







13.1 图像增广



总结
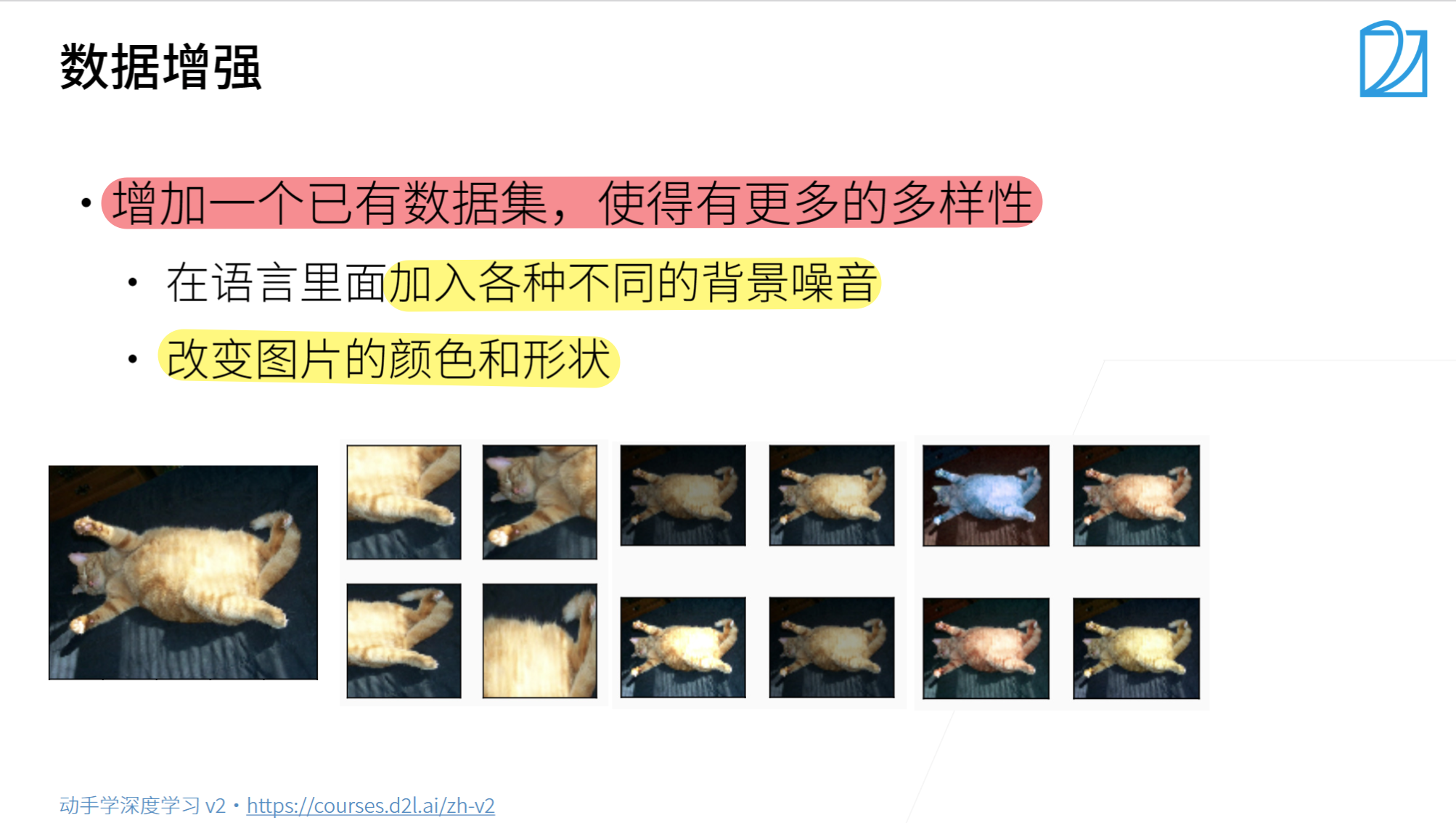
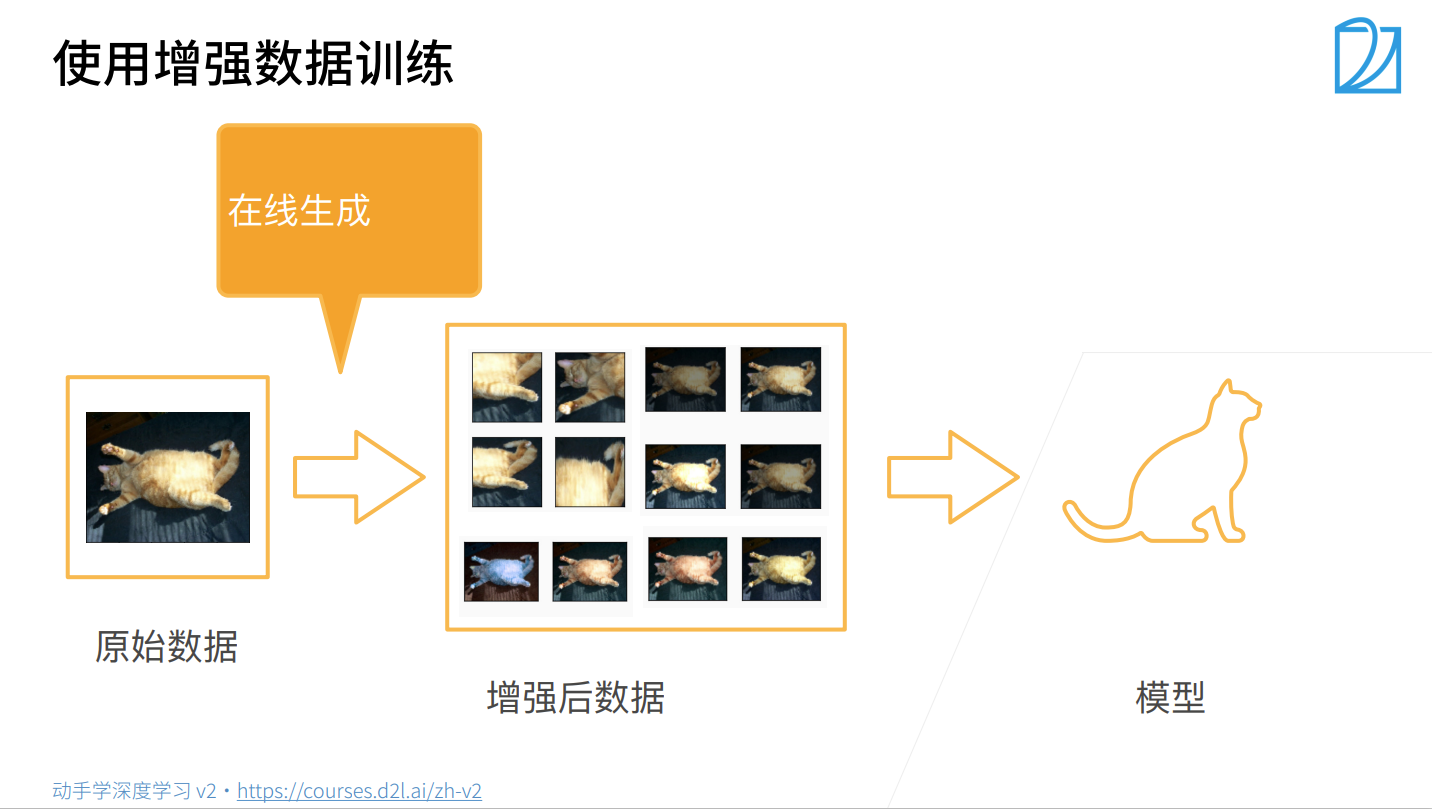
- 数据增广通过变形数据来获取多样性从而使得模型泛化性能更好
- 常见图片增广包裹翻转、切割、变色。
图像增广代码实现
导入相关库
%matplotlib inline
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
查看图像
# 查看图像
d2l.set_figsize()
img = d2l.Image.open('../img/cat1.jpg')
d2l.plt.imshow(img)

定义函数apply: 在输入图像img上多次运行图像增广方法aug并显示所有结果。
def apply(img, aug, num_rows=2, num_cols=4, scale=1.52):
Y = [aug(img) for _ in range(num_rows * num_cols)]
d2l.show_images(Y, num_rows, num_cols, scale=scale)
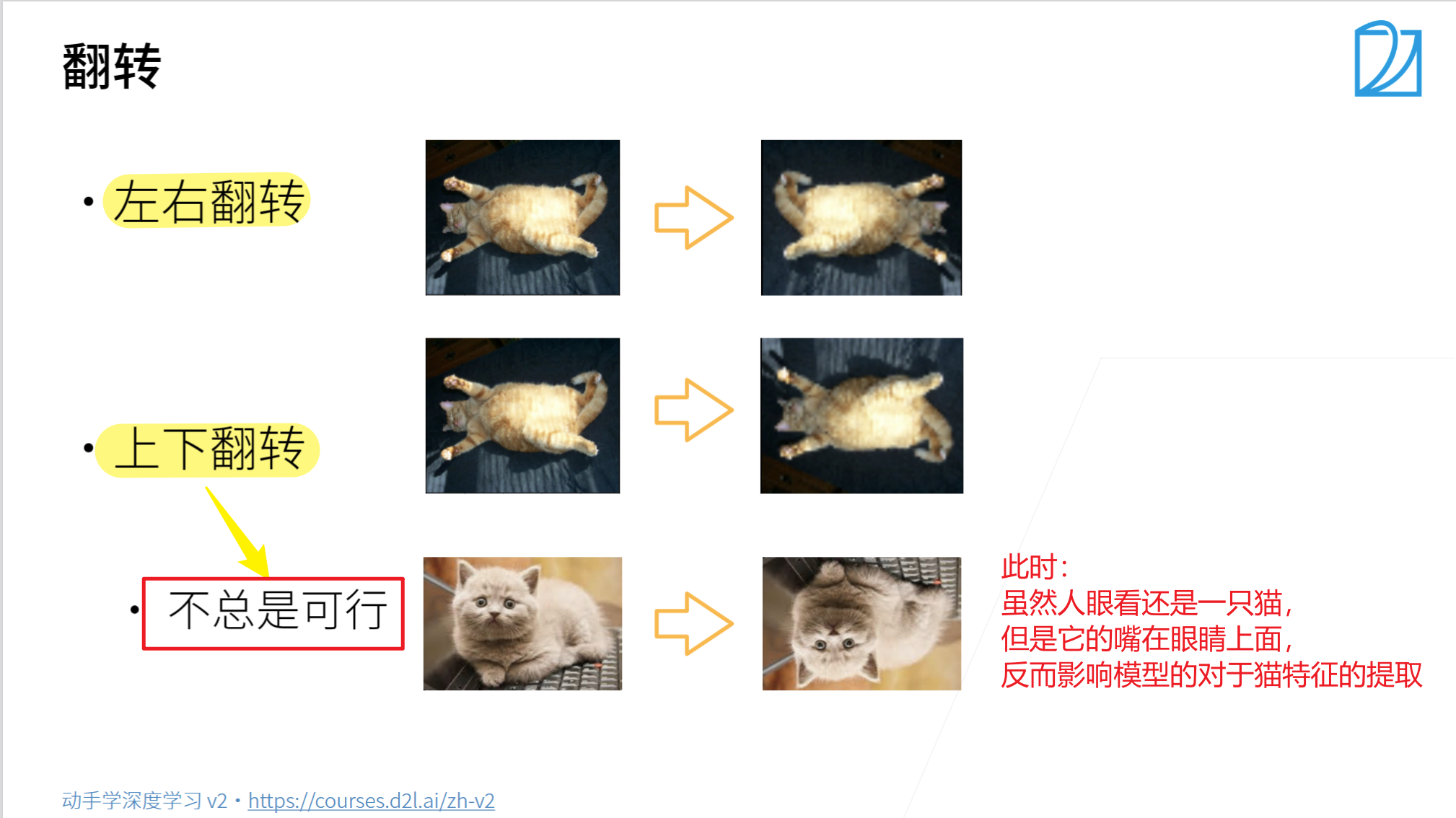
- 水平翻转图像(常用)
# RandomHorizontalFlip():水平翻转,默认50%
apply(img, torchvision.transforms.RandomHorizontalFlip())

- 上下翻转(不常用)
# RandomVerticalFlip():上下翻转,默认50%(针对不同的数据集,选择)
apply(img, torchvision.transforms.RandomVerticalFlip())

- 缩放
apply(img, torchvision.transforms.Resize(256)) # 只有一个值时,按长宽比缩放

test_augs = torchvision.transforms.Compose(
[torchvision.transforms.Resize([256, 256]),
torchvision.transforms.CenterCrop(224)]
)
apply(img, test_augs)

apply(img, torchvision.transforms.Resize([256, 256]))

test_augs2 = torchvision.transforms.Compose(
[torchvision.transforms.Resize(256), # 先按比例放大
torchvision.transforms.CenterCrop(224)] # 然后中心裁剪
)
apply(img, test_augs2)

- 随机剪裁
# 随机裁剪:scale(裁剪面积与原始面积的百分比)、ratio(裁剪区域的宽高比)
shape_aug = torchvision.transforms.RandomResizedCrop(
(200, 200), scale=(0.1, 1), ratio=(0.5, 2)
)
apply(img, shape_aug)

- 随机更改图像的亮度
# 更改图像的:brightness(亮度)、contrast(对比度)、saturation(色调)
apply(img, torchvision.transforms.ColorJitter(
brightness=0.5, contrast=0, saturation=0, hue=0
))

- 随机更改图像的色调
apply(img, torchvision.transforms.ColorJitter(
brightness=0, contrast=0, saturation=0, hue=0.5
))
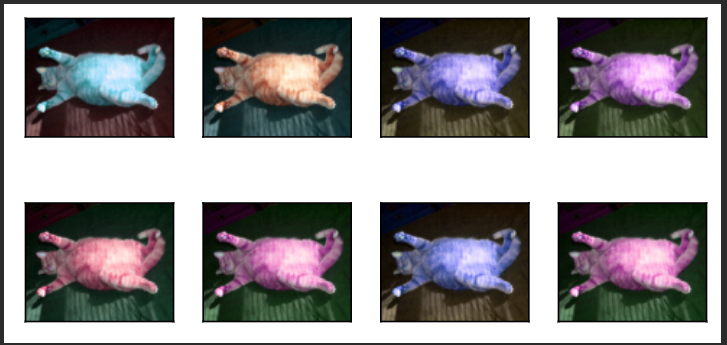
- 随机更改图像的亮度、色调
apply(img, torchvision.transforms.ColorJitter(
brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5
))

- 结合多种图像增广的方法
augs = torchvision.transforms.Compose(
[torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5),
torchvision.transforms.RandomResizedCrop((200, 200), scale=(0.1, 1), ratio=(0.5, 2))]
)
apply(img, augs)

利用图像增广的Resnet18对CIFAR10训练
- 查看CIFAR10数据
all_imgs = torchvision.datasets.CIFAR10(
train=True, root='../data', download=True
)
d2l.show_images(
[all_imgs[i][0] for i in range(32)], 4, 8, scale=0.8
)
- 只使用最简单的随机左右翻转
train_augs = torchvision.transforms.Compose(
[torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor()]
)
test_augs = torchvision.transforms.Compose( # 验证集不需要数据增强
[torchvision.transforms.ToTensor()]
)
- 定义一个辅助函数,以便读取图像和应用图像增广
def load_cifar10(is_train, augs, batch_size):
dataset = torchvision.datasets.CIFAR10(
root='../data', train=is_train,
transform=augs, download=True
)
dataloader = torch.utils.data.DataLoader(
dataset, batch_size=batch_size, shuffle=is_train,num_workers=4
)
return dataloader
- 定义一个函数,使用多gpu对模型进行训练和评估
def train_batch_ch13(net, X, y, loss, trainer, devices):
"""使用多GPU进行小批量训练"""
if isinstance(X, list):
X = [x.to(devices[0]) for x in X]
else:
X = X.to(devices[0])
y = y.to(devices[0])
net.train()
trainer.zero_grad()
pred = net(X)
l = loss(pred, y)
l.sum().backward()
trainer.step()
train_loss_sum = l.sum()
train_acc_sum = d2l.accuracy(pred, y)
return train_loss_sum, train_acc_sum
def train_ch13(net, train_iter, test_iter, loss, trainer, num_epoces, devices=d2l.try_all_gpus()):
"""使用多GPU进行模型训练"""
timer, num_batches = d2l.Timer(), len(train_iter)
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epoces], ylim=[0, 1],
legend=['train loss', 'train acc', 'test acc'])
net = nn.DataParallel(net, device_ids=devices).to(devices[0]) # 使用DataParallel在多个GPU上复制并行化网络
for epoch in range(num_epoces):
# 4个维度:存储训练损失、训练准确度、实例数、特征数
metric = d2l.Accumulator(4)
for i, (features, labels) in enumerate(train_iter):
timer.start()
l, acc = train_batch_ch13(net, features, labels, loss, trainer, devices)
metric.add(l, acc, labels.shape[0], labels.numel())
timer.stop()
if (i+1) % (num_batches // 5) == 0 or i == num_batches -1:
animator.add(epoch + (i+1) / num_batches, (metric[0]/metric[2], metric[1]/metric[3], None))
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch+1, (None, None, test_acc))
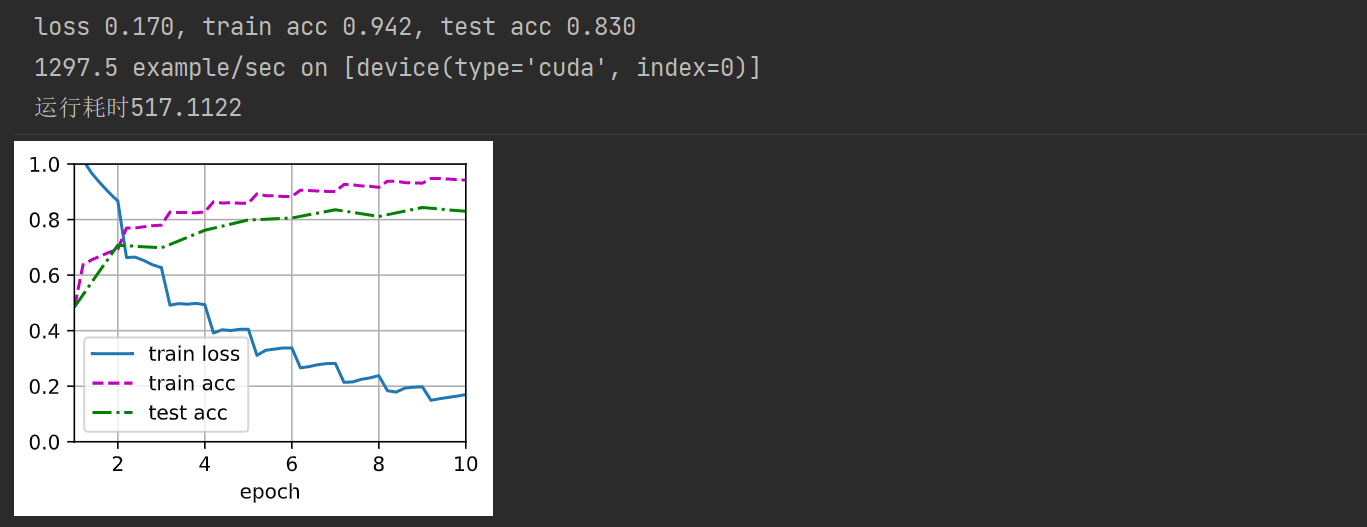
print(f'loss {metric[0]/metric[2]:.3f}, '
f'train acc {metric[1]/metric[3]:.3f}, test acc {test_acc:.3f}')
print(f'{metric[2]*num_epoces / timer.sum():.1f} example/sec on {str(devices)}')
- 定义train_with_data_aug函数,使用图像增广来训练模型
batch_size, devices, net = 256, d2l.try_all_gpus(), d2l.resnet18(10, 3)
def init_weights(m):
if type(m) in [nn.Linear, nn.Conv2d]:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
def train_with_data_aug(train_augs, test_augs, net, lr=0.001):
train_iter = load_cifar10(True, train_augs, batch_size)
test_iter = load_cifar10(False, test_augs, batch_size)
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.Adam(net.parameters(), lr=lr)
train_ch13(net, train_iter, test_iter, loss, trainer, 10, devices)
- 训练模型
import time
# 在开头设置开始时间
start = time.perf_counter() # start = time.clock() python3.8之前可以
train_with_data_aug(train_augs, test_augs, net)
# 在程序运行结束的位置添加结束时间
end = time.perf_counter() # end = time.clock() python3.8之前可以
# 再将其进行打印,即可显示出程序完成的运行耗时
print(f'运行耗时{(end-start):.4f}')














 1046
1046











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









