







机器学习实战 ——《跟着迪哥学Python数据分析与机器学习实战》(2)
接上文《机器学习技术栈 ——《跟着迪哥学Python数据分析与机器学习实战》(1)》
七、贝叶斯算法
关于贝叶斯算法,有太多文章讲的比我好,我不赘述,此处只放上我的一个总结,方便我之后索引记忆:《机器学习技术栈—— 概率学基础》,欲了解更多贝叶斯算法内容,请移步他处。
7.1 新闻分类任务实战
朴素贝叶斯(Native Bayes):假设变量之间是独立的。Naive Bayes classifier - wiki
用朴素贝叶斯方法,分辨垃圾邮件,但我发现下载下来的代码文件并没有包含数据集,所以我只看代码运行结果,没有去实际跑一遍。
7.1.1 结巴分词
pip install jieba
用以下代码可以做到分词
content_S = []
for line in content:
current_segment = jieba.lcut(line) #对每一篇文章进行分词, lcut = letter cut
if len(current_segment) > 1 and current_segment != '\r\n': #换行符
content_S.append(current_segment) #保存分词的结果
7.1.2 词云表示工具包wordcloud
7.1.3 TF-IDF特征
经过清洗之后,剩下的都是稍微有价值的词,但是这些词的重要程度不一定相同,可以这样定义重要程度
(1)如果一个词在整个语料库中(可以当作是在所有文章中)出现的次数都很高(这篇文章有它,另一篇还有这个词),那么这个词的重要程度就不高,因为它更像一个通用词
(2)如果另一个词在整体的语料库中的词频很低,但是在这一篇文章中却大量出现,就有理由认为它在这篇文章中很重要
T
F
−
I
D
F
=
词频
(
T
F
)
∗
逆文档频率
(
I
D
F
)
TF-IDF = 词频(TF)*逆文档频率(IDF)
TF−IDF=词频(TF)∗逆文档频率(IDF)
词频
(
T
F
)
=
某个词在文章中出现的次数
文章的总词数
词频(TF) = \frac{某个词在文章中出现的次数}{文章的总词数}
词频(TF)=文章的总词数某个词在文章中出现的次数
逆文档频率
(
I
D
F
)
=
l
o
g
(
语料库的文档总数
包含该词的文档数
+
1
)
逆文档频率(IDF) = log(\frac{语料库的文档总数}{包含该词的文档数+1})
逆文档频率(IDF)=log(包含该词的文档数+1语料库的文档总数)
看
I
D
F
IDF
IDF,包含该词的文档数越少,就会导致分母减小,从而导致
I
D
F
IDF
IDF增大,说明出现了该词的文档非常重要,加1是为了防止分母为0。
八、聚类算法
聚类算法是一种典型的无监督学习算法,但要说这是完全的无监督,似乎也不成立,因为还得首先知道“人以类聚,物以群分”的朴素道理,不知道这个道理,也无法推导出聚类算法。
人类的无师自通式的无监督,是先从劳动中总结归纳出文字符号系统,即,从最原始的物与物的相互作用,A作用于B,归纳出“名词-动词-名词”体系,然后再有各种副词,形容词去丰富这个体系,一个语言系统中,最原始的部分应该就是简单句,比如说“我爱你”,就符合“名词-动词-名词”体系,然后有了这套文字符号系统后,再表达出早已观察到的“人以类聚,物以群分”。
但是计算机的无监督,是先有了“人以类聚,物以群分”这套算法,然后再进行聚类分析,要学会如何学习,涉及到的领域是元学习(Meta Learning),这张图表示的很清楚
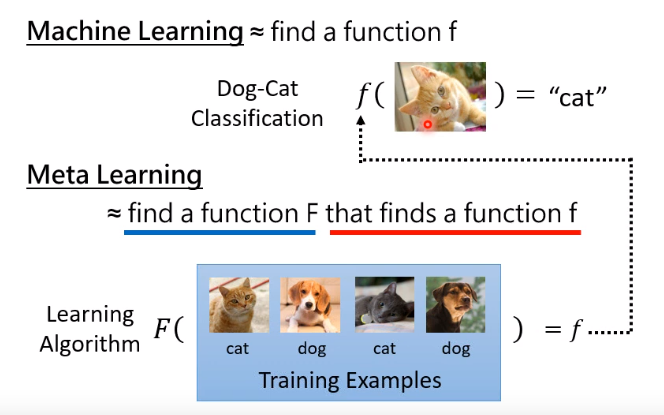
| Meta learning参考文章 |
|---|
| Meta-learning - wiki |
| 《Meta Learning 简介》- 知乎 |
8.1 K-means K-均值聚类算法
评估指标
轮廓系数(Silhouette Coefficient)是聚类效果好坏的一种评价方式,也是最常用的评估方法。
| Silhouette Coefficient参考文章 |
|---|
| 《聚类效果评估指标总结》 |
| Silhouette - wiki |
优缺点
| 优点 | 缺点 |
|---|---|
| 1.快速、简单,概括来说就是很通用的算法。 | 1.在K-means算法中,K是事先给定的,这个K值是非常难以估计的。很多时候,事先并不知道给定的数据集应该分成多少个类别才合适。《kmeans算法的k值选择》 |
| 2.聚类效果通常还是不错的,可以自己指定划分的类别数。 | 2.初始质心点的选择有待改进,可能会出现不同的结果。 |
| 3.可解释性较强,每一步做了什么都在掌控之中。 | 3.在球形簇上表现效果非常好,但是其他类型簇中效果一般。 |
8.2 DBSCAN(Density-Based Spatial Clustering of Applications with Noise)基于密度的聚类算法
总结:规定好发展的范围 ε \varepsilon ε与规模 M i n P t s MinPts MinPts,各自发展下线,没有符合的目标就停止。遇到无监督问题时,记得这个算法。

优缺点
| 优点 | 缺点 |
|---|---|
| 1.可以对任意形状的稠密数据集进行聚类,而K-means之类的聚类算法一般只适用于球状数据集 | 1.如果样本集的密度不均匀、聚类间距差相差很大时,聚类效果较差 |
| 2.非常适合检测任务,寻找离群点 | 2.半径的选择比较难,不同半径的结果差异非常大 |
| 3.不需要手动指定聚类的堆数,实际中也很难知道大致的堆数 |
九、神经网络基础
机器学习与深度学习最大的区别在于,是否需要特征工程。
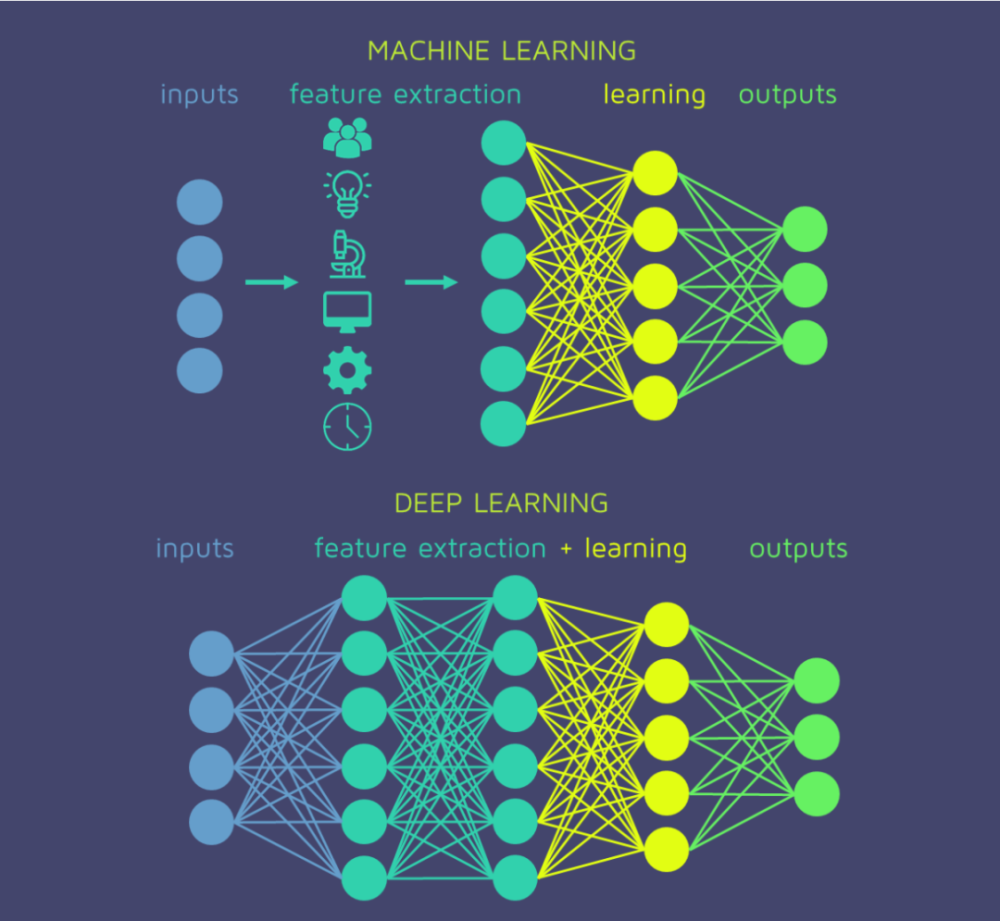
书曰:“能用逻辑回归解决的问题根本没有必要拿到神经网络中”,这是因为神经网络的过拟合问题较为严重,训练时间也较长,事情总是能简单就别复杂,不存在例外,如果有例外,那就是描述事物的基本原理还没摸透,基本原理错了,再怎么演变也是错的。
9.1 计算机眼中的图像
图像在计算机中是以矩阵形式存储的,以RGB图像为例,是以300×100×3的形式存储在计算机中,即
L
e
n
g
t
h
∗
W
i
d
t
h
∗
C
o
l
o
r
s
Length*Width*Colors
Length∗Width∗Colors,图像识别中常见的问题之一遮蔽现象,比如戴口罩
书曰:“一个特定类别对应一组权重参数,十分类对应十组权重参数,最终结果由
w
w
w来控制,偏置参数
b
b
b只是进行微调,如果是十分类任务,各自类别都需要进行微调,也就是需要10个偏置参数。”
损失函数
L
i
=
∑
j
≠
y
i
m
a
x
(
0
,
s
j
−
s
y
i
+
Δ
)
L_{i} = \sum_{j \neq y_i}{max(0, s_j - s_{y_i} + \Delta)}
Li=j=yi∑max(0,sj−syi+Δ)
其中
L
i
L_i
Li为:当前输入数据属于正确类别的得分值(即
s
y
j
s_{y_j}
syj)与其他所有错误类别得分值(即
s
j
s_j
sj)的差异总和,当
s
j
−
s
y
i
+
Δ
<
0
s_j - s{y_i} + \Delta < 0
sj−syi+Δ<0时,表示没有损失,当
s
j
−
s
y
i
+
Δ
>
0
s_j - s{y_i} + \Delta > 0
sj−syi+Δ>0时,表示开始计算损失,
Δ
\Delta
Δ代表容忍度。
模型最终的损失值,是有大量测试图像结果的平均值决定的
L
i
=
1
N
∑
i
=
1
N
∑
j
≠
y
i
m
a
x
(
0
,
s
j
−
s
y
i
+
Δ
)
L_{i} = \frac{1}{N} \sum_{i=1}^{N}{ \sum_{j \neq y_i}{max(0, s_j - s_{y_i} + \Delta ) }}
Li=N1i=1∑Nj=yi∑max(0,sj−syi+Δ)
9.2 dropout
为了降低过拟合风险,在每一次训练迭代过程中随机杀死一部分神经元,每次迭代都进行随机选择,测试阶段依旧可以使用完整的神经网络架构,
十、Tensorflow
书曰:“Tensorflow就是 张量(Tensor)以在计算图(Graph)上流动(Flow)的方式的实现和执行机器学习算法 的框架,它是一个基于数据流图的科学计算库,而非仅仅是机器学习库”。
10.1 Tensorflow基本用法
Tensorflow操作流程总结
(1) 创建变量
(2) 创建操作
(3) 全局变量初始化
(4) 创建Session(),最后sess.run(),只有完成这一步,才能真正得到最终结果。
a = 3
# (1)创建变量
w = tf.Variable([[0.5,1.0]]) # row vector 1*2
x = tf.Variable([[2.0],[1.0]]) # col vector 2*1
# (2)创建操作
y = tf.matmul(w, x)
# (3)全局变量初始化
init_op = tf.compat.v1.global_variables_initializer()
with tf.compat.v1.Session() as sess:
tf.compat.v1.disable_eager_execution() # Added by lyp at 2023-11-25
# (4)sess.run()
sess.run(init_op)
print (y.eval())
10.2 用Keras搭建神经网络
关于如何用Tensorflow搭建神经网络,我之前在微信公众号中写过一篇文章,使用的是Keras,而Keras已经被吸收成为Tensorflow的一部分了,所以用Keras搭建神经网络是必须要掌握的
| 参考文章 |
|---|
| 《用Keras搭建神经网络》—— 微信公众号 |
10.3 Tensorflow经典实战项目
//@TODO,网上都说初学者无脑入手pytorch,这方面的实战项目后期有需要再补充。
十一、CNN卷积神经网络
书曰:“神经网络的本质是对数据特征进行提取,卷积神经网络也是神经网络的一种,只不过在图像数据中效果更好”。
11.1 CNN原理与术语
MLP是一种全连接神经网络,CNN也是一种全连接神经网络。并且,MLP的矩阵计算方式所需参数过于庞大,一方面使得迭代速度很慢,另一方面过拟合问题比较严重,而CNN便可以更好地处理这个问题。
| 术语 | 定义 | 解释 |
|---|---|---|
| 卷积核 | Kernel (image processing) - wiki 《【低层视觉】低层视觉中常见的卷积核汇总》- 知乎 | 卷积是寻找特征 |
| 池化层 | 池化是压缩数据 | |
| 激活层 | 激活是加强特征 | |
| 参数共享 | 对所有区域使用相同的卷积核计算特征 |
看到Wiki百科中,关于卷积核运算的操作,其实是有点奇怪的,它并非平常想象的矩阵元素一一对应相乘,而有一种元素下标相加回归到矩阵中心位置的特点,即旋转了180°后再一一对应相乘,单纯从计算机角度出发,你找不到任何解释的意义,反正都是矩阵元素相乘,所以只是数学上的定义是如此,实际的深度学习中没必要翻转,所以不同的书本在这里有不同的定义,有些书本不提翻转也是对的。
| 参考视频或链接 |
|---|
| 【图解,卷积神经网络(CNN可视化)】- bilibili |
| Convolutional neural network - wiki |
| 《深度学习笔记(一):卷积神经网络CNN》 |
| 《在定义卷积时为什么要对其中一个函数进行翻转?》- 知乎 |
| 《卷积神经网络图像处理卷积时,为啥要旋转180°?》 |
11.2 CNN的原始论文、改进与扩展
论文.pdf | 相关代码实现 |
|---|---|
| CNN原始论文:Gradient-based learning applied to document recognition.pdf | |
| FastCNN | |
| RCNN原始论文:Rich feature hierarchies for accurate object detection and semantic segmentation.pdf | |
| FasterRCNN |
对CNN的改进的讨论见://@TODO文章撰写中
11.3 CNN实战项目
| 项目链接 |
|---|
| 《深度学习实战项目 - 验证码识别》—— starryrbs |
| 《深度学习-PyTorch框架》—— 唐宇迪 |
十二、RNN递归神经网络
RNN适合用来处理不定长的序列化数据,但在处理序列较长的数据时,性能会降低,因为距离过于遥远的信息会有损失,因此有LSTM(long short-term memory)长短期记忆模型。
12.1 RNN原理与术语
RNN的结构为:

计算公式为:
h
t
=
f
1
(
U
X
t
+
V
h
t
−
1
+
b
)
L
t
=
f
2
(
W
h
t
)
h_t = f_1(UX_t + Vh_{t-1} + b) \\ L_t = f_2(Wh_t)
ht=f1(UXt+Vht−1+b)Lt=f2(Wht)
f
i
(
⋅
)
f_i(·)
fi(⋅)是激活函数,通常为
t
a
n
h
tanh
tanh,
b
b
b是偏置项
| 术语 | 定义 | 解释 |
|---|---|---|
| 多对一任务 | 输入是一个向量序列,输出是一个向量 | 常应用在情感分析上 |
| 一对多任务 | 输入是一个向量,输出是一个向量序列 | 如图像描述(image captioning)任务,输入是一幅图片,输出是一段话 |
| 多对多任务 | 输入是一个向量序列,输出是一个向量序列,因此也称为序列到序列(sequence to sequence,seq2seq)问题 | 常用在语音识别与机器翻译中 |
| 参考视频或链接 |
|---|
| 【循环神经网络】5分钟搞懂RNN,3D动画深入浅出 - bilibili |
| 55 循环神经网络 RNN 的实现【动手学深度学习v2】 - bilibili |
| Recurrent Neural Networks cheatsheet - Standford CS 230 |
12.2 RNN的原始论文、改进与扩展
论文.pdf | 相关代码 |
|---|---|
| RNN原始论文:Finding Structure in Time | |
12.3 RNN实战项目
12.4 LSTM网络
LSTM是RNN的一个改进,基本构造与RNN一致。

计算公式为
F
t
=
σ
(
X
t
W
x
f
+
H
t
−
1
W
h
f
+
b
f
)
I
t
=
σ
(
X
t
W
x
i
+
H
t
−
1
W
h
i
+
b
i
)
O
t
=
σ
(
X
t
W
x
o
+
H
t
−
1
W
h
o
+
b
o
)
C
t
~
=
t
a
n
h
(
X
t
W
x
c
+
H
t
−
1
W
h
c
+
b
c
)
C
t
=
F
t
⊙
C
t
−
1
+
I
t
⊙
C
t
~
H
t
=
O
t
⊙
t
a
n
h
(
C
t
)
F_t =\sigma(X_tW_{xf} + H_{t-1}W_{hf} + b_f) \\ I_t = \sigma(X_tW_{xi} + H_{t-1}W_{hi} + b_i) \\ O_t =\sigma(X_tW_{xo} + H_{t-1}W_{ho} + b_o) \\ \tilde{C_t} = tanh(X_tW_{xc} + H_{t-1}W_{hc} + b_c) \\ C_t = F_t \odot C_{t-1} + I_t \odot \tilde{C_t} \\ H_t = O_t \odot tanh(C_{t} )
Ft=σ(XtWxf+Ht−1Whf+bf)It=σ(XtWxi+Ht−1Whi+bi)Ot=σ(XtWxo+Ht−1Who+bo)Ct~=tanh(XtWxc+Ht−1Whc+bc)Ct=Ft⊙Ct−1+It⊙Ct~Ht=Ot⊙tanh(Ct)
其中
X
t
∈
R
n
×
d
X_t \in \mathbb{R}^{n \times d}
Xt∈Rn×d
H
t
−
1
∈
R
n
×
h
H_{t-1} \in \mathbb{R}^{n \times h}
Ht−1∈Rn×h
F
t
−
1
,
I
t
−
1
,
O
t
−
1
,
C
t
~
∈
R
n
×
h
F_{t-1}, I_{t-1}, O_{t-1},\tilde {C_{t}} \in \mathbb{R}^{n \times h}
Ft−1,It−1,Ot−1,Ct~∈Rn×h
W
x
f
,
W
x
i
,
W
x
o
,
W
x
c
∈
R
d
×
h
W_{xf},W_{xi},W_{xo},W_{xc} \in \mathbb{R}^{d \times h}
Wxf,Wxi,Wxo,Wxc∈Rd×h
W
h
f
,
W
h
i
,
W
h
o
,
W
h
c
∈
R
h
×
h
W_{hf},W_{hi},W_{ho},W_{hc} \in \mathbb{R}^{h \times h}
Whf,Whi,Who,Whc∈Rh×h
b
f
,
b
i
,
b
o
,
b
c
∈
R
1
×
h
b_f,b_i,b_o,b_c \in \mathbb{R}^{1 \times h}
bf,bi,bo,bc∈R1×h
σ
(
⋅
)
\sigma(\cdot)
σ(⋅)是激活函数
n
n
n是样本的batch size
d
d
d是样本输入的维度
h
h
h是隐藏层的节点数
| 参考视频或链接 |
|---|
| 10.1. Long Short-Term Memory (LSTM) - d2l |
| 《超简单理解LSTM和GRU模型,深度学习入门》- bilibili |
12.4.1 LSTM的原始论文、改进与扩展
论文.pdf | 相关代码 |
|---|---|
十三、影评情感分析
13.1 word2vec模型
书曰:“如果用词袋模型和TF-IDF方法计算整个文本向量,比较难得到好的效果,若文章比较长的话,另外RNN本身的输入要求,需要将句子分解成一个个的词语,每个词语是一个输入,因此,每一个词都需要转换成相应的特征向量,而且维度必须一致,这里的向量不能是简单的词频统计,而是需要有实际的含义。如果基于统计的方法来制作向量,love和adore是两个完全不同的向量,因为统计的方法很难考虑词语本身以及上下文的含义,如果用词向量模型(word2vec)来制作,结果就大不相同。相似的词语在向量空间上也会非常类似,这才是希望得到的结果” 。
那如何得到这样的向量?
书曰:“根据上下文预测某一个中间词,或根据中间词预测上下文,如果预测的结果是比较接近的,那么这两个词的向量就应该是比较接近的,最终通过神经网络不断迭代,以训练出每一个词向量结果”。
这个训练过程,用到了两个模型:CBoW(Continuous bag-of-words,根据上下文预测目标词)与 Skip-Gram(Continuous skip-gram,根据目标词预测上下文),请看下面的参考视频或文章链接。
| 参考视频或文章链接 |
|---|
| 【清华NLP】刘知远团队大模型公开课全网首发|带你从入门到实战 - 2-5词向量:Word2vec |
十四、三巨头的由来
深度学习三巨头分别是:“Geoffrey Hinton、Yann Lecun、Yoshua Bengio”,他们共同获得了2018年的Turing Award(图灵奖),我想这是对三巨头提法的一种认可,甚至我们可以追溯三巨头提法的来源,是不是2018年ACM授奖以后才正式有三巨头的提法,2018年以前有没有这种提法?
| 人物 | ACM委员会认为的主要贡献 | 头像 |
|---|---|---|
| Geoffrey Hinton | BP反向传播算法 玻尔兹曼机 对卷积神经网络的修正 |  |
| Yann Lecun | CNN神经网络 改进反向传播算法 拓宽神经网络的视角 |  |
| Yoshua Bengio | 序列的概率建模 高维词嵌入与注意力机制 生成对抗网络(GAN) |  |














 1599
1599











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









