








-
人脸检测器的训练依赖标注,为了避免标注低光照人脸检测数据集,文章希望能够利用现有的低光照图片,来把人脸检测器从正常光照场景下迁移到低光照场景下。
-
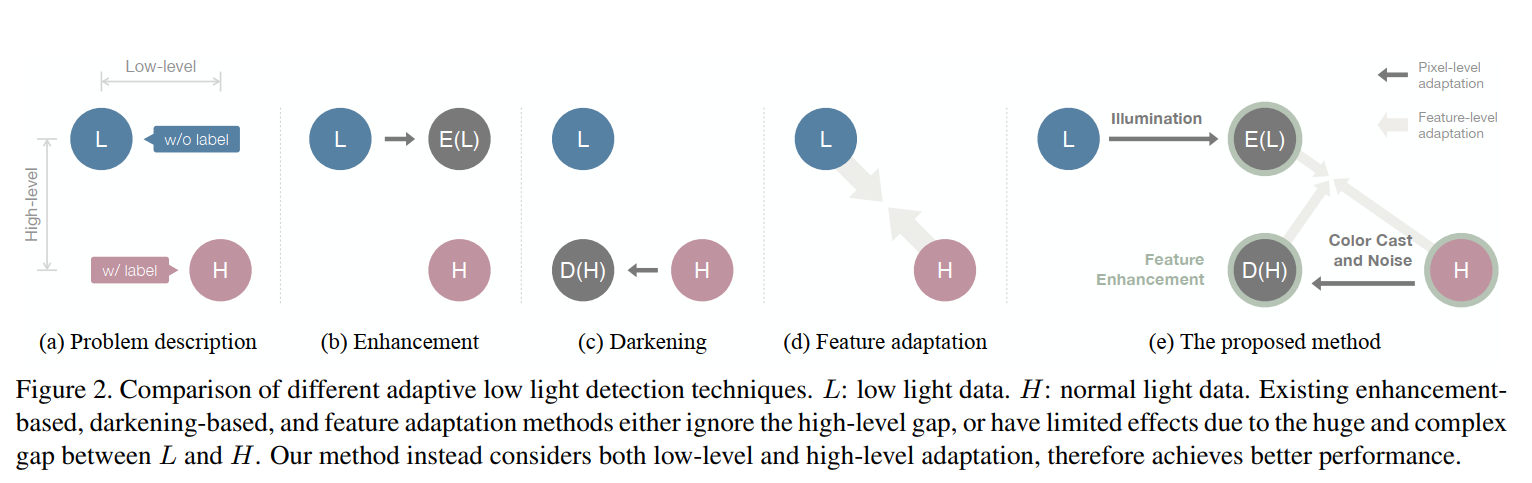
文章提到,正常光照图像和低光照图像存在两种gap,一种是pixel-level的gap,如亮度、噪声水平、色偏;一种是语义上的gap,如路灯、车灯、广告牌等。低光照图像质量增强算法设计的目的是提高视觉效果,无法填充语义上的gap;domain adptation 算法 可以进行domain的adapt,但是低光照图像和正常光照图像之间的gap太大了,提高了domain adaptation的难度。
-
为此文章提出了一种low light 和high light之间进行adapt并进行人脸检测的框架,这个框架接连进行low-level和high-level的adaptation。从low-level上,从low light adapt 到 hight light 或是反过来都太难了,文章则让两者双向奔赴,通过增亮暗图和对亮图进行降质,找到了两者之间的两个中间点。从 high-level上,使用了多任务自监督学习,进一步拉近这两个中间点。整个过程无需暗图上的人脸标注。整个过程大概如下最右边的图所示
-
因此文章三个创新点:
- 提出了一个无需暗图标注的暗图人脸检测框架
- 设计了一种双向的adaptation
- 设计了一种自监督学习的feature adaptation
Bidirectional Low-Level Adaptation
- 现有low-level 的 adaptation分为两种,一种是暗图增亮后用在亮图上训练的目标检测网络来检测;一种是亮图变暗后用来训练目标检测网络。但是这些low-level的adatptaiton存在两个挑战,
- 一个是high-level的gap是无法忽视的,这会影响这些pixel-level的transfer的模型的训练。
- 第二个挑战就是低光照图像质量增强本身就是一个难题。现有的算法都是设计为人类视觉考虑的,这些算法会产生黑边、保持噪声区域的低亮度、提高对比度,这些破坏了后续目标检测的准确率(没有给出证据我不是很认可,提高对比度为什么会破坏目标检测准确率)。文章还说DARK FACE的图像suffer from intensive noise and color bias,而现有去噪算法和颜色重建算法不够鲁棒以解决这些极端情况(还是没有给出证据)。
- 文章把暗图和亮图之间的gap分为三个因素:亮度、噪声、色偏。去噪和色偏校正是难的,但是加噪和加色偏相对容易,因此双向奔赴的双向就是,暗图用Zero-DCE调节亮度,亮图加噪和加色偏,这样得到的两张图像就能更接近。
- 暗图增强用的是Zero-DCE,但是把迭代次数和网络的宽度增加了,这是为了使得增强结果具有更高的亮度,虽然因此也放大了图像的噪声和色偏,但这可以交给双向奔赴的另一向来解决。这里通过增强网络 E E E,得到了 E ( L ) E(L) E(L)。
- 加噪用的是pix2pix(我不太认可,用网络加噪还是有点奇怪,噪声本身不是一种可预测的东西,用网络加噪就相当于在预测噪声,并且直接训练模型去生成噪声的这个优化过程理论上似乎并不能使得网络能够生成噪声)。pix2pix训练在 E ( L ) b l u r E(L)_{blur} E(L)blur和 E ( L ) E(L) E(L)的图像对上,并应用到 H H H上生成 H n o i s e H_{noise} Hnoise。其中 E ( L ) b l u r E(L)_{blur} E(L)blur是 E ( L ) E(L) E(L)加了 d = 25 , σ = 75 d=25,\sigma =75 d=25,σ=75的双边滤波器得到的图片。
- 加色偏:

Multi-Task High-Level Adaptation
- 用拼图游戏自监督训练来拉近E(L)和H的特征距离。拼图游戏指的是一个用于自监督预训练的分类任务,把一张完整的图像切分成3x3个=9个patch,以patch为输入,预测patch在图片中的位置。这里用了domain adaptation的技巧,把E(L)和H的patch对应的特征送进一个两domian共享权重的classification head。这样通过拼图游戏的自监督训练,网络能提取语义特征,并且由于使用共享权重的classification head进行训练,两个domain提取到的特征近似在相同的特征空间下,这样通过这个encoder就拉近了E(L)和H的语义特征距离(说是拉近,其实就是使得网络能够将图像映射到一个接近的特征空间上,接近的是特征而不是图片)。
- 用对比学习来拉近D(H)和H的特征距离。对比学习也是一种用于自监督预训练的分类任务,假设有两个domain,n对图片,每对图片是相互对应的,那么这n对图片在同一个网络各自提取的n对特征,其中每个特征应该可以和另一个domain的n个特征算n个距离(或者说相似度,一般直接点乘就行,点乘结果越大相似度越大,距离越小),这n个距离中,与与自己成对的特征之间的距离应该尽量小的,与其它n-1个特征之间的距离应该尽量大。对比学习的损失函数通过拉大不成对特征之间的距离和缩小成对特征之间的距离,使得网络能够忽视domian等底层视觉因素的影响而找到决定图像本质的语义信息,从而实现图像的配对。因此把D(H)和H当作两个domain的数据,在训练过程中的一个batch添加对比学习的损失,可以提高网络提取特征的domain-invariant的性质。
- 文章使用了两种对比学习,一种是取H的patch和D(H)的patch进行配对,一种是取自己的同一张图片的不同patch之间进行配对。
- 文章对E(L)的特征也进行了自对比学习,也就是上一条的第二点。
- 最终的损失函数就是上面三大点的损失以及目标检测损失的加权和,所以说是multi-task
完整的framework
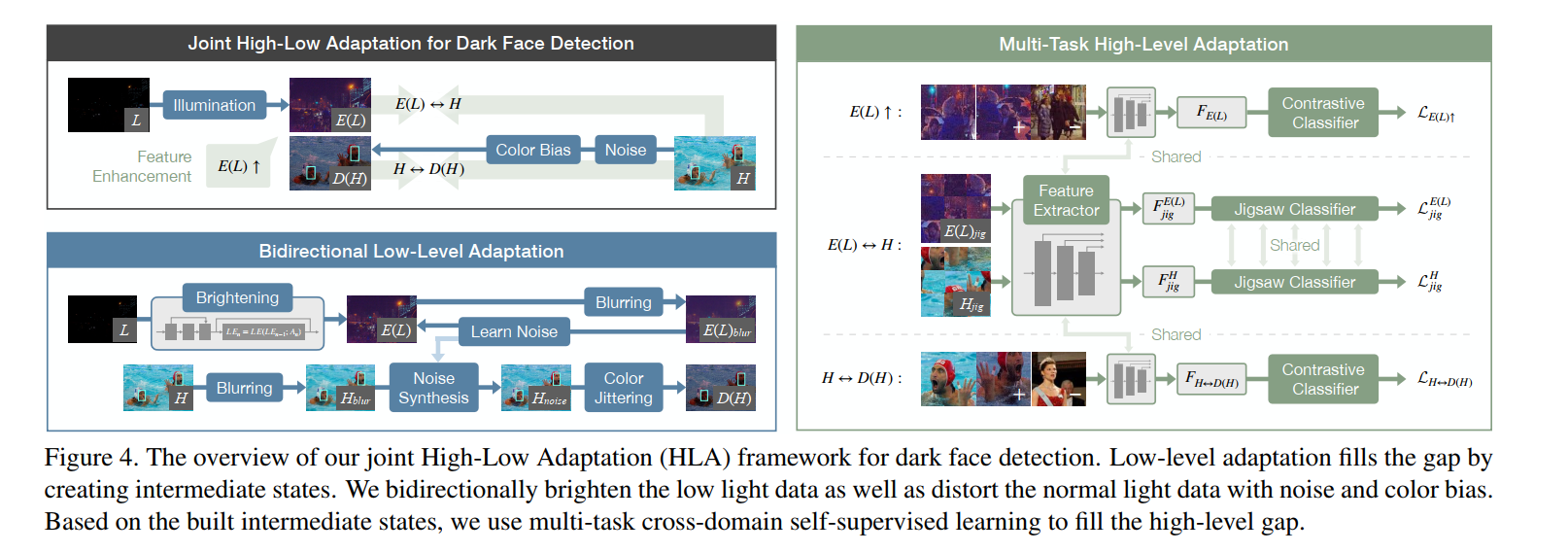
- 看完前面几个小节还是盲人摸象,完整的处理流程还是得看图。整个流程涉及的网络有三个,一个是加噪的网络pix2pix,一个是增亮的网络Zero-DCE,一个是右图的feature extractor。前面两个都好说,都是单独训练的,feature extractor其实是一个人脸检测网络DSFD,算对比学习损失的时候从DSFD网络backbone的第三到七层分别抽了5个特征图出来算的对比学习损失。所以这么多复杂的训练策略,最后测试阶段只需要用到E和以E(L)为输入的人脸检测网络DSFD,低光照图片经过先增强后检测的流程完成人脸检测。
实验结果
- 实验结果也是很有意思的,来看看:
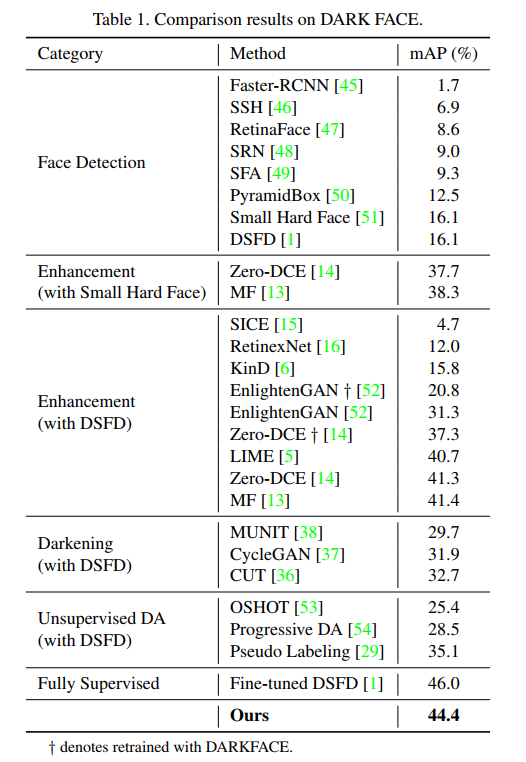
- 文章对比了几种检测流程,包括直接检测(在WIDER FACE上训练的目标检测和人脸检测模型)、先增强后检测、先变暗再训练、其它的无监督DA方法训练的DSFD、直接在Darkface上训练的DSFD、用本文提出的方法训练的DSFD。
- 我认为从这张表格可以得出非常多的信息:
- 首先,先增强后检测整体上都能提升暗图上目标检测的准确率(例外的是SICE、RetinexNet和KinD这三个算法,反而导致准确率下降了)。但是这个对比其实也不能说完全公平,因为增强模型的训练中,使用了DarkFace数据集,因此相比直接在WIDER FACE上训练并检测的模型,先增强后检测的流程具有数据上的优势。但这也是合理的,是具有实际应用价值的,实际生活中确实是可以方便地找到暗图数据集来训练增强模型。
- 其次,先变暗再训练,相比直接在WIDER FACE上训练的DSFD,具有更高的准确率,但是不如先增强后检测的流程。这实际上一方面确认了先变暗再训练是有意义的(因为能提高准确率),另一方面又展示了目前为止的方法中,先变暗再训练是没有应用价值的(因为使用了相同的数据集,先增强后检测明显具有更高的准确率)。
- 第三,用了无监督DA方法的DSFD,相比直接在WIDER FACE上训练的DSFD,具有更高的准确率,但还是不如先增强后检测的流程。道理同上一点。
- 第四,本文的方法超过了上述的所有方法,在相同数据集的情况下,比先增强后检测的性能还要高,所以本方法是具有应用价值的,确实是能够利用无标注的黑暗图像,提高暗图上人脸检测的准确率的。
- 最后,是一个打击点,提供了标注的话,直接在DarkFace上训练仍然是效果最好的。也就是说本文提了很多花里胡哨的方法,避免了对暗图上人脸检测标注的使用,并在这一条件下取得了最好的准确率,但是非常可惜的是,带标注的暗图数据集对准确率的提升仍然超过这些半监督的方法,本文并没有证明暗图标注的不必要性(目前为止给暗图进行标注仍然能够提供最好的准确率)














 4348
4348











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









