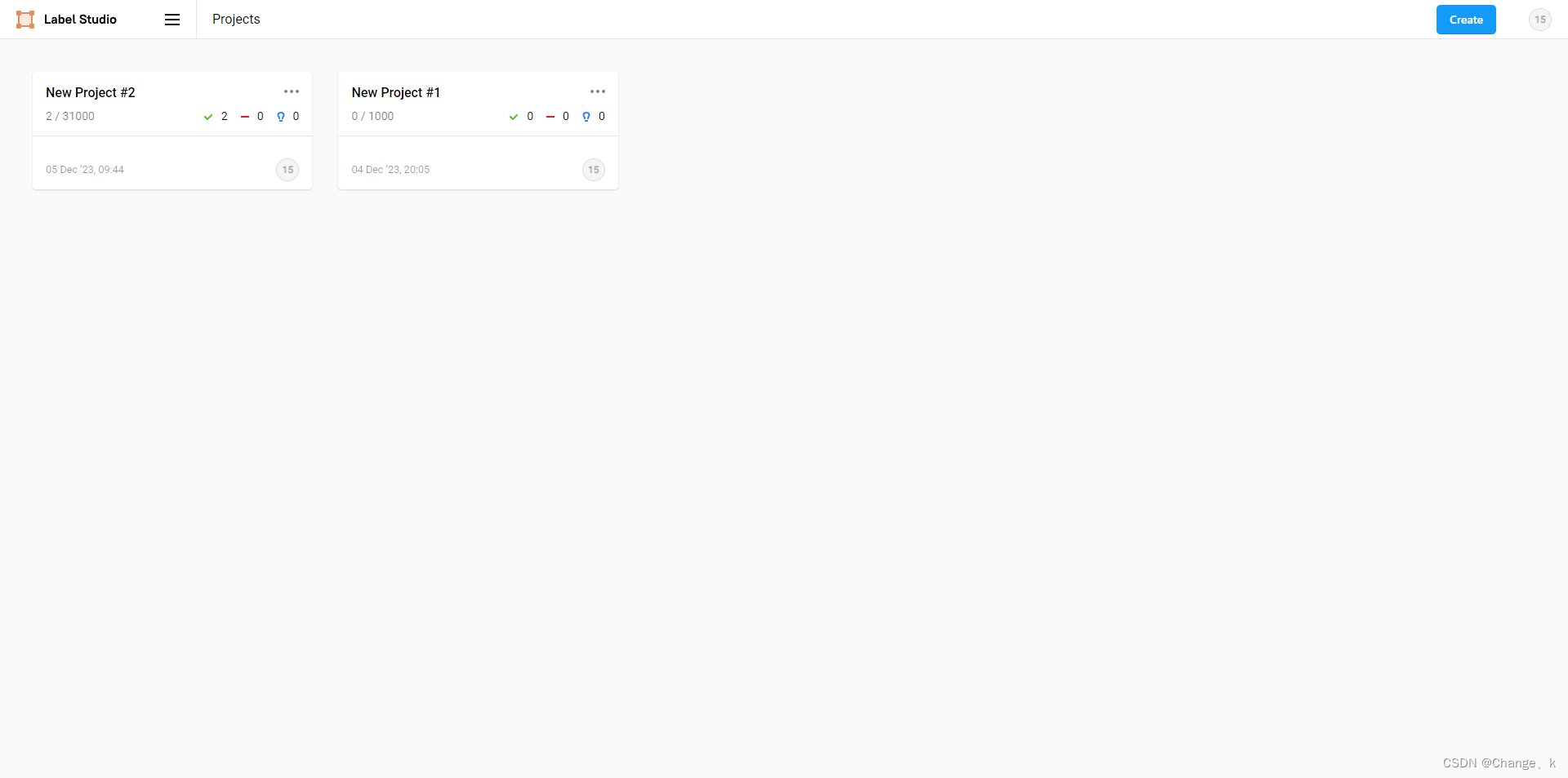
New Project #2从3w张图像变成了3.1w张
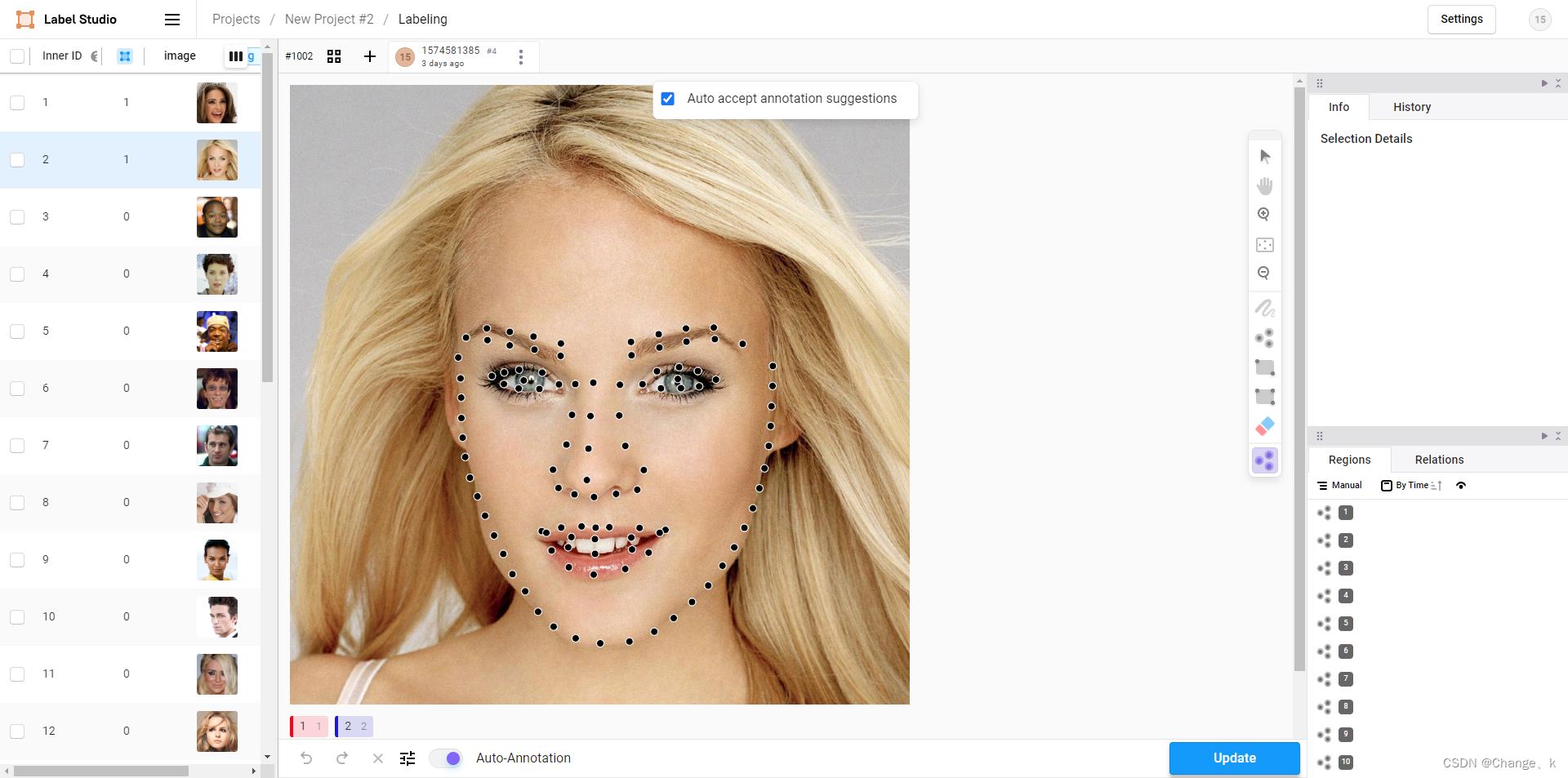
打开task能进行预测标注:
总结
注意路径匹配!

















 1717
1717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









