






优化方法
梯度下降法
求最小化损失函数
J
(
θ
)
J(\theta)
J(θ)。
算法思想:对当前值
θ
\theta
θ,计算
J
(
θ
)
J(\theta)
J(θ)梯度,沿着梯度负方向前进一小步,重复进行直到到达最低点(Minimum)。

梯度下降更新方程(矩阵表示):
θ
n
e
w
=
θ
o
l
d
−
α
▽
θ
J
(
θ
)
\theta ^{new} = \theta ^{old}-\alpha \triangledown_\theta J(\theta)
θnew=θold−α▽θJ(θ)
α
\alpha
α为学习率或学习步长
梯度下降更新方程(单值表示):
θ
j
n
e
w
=
θ
j
o
l
d
−
α
∂
∂
θ
j
o
l
d
J
(
θ
)
\theta ^{new}_j = \theta ^{old}_j-\alpha \frac {\partial}{\partial \theta ^{old}_j }J(\theta)
θjnew=θjold−α∂θjold∂J(θ)
算法:
while True:
theta_grad = evaluate_gradient(J, corpus, theta)
theta = theta - alpha * theta_grad
随机梯度下降法
与梯度下降法不同,梯度下降法是把所有的样本都迭代一遍,但当样本窗口大小是整个语料库的时候,求
▽
θ
J
(
θ
)
\triangledown_\theta J(\theta)
▽θJ(θ)计算就会非常巨大,每更新一次需要耗费太多时间。
随机梯度法思想:从样本中随机抽出一组,训练后按梯度更新一次,然后再抽取一组,再更新一次,在样本量及其大的情况下,可能不用训练完所有的样本就可以获得一个损失值在可接受范围之内的模型。
算法:
while True:
window = sample_window(corpus)
theta_grad = evaluate_gradient(J,window,theta)
theta = theta-alpa * theta_grad
带有词向量的随机梯度(Stochasticgradients with word vectors)
在每一个窗口进行随机梯度下降计算,每个窗口最多只有2m+1个单词,所形成的矩阵就会非常稀疏。只需要更新实际训练中出现的单词向量。
▽
θ
J
t
(
θ
)
=
[
0
⋮
▽
v
l
i
k
e
⋮
0
▽
u
I
⋮
▽
u
l
e
a
r
l
i
n
g
⋮
]
∈
R
2
d
V
\triangledown_{\theta }J_{t}(\theta)=\begin{bmatrix} 0\\ \vdots \\ \triangledown _{v_{like}}\\ \vdots \\ 0\\ \triangledown _{u_{I}}\\ \vdots\\ \triangledown_{u_{learling}}\\ \vdots \end{bmatrix}\in \mathbb{R}^{2dV}
▽θJt(θ)=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡0⋮▽vlike⋮0▽uI⋮▽ulearling⋮⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤∈R2dV
解决办法:1、进行稀疏矩阵操作,更新矩阵U和V特定的行。2、为每个词语建立到词向量的哈希映射。
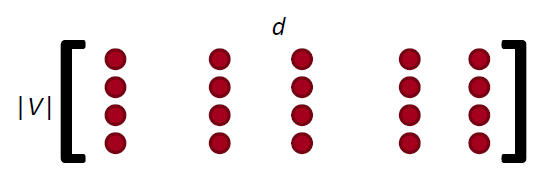
在有百万量级的词向量进行分布式计算时,不进行大量的更新是很重要的。
Word2vec两个模型区别
1.Skip-grams(SG):给定中心词,预测上下文;
2.Continuous Bag of Words(CBOW):根据上下文预测中心词。
负采样 skip-gram 模型:
P
(
o
∣
c
)
=
e
x
p
(
u
o
T
v
c
)
∑
w
∈
V
e
x
p
(
u
w
T
v
c
)
P(o|c) = \frac{exp(u_o^Tv_c)}{\sum_{w\in V}exp(u_w^Tv_c)}
P(o∣c)=∑w∈Vexp(uwTvc)exp(uoTvc)
标准化因子计算量太大,因此在作业中采集负样本的skip-gram模型。
Word2vect 之Skip-grams看这里在知乎上看到有介绍
为什么不直接获取同时出现(co-occurrence)发生的次数
使用一个共现矩阵(co-occurrencematrix):
两种选择:窗口(windows)或者全文档(full document)
•窗口:word2vec将窗口视作训练单位,在每个单词的周围使用窗口来捕获语法(POS)和语义信息,每个窗口或者几个窗口都要进行一次参数更新。并且很多词串出现的频次是很高的。能不能遍历一遍语料,迅速得到结果呢?
•早在word2vec之前,就已经出现了很多得到词向量的方法,这些方法是基于统计共现矩阵的方法。如果在窗口级别上统计词性和语义共现,可以得到相似的词。如果在文档级别上统计,则会得到相似的文档(潜在语义分析Latent Semantic Analysis)。
举例:
窗口长度为1(更常见的是5 - 10)
• 对称(不相关的左右语境)
• 在如下示例语料库中统计共现矩阵:
– I like deep learning.
– I like NLP.
– I enjoy flying.
可得到如下共现矩阵:

根据上述的共现矩阵,可以得到朴素共现向量。但是,会存在一些局限性:
• 随着词表词汇量的增加,维度是不断增加的。
• 非常高维:所以需要大量的存储空间。
• 随后的分类模型存在稀疏性问题,会导致模型不太健壮(less robust)
解决办法:低维向量
低维向量
• 想法:将“大部分”的重要信息存储在一个固定的,少量的维度中:使用一个密集的向量(a dense vector)。
• 通常是25 - 1000个维度,类似于word2vec。
• 问题:如何降维呢?
• 方法一:对(共现矩阵)进行降维。
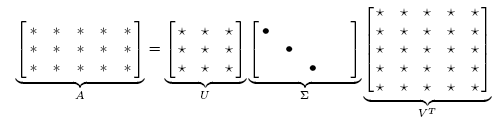
SVD:奇异值分解
把矩阵X分解成
U
Σ
V
T
U\Sigma V^T
UΣVT的形式,
U
U
U和
V
V
V是标准正交矩阵
python进行简单SVD操作
语料库:I like deep learning. I like NLP. I enjoy flying.

import numpy as np
la = np.linalg
words = ["I", "like","enjoy","deep", "learning","NLP","flying","."]
X = np.array([[0,2,1,0,0,0,0,0],
[2,0,0,1,0,1,0,0],
[1,0,0,0,0,0,1,0],
[0,1,0,0,1,0,0,0],
[0,0,0,1,0,0,0,1],
[0,1,0,0,0,0,0,1],
[0,0,1,0,0,0,0,1],
[0,0,0,0,1,1,1,0]])
U, s, Vh = la.svd(X, full_matrices=False)
降维之后,取奇异值最大的两列作为二维坐标可视化:

Combining the best of both worlds: GloVe
矩阵分解和Word2vec学习词向量的方式各有优劣。词共现矩阵:缺点:在词对推理任务上表现特别差;word2vec:缺点:无法使用全局信息。
GloVe同时学习者两种信息。
GloVe(Global Vectors for Word Representation)是斯坦福大学发表的一种word embedding 方法,GloVe: Global Vectors for Word Representation,它看起来很new,其实有着old school的内核。GloVe尝试借鉴NNLM和word2vec的优势来弥补旧方法的劣势,取得了不错的效果。
GloVe推导过程
https://blog.csdn.net/qq_37098526/article/details/89763064
如何评估词向量
有两种方法:Intrinsic(内部)和 extrinsic(外部)
Intrinsic:专门设计单独的试验,由人工标注词语或句子相似度,与模型结果对比。好处是是计算速度快,有助于理解系统。但不知道对实际应用有无帮助。
Extrinsic:通过对外部真实的实际应用的效果提升来体现。耗时较长,不能排除是否是新的词向量与旧系统的某种契合度产生。不清楚是子系统的问题,还是它的交互系统或其他子系统的问题。需要至少两个子系统同时证明。
- 内部评估:词向量类比(Word Vector Analogies)

. 通过对单词向量的余弦距离进行分析,可以得到直观的语义和句法类比问题。
. 从检索中丢弃输入的单词。

Glove可视化,会发现这些类推的向量都是近似平行的

详情参考
https://www.tinymind.net.cn/articles/ceb226ae470458















 2375
2375











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









