







- Image Super-Resolution Using Very Deep Residual Channel Attention Networks
- 使用非常深的残差通道注意力网络的图像超分辨率
- In: ECCV. (2018)
- Zhang, Y., Li, K., Li, K., Wang, L., Zhong, B., Fu, Y.
链接:
摘要
- 首先说明了为什么更深的网络对SR是更难训练的?
- 因为低分辨率的输入和特征包含丰富的低频信息,这些信息在通道之间被平等对待,从而阻碍了 CNN 的表示能力。
- 然后提出了RCAN(the very deep residual channel attention networks):
- 提出了一种==RIR(residual in residual)==结构,来形成非常深的网络:
- RIR由多个具有长跳跃连接(LSC)的残差组(RG)组成:
- 每个GP中,包含一些具有短跳跃连接(SSC)的残差块(RB)。
- RIR允许多个跳跃连接绕过丰富的低频信息,使网络专注于学习高频信息。
- RIR由多个具有长跳跃连接(LSC)的残差组(RG)组成:
- 提出了一种==CA(channel attention)==机制:
- CA通过考虑通道之间的相互依赖性,来自适应地重新调整通道特征。
- 提出了一种==RIR(residual in residual)==结构,来形成非常深的网络:
- 最后通过大量实验表明,RCAN达到了SOTA,实现了更好的准确性和视觉改进。
1 引言
- SR问题通常是指SISR、并且应用广泛、是一个不适定性问题:
- (任何LR图像输入都存在多种解决方案,因此提出了许多基于学习的方法来学习LR和HR图像对之间的映射)。
- 简单介绍了CNN用于SR问题的发展历程,来表明网络深度对SR的有效性:
- Dong等人首先引入了用于图像SR的三层CNN,提出了SRCNN。
- Kim等人在VDSR和DRCN中将网络深度增加到20层。
- 在He等人提出残差网络(ResNet)后,这种有效的残差学习策略被引入到许多其他基于 CNN 的图像 SR 方法中。
- Lim等人通过使用简化的残差块构建了一个非常宽的网络(EDSR)和一个非常深的MDSR(大约165层)。
- 说明当前的基于CNN的SR技术的缺点:
- 平等对待通道特征,在处理不同类型的信息(高频和低频信息)时缺乏灵活性。
- 平等对待每个通道特征的缺点:
- 会浪费大量低频特征的不必要的计算
- 缺乏跨特征通道的判别学习能力,
- 最终阻碍深度网络的表示能力。
并强调:
- 可以将SR技术看作是尝试恢复尽可能多的高频信息的过程。
- LR图像包含大部分低频信息,这些低频信息可以直接转向最终的HR输出,不需要太多计算。
- 提出了残差通道注意力网络(RCAN):
- 目的:
- 来获得非常深的网络,并同时自适应地学习更多有用的通道特征。
- 提出了residual in residual(RIR)结构:
- 目的:
- 为了简化非常深的网路的训练。
- 其中,残差组(residual group,RG)作为基本模块,长跳跃连接(long skip connection, LSC)允许粗略水平(coarse level)的残差学习。在每一个RG模块中,使用短跳跃连接(short skip connection, SSC)堆叠了几个简化的残差块,这样做的优势:
- 长和短的跳跃连接以及残差块中的快捷方式允许通过这些 identity-based skip connection 绕过丰富的低频信息,从而可以简化信息的流动。
- 进一步,提出了通道注意力(channel attention,CA)机制:
- 目的:
- 通过对特征通道之间的相互依赖性进行建模,来自适应地重新调整每个通道特征。
- 优势:
- CA允许网络去集中于更有用的通道
- CA使网络增强判别学习的能力
- 目的:
- 目的:
- 目的:
- 总结三点贡献:
- 提出了非常深的残差通道注意力网络(RCAN),用于高精度的图像SR;
- 相较于CNN的SR,RCAN有更深的网络,获得得更好的性能。
- 提出了residual in residual结构(RIR),来构建更深的训练网络;
- RIR中的LSC和SSC,有助于绕过丰富的低频信息,使主网络学习到更有效的信息。
- 提出了通道注意力机制(CA),通过考虑特征通道之间的相互依赖性来自适应的重新缩放特征。
- CA机制进一步提高了网络的表征能力。
- 提出了非常深的残差通道注意力网络(RCAN),用于高精度的图像SR;
2 相关工作
- 目前CV已经有很多SR方法。虽然CA在high-level vision tasks很流行,但是在low-level视觉应用很少。相关工作主要介绍基于CNN的SR和CA相关的工作。
- Deep CNN for SR:
- 第一类方法:首先将 LR 输入插值到所需的大小,这不可避免地会丢失一些细节并大大增加计算量。
- 开创性的工作是由 Dong 等人在2014年完成的,他们提出了用于图像 SR 的 SRCNN,并取得了优于之前工作的性能。
- Kim等人在2016年通过引入残差学习来缓解训练难度,提出了20层的VDSR和DRCN,并取得了精度的显着提升。
- 2017年,Tai 等人后来在DRRN 中引入了递归块,在 MemNet中引入了内存块。
- 第二类方法:从原始 LR 输入中提取特征并在网络尾部提升空间分辨率,这种方法成为深度架构的主要选择。
4. Dong等人在2016年提出了一种更快的网络结构FSRCNN来加速SRCNN的训练和测试。
5. Ledig 等人在2017年引入了 ResNet 来构建更深层次的网络 SRResNet,用于图像 SR。他们还提出了具有感知损失和生成对抗网络 (GAN) 的 SRGAN,以实现photo-realistic SR。
6. 随后,在2017年的EnhanceNet中引入了这种基于 GAN 的模型,该模型结合了自动纹理合成和感知损失。尽管SRGAN和Enhancenet可以在一定程度上减轻模糊和过度平滑伪影,但它们的预测结果可能无法忠实地重建并产生令人不快的伪影。
7. Lim等人在2017年通过删除传统残差网络中不必要的模块,提出了EDSR和MDSR,取得了显着的改进。
- 第一类方法:首先将 LR 输入插值到所需的大小,这不可避免地会丢失一些细节并大大增加计算量。
- Attention mechanism:
- 一般来说,注意力可以被视为一种指导,将可用处理资源的分配偏向于输入中信息最丰富的部分。
- 它通常与门函数(例如 sigmoid)结合使用来重新缩放特征图。
- 注意力机制大多用于CNN的high-level视觉任务:
- Wang等人在2017年提出了具有主干和掩模(trunk-and-mask, TM)注意机制的用于图像分类的残差注意力网络。
- Hu 等人在2017年提出了挤压和激励(Squeze-and-excitation, SE)块来建模通道关系,以获得图像分类的显着性能改进。
- 很少有人提出研究注意力对低级视觉任务(例如图像 SR)的影响。
- 再次强调:
- 在图像 SR 中,高频通道特征对于 HR 重建来说信息量更大。
- 如果我们的网络更多地关注这种通道方面的特征,那么应该有望获得改进。
- 为了研究非常深的 CNN 中的这种机制,本文提出了非常深的残差通道注意网络(RCAN)。
3 RCAN
3.1 网络结构
RCAN主要由四部分组成:
- 浅层特征提取模块、RIR深层特征提取模块、上采样模块、重构模块。
- 其中,除了RIR深层特征提取模块,其他三个模块均和EDSR与RDN中的保持一致。
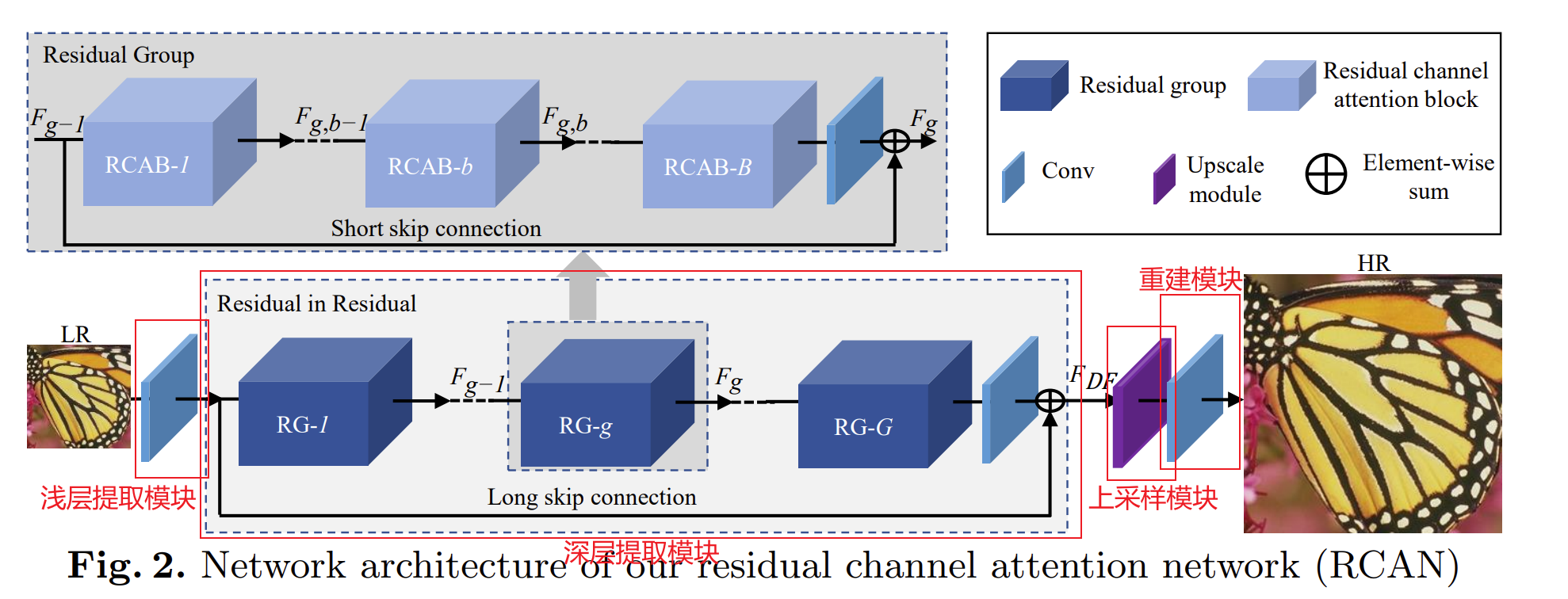
- 其中,除了RIR深层特征提取模块,其他三个模块均和EDSR与RDN中的保持一致。
- 浅层特征提取模块:
- 仅使用一个卷积层去提取浅层特征。
- 表达式:
F
0
=
H
S
F
(
I
L
R
)
(
1
)
F_0 = H_{SF}(I_{LR})\quad\quad\quad(1)
F0=HSF(ILR)(1)- 符号含义:
- F 0 F_0 F0:浅层特征
- H S F ( ⋅ ) H_{SF}(·) HSF(⋅):卷积操作。
- 深层特征提取模块:
- 使用非常深的带有G个残差组(GP)的residual in residual(RIR)结构,来提取深层特征。
- 表达式:
F
D
F
=
H
R
I
R
(
F
0
)
(
2
)
F_{DF} = H_{RIR}(F_0)\quad\quad\quad(2)
FDF=HRIR(F0)(2)- 符号含义:
- F D F F_{DF} FDF:深层特征
- H R I R ( ⋅ ) H_{RIR}(·) HRIR(⋅):表示RIR结构
- 上采样模块:
- (这种后上采样的策略比先上采样方法,更有效地降低计算复杂度并实现更高的性能)
- 常见的上采样模块有:
- 反卷积/转置卷积层(deconvolution/transposed convolution)、
- 最近邻域上采样+卷积(nearest-neighbor upsampling + convolution)、
- 亚像素卷积层(ESPCN)
- 表达式:
F
U
P
=
H
U
P
(
F
D
F
)
(
3
)
F_{UP} = H_{UP}(F_{DF})\quad\quad\quad(3)
FUP=HUP(FDF)(3)- 符号含义:
- F U P F_{UP} FUP:上采样特征
- H U P ( ⋅ ) H_{UP}(·) HUP(⋅):表示上采样模型
- 重建模块:
- 通过一个卷积层重建上采样的特征
- 表达式: I S R = H R E C ( F U P ) = H R C A N ( I L R ) ( 4 ) I_{SR} = H_{REC}(F_{UP})=H_{RCAN}(I_{LR})\quad\quad\quad(4) ISR=HREC(FUP)=HRCAN(ILR)(4)- 符号含义:
- H R E C ( ⋅ ) H_{REC}(·) HREC(⋅):重建操作
- H R C A N ( ⋅ ) H_{RCAN}(·) HRCAN(⋅):完整的RCAN功能
- RCAN的损失函数:
- 常见的损失函数:
- L 2 L_2 L2损失(均方损失函数,例如MSE)
- L 1 L_1 L1损失(距离损失函数)
- 感知和对抗损失函数(如SRGAN)
- 本文采用的是使用SGD优化的
L
1
L_1
L1损失函数,表达式如下:
L
(
θ
)
=
1
N
∑
i
=
1
N
∣
∣
H
R
C
A
N
(
I
L
R
i
−
I
H
R
i
)
∣
∣
1
(
5
)
L(\theta) = \frac{1}{N}\sum_{i=1}^{N}||H_{RCAN}(I^{i}_{LR} - I^{i}_{HR})||_1\quad\quad\quad(5)
L(θ)=N1i=1∑N∣∣HRCAN(ILRi−IHRi)∣∣1(5)- 符号含义:
- θ \theta θ:RCAN网络的参数集
- N:batchsize的大小,一次输入网络的LR-HR对的个数。
- 常见的损失函数:
3.2 Residual in Residual(RIR)
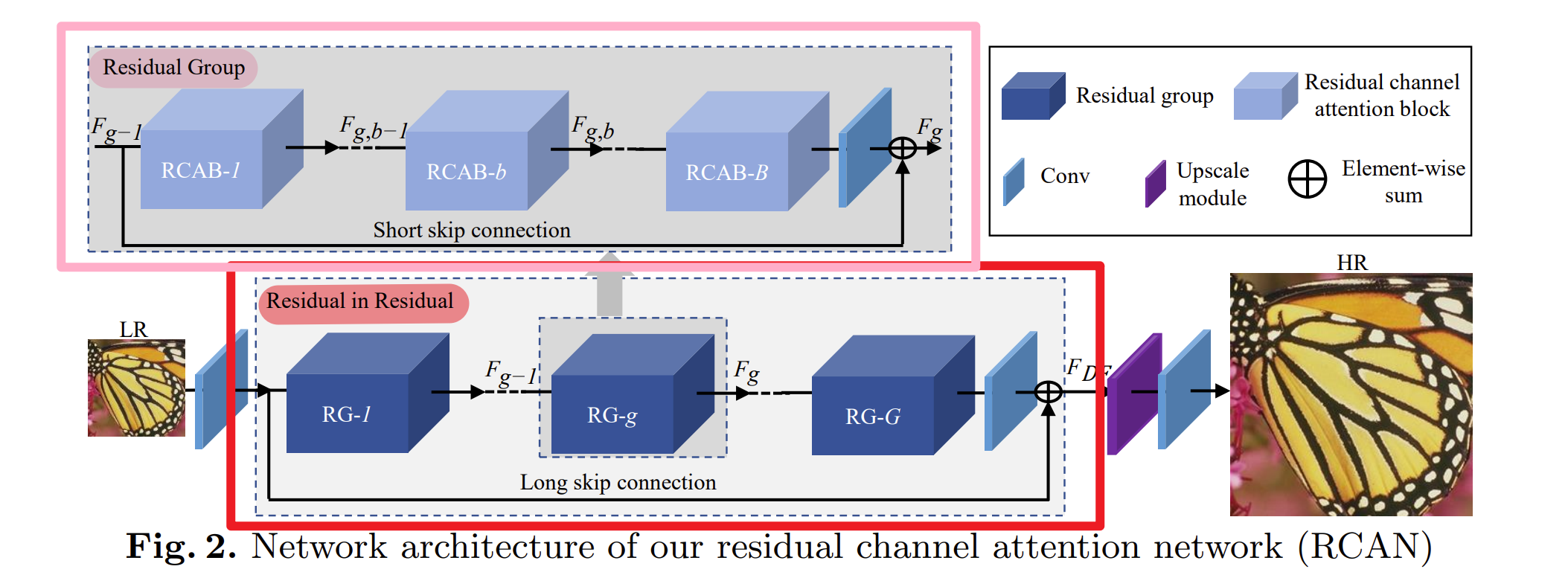
-
从图中可以看到:
- RIR中包含了G个残差组(RG)和长跳跃连接(LSC),
- 由于在图像SR中,非常深的网络会使得训练十分困难,并且也很难获得更高的性能,所以提出了RG作为更深网络的基本模块。
- 每个RG还包含了带有短跳跃连接(SSC)的B个残差通道注意力块(RCAB)。
- 通过LSC和SSC,更丰富的低频信息在训练过程中更容易被绕过。
- RIR中包含了G个残差组(RG)和长跳跃连接(LSC),
-
这种RIR允许训练非常深的 CNN(超过 400 层)以实现高性能的图像 SR。
- 第 g 组中 RG 的公式为:
F
g
=
H
g
(
F
g
−
1
)
=
H
g
(
H
g
−
1
(
⋅
⋅
⋅
H
1
(
F
0
)
⋅
⋅
⋅
)
(
6
)
F_g = H_g(F_{g-1})= H_g(H_{g-1}(···H_1(F_0)···)\quad\quad\quad(6)
Fg=Hg(Fg−1)=Hg(Hg−1(⋅⋅⋅H1(F0)⋅⋅⋅)(6)- 符号含义:
- H g H_g Hg:第g个RG的函数
- F g − 1 、 F g F_{g-1}、F_g Fg−1、Fg:第g个RG的输入、输出
- 但是实验发现,简单的堆叠RG无法实现更好的性能。
- 第 g 组中 RG 的公式为:
F
g
=
H
g
(
F
g
−
1
)
=
H
g
(
H
g
−
1
(
⋅
⋅
⋅
H
1
(
F
0
)
⋅
⋅
⋅
)
(
6
)
F_g = H_g(F_{g-1})= H_g(H_{g-1}(···H_1(F_0)···)\quad\quad\quad(6)
Fg=Hg(Fg−1)=Hg(Hg−1(⋅⋅⋅H1(F0)⋅⋅⋅)(6)- 符号含义:
-
引入了长跳跃连接(LSC)的RIR:
- 优势:
- 可以稳定极深网络的训练。
- 还可以通过残差学习来实现更好的性能。
- 不仅可以简化RG之间的信息流动。
- 还能使RIR能够粗略的学习残差学习。
- 公式为:
F
D
F
=
F
0
+
W
L
S
C
F
G
=
F
0
+
W
L
S
C
H
g
(
H
g
−
1
(
⋅
⋅
⋅
H
1
(
F
0
)
⋅
⋅
⋅
)
)
(
7
)
F_{DF} = F_0 +W_{LSC}F_G = F_0 + W_{LSC}H_g(H_{g-1}(···H_1(F_0)···))\quad\quad\quad(7)
FDF=F0+WLSCFG=F0+WLSCHg(Hg−1(⋅⋅⋅H1(F0)⋅⋅⋅))(7)- 符号含义:
- W L S C W_{LSC} WLSC:RIR尾部卷积层的权重集
- 省略了偏置项。
- 优势:
-
在每个RG中堆叠了B个残差通道注意力块:
- 第g个RG中的第b个残差通道注意块(RCAB)的公式为 F g , b = H g , b ( F g , b − 1 ) = H g , b ( H g , b − 1 ( ⋅ ⋅ ⋅ ( H g , 1 ( F g − 1 ) ⋅ ⋅ ⋅ ) ) ( 8 ) F_{g,b} = H_{g,b}(F_{g,b-1}) = H_{g,b}(H_{g,b-1}(···(H_{g,1}(F_{g-1})···))\quad\quad\quad(8) Fg,b=Hg,b(Fg,b−1)=Hg,b(Hg,b−1(⋅⋅⋅(Hg,1(Fg−1)⋅⋅⋅))(8)
- 符号含义:
- F g , b − 1 、 F g , b F_{g,b-1}、F_{g,b} Fg,b−1、Fg,b:第g个RG中第b个RCAB的输入、输出
- H g , b H_{g,b} Hg,b:第g个RG中第b个RCAB的函数
-
引入了短跳跃连接(SSC)的RG:
- 优势:
- 进一步允许网络的主要部分学习残差信息。
- 公式为:
F
g
=
F
g
−
1
+
W
g
F
g
,
B
=
F
g
−
1
+
W
g
H
g
,
B
(
H
g
,
B
−
1
(
⋅
⋅
⋅
H
g
,
1
(
F
g
−
1
)
⋅
⋅
⋅
)
)
(
9
)
F_g = F_{g-1}+W_gF_{g,B} = F_{g-1}+W_gH_{g,B}(H_{g,B-1}(···H_{g,1}(F_{g-1})···))\quad\quad\quad(9)
Fg=Fg−1+WgFg,B=Fg−1+WgHg,B(Hg,B−1(⋅⋅⋅Hg,1(Fg−1)⋅⋅⋅))(9)- 符号含义:
- W g W_g Wg:第g个RG尾部卷积层的权重
- 优势:
3.3 Channel Attention(CA)
- 目的:
- 之前基于 CNN 的 SR 方法对 LR 通道特征一视同仁,这对于实际情况并不灵活。
- 为了使网络关注更多信息量的特征,利用特征通道之间的相互依赖性,产生通道注意(CA)机制。
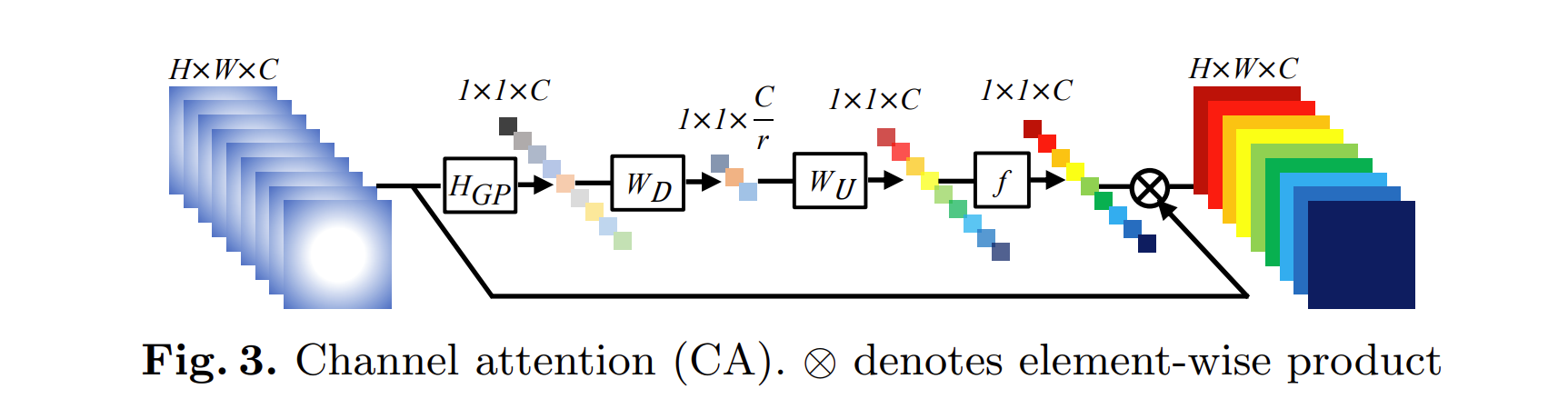
- 如何为每个通道特征产生不同的注意力是关键一步。主要有两个顾虑:
- 首先,LR空间中的信息具有丰富的低频成分和有价值的高频成分。
- 低频部分似乎更加平坦。
- 高频成分通常是区域,充满边缘、纹理和其他细节。
- 另一方面,Conv 层中的每个滤波器都使用局部感受野进行操作。因此,卷积后的输出无法利用局部区域之外的上下文信息。
- 首先,LR空间中的信息具有丰富的低频成分和有价值的高频成分。
- 解决方法:
- 使用全局平均池化将通道方式的全局空间信息放入通道描述中:
- X = [ x 1 ; ⋅ ⋅ ⋅ ; x c ; ⋅ ⋅ ⋅ ; x C ] X = [x1; · · · ; xc; · · · ; xC ] X=[x1;⋅⋅⋅;xc;⋅⋅⋅;xC]是一个输入,它具有 C 个大小为 H × W 的特征图。通道统计量 z ∈ R C z\in \mathbb R^C z∈RC可以通过通过空间维度 H ×W 缩小 X 来获得。- z 的第 c 个元素的公式为:
z
c
=
H
G
P
(
x
c
)
=
1
H
×
W
∑
i
=
1
H
∑
j
=
1
W
x
c
(
i
,
j
)
(
10
)
z_c = H_{GP}(x_c)=\frac{1}{H×W}\sum^{H}_{i=1}\sum^{W}_{j=1}x_c(i,j)\quad\quad\quad(10)
zc=HGP(xc)=H×W1i=1∑Hj=1∑Wxc(i,j)(10)- 符号描述:
- z c z_c zc:通道统计量z 的第 c 个元素的通道描述。
- H G P ( ⋅ ) H_{GP}(·) HGP(⋅):全局池化函数
- x c ( i , j ) x_c(i,j) xc(i,j):第c个特征 x c x_c xc的位置(i, j)处的值。
- z 的第 c 个元素的公式为:
z
c
=
H
G
P
(
x
c
)
=
1
H
×
W
∑
i
=
1
H
∑
j
=
1
W
x
c
(
i
,
j
)
(
10
)
z_c = H_{GP}(x_c)=\frac{1}{H×W}\sum^{H}_{i=1}\sum^{W}_{j=1}x_c(i,j)\quad\quad\quad(10)
zc=HGP(xc)=H×W1i=1∑Hj=1∑Wxc(i,j)(10)- 符号描述:
- 引入门控机制:
- 目的:
- 为了通过全局平均池化从聚合信息中完全捕获通道高依赖性。
- 门控机制的两个标准:
- 它必须能够学习之间的非线性相互作用
- 由于强调多个通道特征而不是one-hot 激活,它必须学习一种非互斥关系。
- 选择sigmoid函数作为简单的门控机制
- 公式为:
s
=
f
(
W
U
δ
(
W
D
z
)
)
(
11
)
s = f(W_U\delta(W_Dz))\quad\quad\quad(11)
s=f(WUδ(WDz))(11)- 符号含义:
- s s s:最终的通道统计数据。
- f ( ⋅ ) f(·) f(⋅):sigmoid门控函数。
- δ ( ⋅ ) \delta(·) δ(⋅):ReLU函数
- W D W_D WD:卷积层的参数集,(r倍的通道缩小)
- W U W_U WU:卷积层的参数集,(r倍的通道放大)
- 目的:
- 重新调整输入:
- 通过通道注意力的逐元素乘积,RCAB 中的剩余分量会自适应地重新缩放。
- 公式如下:
x
c
^
=
s
c
⋅
x
c
(
12
)
\hat{x_c}=s_c·x_c \quad\quad\quad(12)
xc^=sc⋅xc(12)- 符号含义:
- s c s_c sc:第c个通道中的缩放因子
- x c x_c xc:第从c个通道中的特征图
3.4 Residual Channel Attention Block(RCAB)
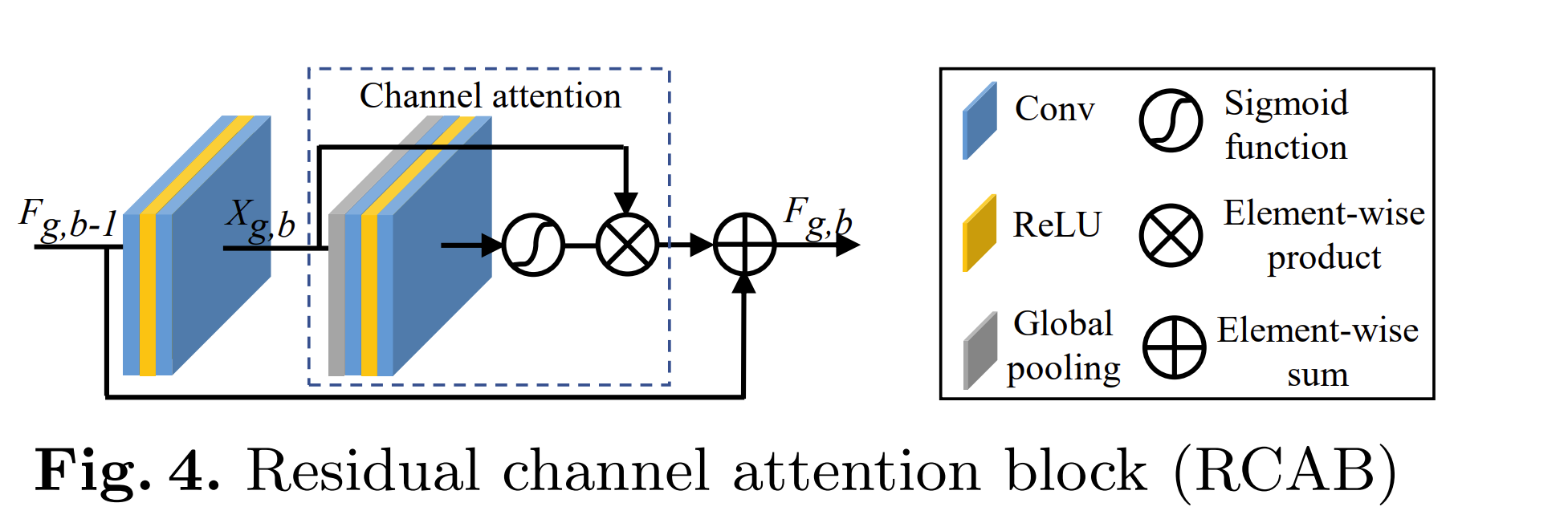
- 将CA整合到RB中,提出了RCAB
- 动机:
- 3.2的GP和LSC允许网络的主要部分专注于LR特征的更多信息组件。
- 3.3的CA提取通道间的通道统计量,进一步增强网络的判别能力。
- 同时收到残差块的启发。
- 第g个RG中的第b个RB的公式如下:
F
g
,
b
=
F
g
,
b
−
1
+
R
g
,
b
(
X
g
,
b
)
⋅
X
g
,
b
(
13
)
F_{g,b} = F_{g,b-1} + R_{g,b}(X_{g,b})·X_{g,b}\quad\quad\quad(13)
Fg,b=Fg,b−1+Rg,b(Xg,b)⋅Xg,b(13)- 符号含义:
- R g , b R_{g,b} Rg,b:CA函数
- F g , b − 1 、 F g , b F_{g,b-1}、F_{g,b} Fg,b−1、Fg,b:RCAB的输入和输出
- X g , b X_{g,b} Xg,b:从输入中的残差分量。
- 其中,残差分量主要由两个对叠的卷积层获得,公式为:
X
g
,
b
=
W
g
,
b
2
δ
(
W
g
,
b
1
F
g
,
b
−
1
)
(
14
)
X_{g,b}=W^2_{g,b}\delta(W^1_{g,b}F_{g,b-1})\quad\quad\quad(14)
Xg,b=Wg,b2δ(Wg,b1Fg,b−1)(14)- 符号含义:
- W g , b 2 、 W g , b 1 W^2_{g,b}、W^1_{g,b} Wg,b2、Wg,b1:RCAB中的两个堆叠的卷积层的权重集。
- 动机:
3.5 实验细节
- RG的个数G=10。
- 每个RG中,RCAB的个数为20。
- 用于通道缩小和放大的卷积层:采用4个1×1的卷积核,缩放比例r=16
- 浅层特征提取和RIR的卷积层:采用64个3×3的卷积核,使用零填充保证大小固定
- 上采样模块:采用ESPCN的亚像素卷积层。
- 最终重建输出层:是彩色图像,采用3个3×3的卷积核。
4 实验
4.1 设置
- 数据集与退化模型
- 训练集:
- DIV2K数据集中的800张训练图片
- 测试集:
- Set5、Set14、B100、Urban100、Manga109
- 退化模型:
- 双三次插值(Bicubic,BI)、模糊下采样(blur-downscale,BD)
- 训练集:
- 评价指标
- 峰值信噪比(PSNR)、在变化的YCbCr空间的Y通道(即亮度)结构相似性(SSIM on Y channel(i.e., luminance) of transformed YCbCr space
- 训练设置
- 数据增强:
- 随机旋转90°、180°、270°,水平翻转
- batchsize:
- batchsize=16、图像块(patches) =48×48
- 优化器:
- Adam: β 1 \beta_1 β1=0.9、 β 2 \beta_2 β2=0.999、 ϵ = 1 0 − 8 \epsilon = 10^{-8} ϵ=10−8
- 学习率:
- 初始学习率: l r = 1 0 − 4 lr=10^{-4} lr=10−4
- 学习率衰退:每 2 × 1 0 5 2×10^5 2×105次迭代,学习率减半
- 深度学习框架:
- PyTorch
- 硬件:
- Titan Xp GPU
- 数据增强:
4.2 RIR和CA
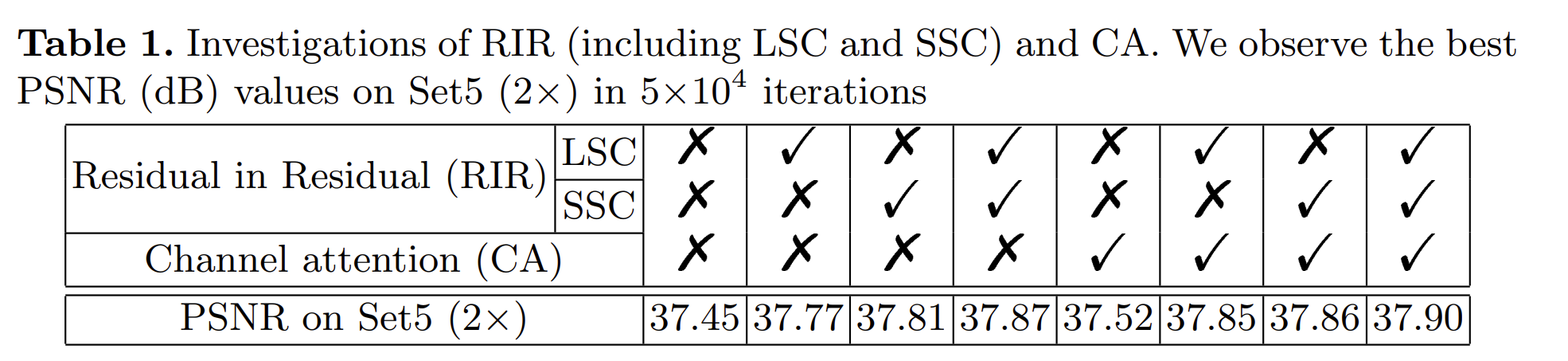
由上表可知:
- Residual in residual(RIR):
- LSC和SSC对于非常深的网络至关重要
- 证明了RIR结构对于非常深的网络的有效性。
- Channel attention(CA):
- 证明了CA的有效性
- 并表明对通道特征的自适应关注确实提高了性能。
4.3双三次(BI)退化模型的结果
- 在BI退化模型中,高频信息的重建非常重要且困难
- 特别是在大尺度因子(例如×8时)的情况下,Bicubic 的结果会丢失结构并产生不同的结构。
- 提出的 RIR 结构使主网络学习残差信息。
- 通道注意力(CA)进一步用于通过自适应地重新缩放通道特征来增强网络的表示能力。
4.4 模糊下采样(BD)退化模型的结果
- BD相对于BI的退化,重建图像的质量更高
- RCAN 通过恢复更多信息成分获得了更好的结果,这表明非常深的通道注意力(CA)引导网络将减轻模糊伪影。
- 也展示了RCAN对于BD退化模型的强大能力。
4.5 Object Recognition 性能
- 这里作者提出了:(这也是第一次看到SR在高级CV中的应用)
- 图像 SR 还可以用作高级视觉任务(例如对象识别)的预处理步骤。
- 评估对象识别性能以进一步证明 RCAN 的有效性。
- 实验细节:
- 模型:使用ResNet-50作为评估模型
- 测试集:使用 ImageNet CLS-LOC 验证数据集中的前 1,000 张图像进行评估
- 原始裁剪的 224×224 图像用于基线,并缩小至 56×56 用于 SR 方法。
- 使用 4 种最先进的方法(例如 DRCN、FSRCNN、PSyCo和 ENet-E)来放大 LR 图像,然后计算它们的精度。
- 实验结果:

4.6 模型尺寸分析
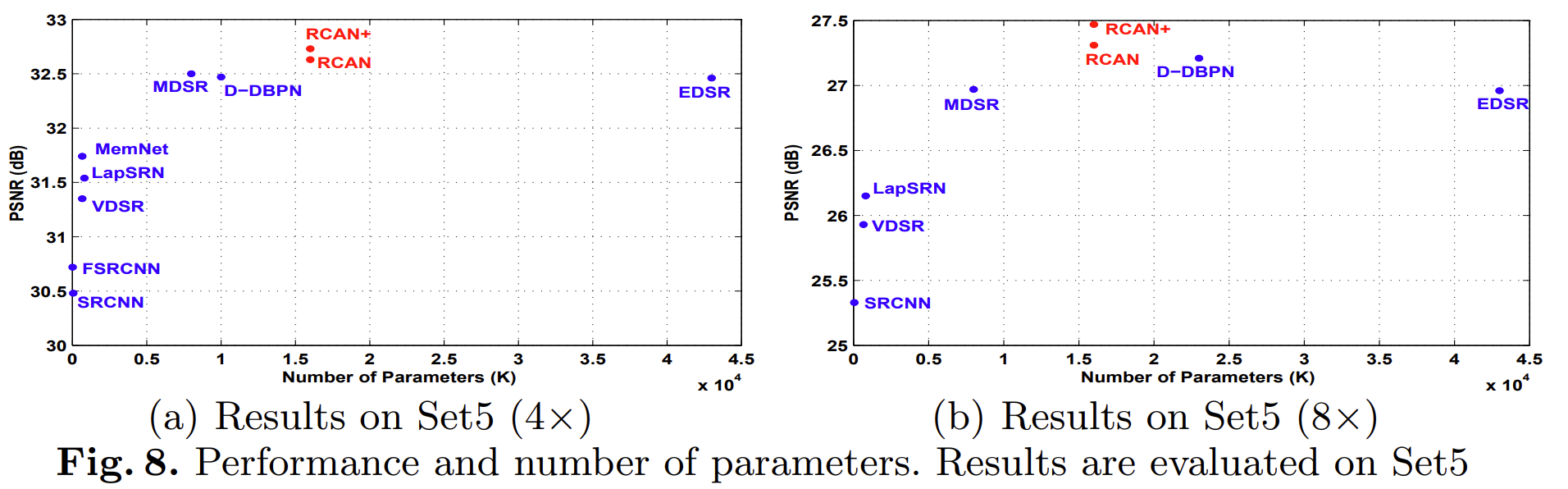
- 从图中可以看出:
- 虽然RCAN 是最深的网络,但它的参数数量比 EDSR 和 RDN 少
- 并且RCAN+比RCAN实现了更高的性能
- 作者对未来的假想:
- 更深的网络可能比更广泛的网络更容易获得更好的性能。
5 结论
- 本文提出了非常深的残差通道注意网络(RCAN),用于高精度图像 SR。
- 提出了RIR结构:
- 具体来说,RIR结构允许 RCAN 通过 LSC 和 SSC 达到非常大的深度。
- 同时,RIR允许通过多个跳跃连接绕过丰富的低频信息,使主网络专注于学习高频信息。
- 提出了通道注意力(CA)机制:
- 此外,为了提高网络的能力 ,CA通过考虑通道之间的相互依赖性来自适应地调整通道特征。
- 使用 BI 和 BD 模型对 SR 进行的大量实验证明了本文提出的 RCAN 的有效性。
- RCAN 在物体识别方面也显示出有前途的结果。
- 提出了RIR结构:















 1328
1328











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









