






一、引言
随着数字化转型的深入,企业对于非结构化数据的处理需求日益增长。阿里云推出的文档智能解析服务旨在帮助企业快速高效地将各类文档转化为结构化信息,从而提升业务效率。本文旨在通过实际应用案例,对阿里云文档智能解析服务中的“文档解析(大模型版)”进行全面评测,并提出改进建议。
二、最佳实践测评
-
应用场景与业务流程接入
- 场景描述:本评测选取了一个典型的知识PDF文件,目的是评估文档解析(大模型版)在处理大量非结构化文本资料时的表现。
- 业务流程:首先,我们将PDF文档(内涵图片和文字)上传至文档智能解析平台;随后,利用其提供的API接口调用文档解析服务,将这些文档转换为结构化的数据格式;最后,将提取出的信息整合进现有的知识库中。
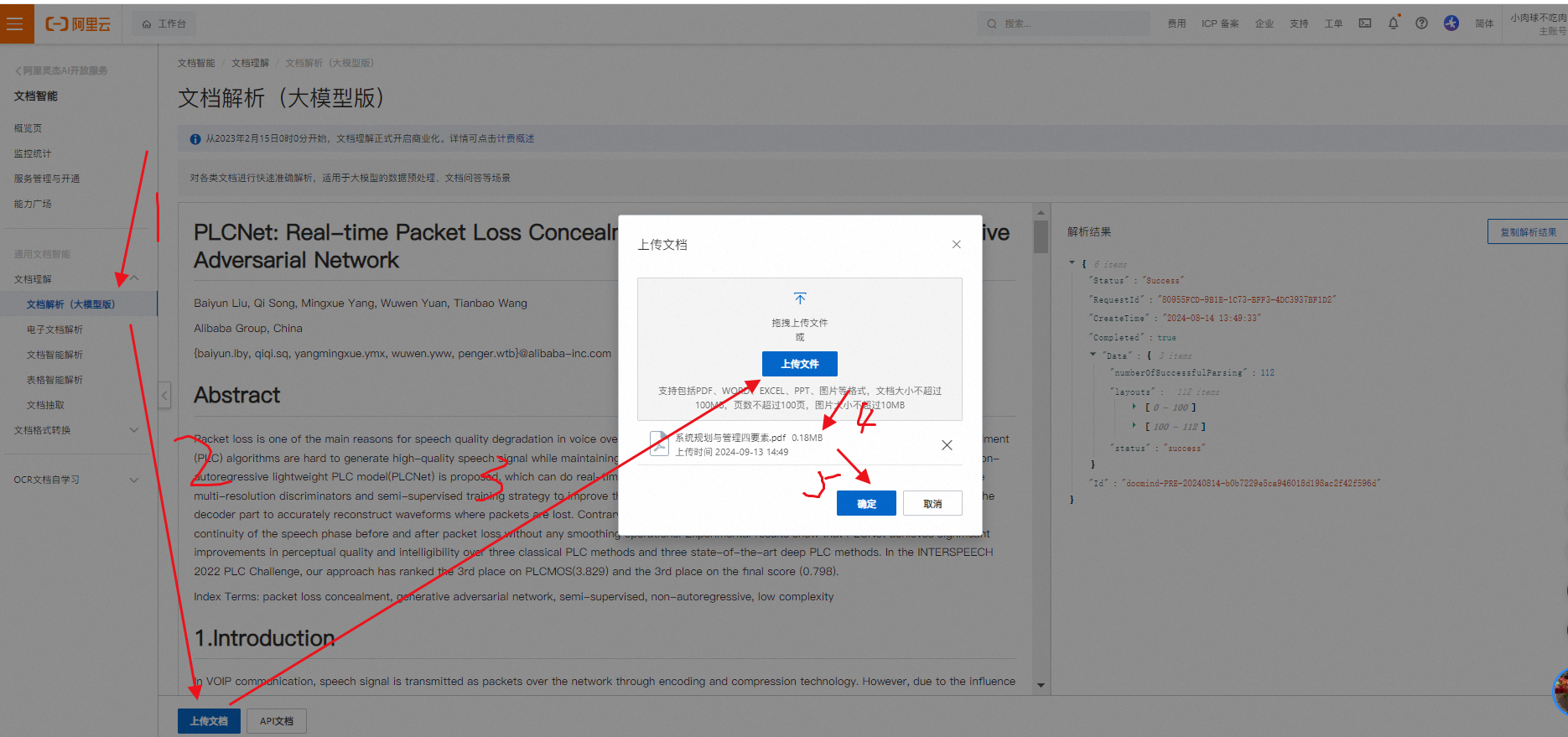
-
性能与可扩展性
- 性能测试:我们对不同大小、不同格式的文档进行了分批处理,测试结果显示文档解析速度较快,且准确率高。尤其是在处理含有图表、公式等复杂格式的文档时,该服务仍能保持较高的识别精度。
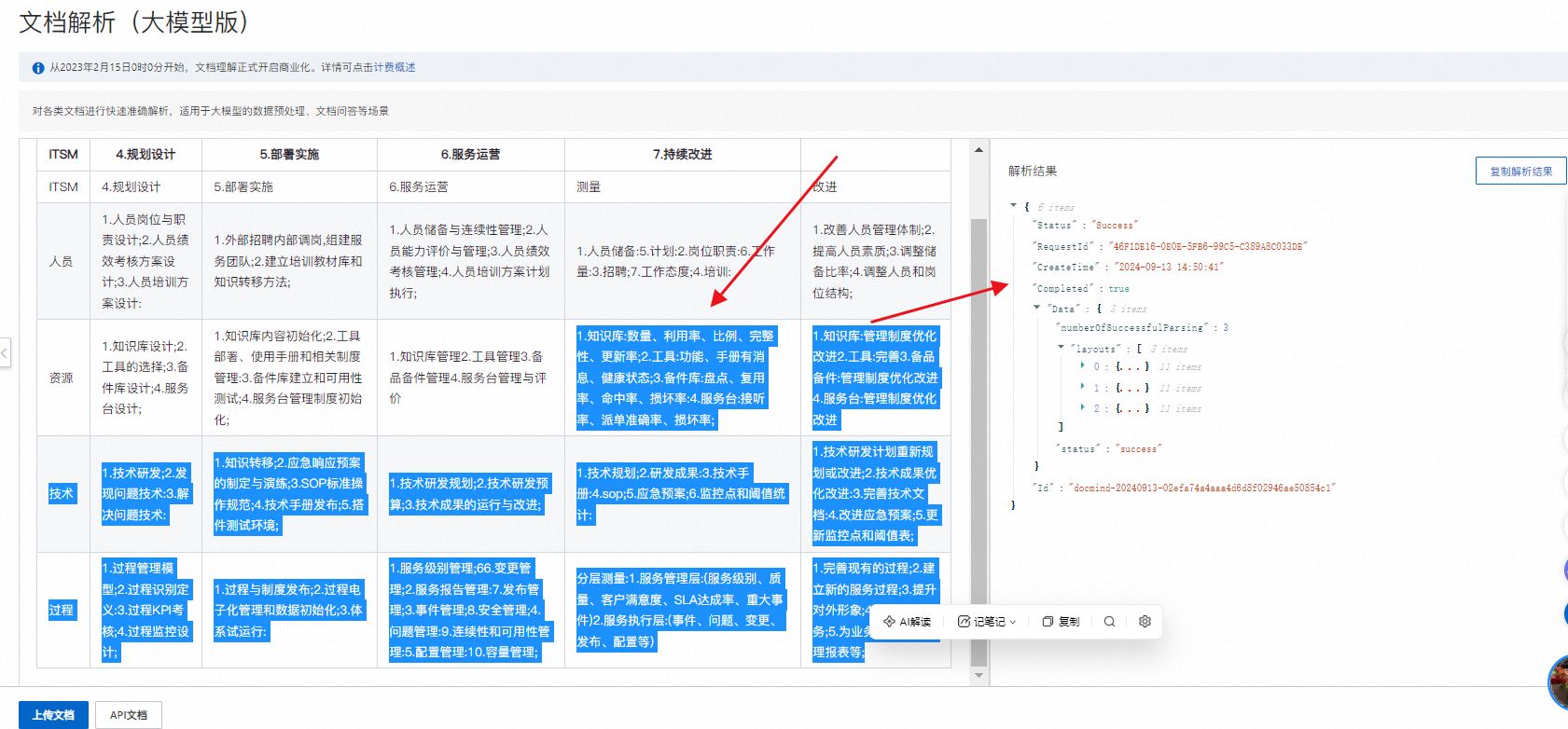
- 可扩展性分析:文档解析(大模型版)支持弹性扩展,可以根据业务量的变化自动调整资源分配,这对于处理高峰期的大量文档尤其有利。
- 性能测试:我们对不同大小、不同格式的文档进行了分批处理,测试结果显示文档解析速度较快,且准确率高。尤其是在处理含有图表、公式等复杂格式的文档时,该服务仍能保持较高的识别精度。
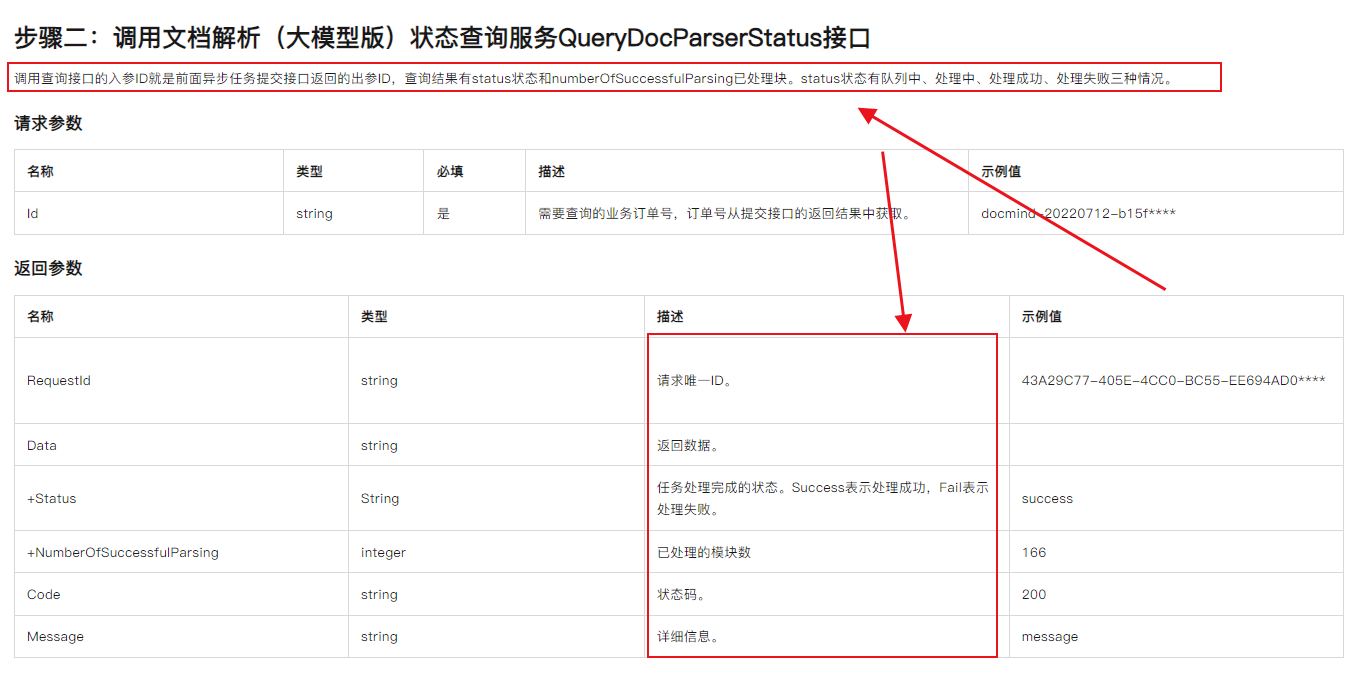
根据开发文档查阅可以看到文档解析(大模型版)接口为异步接口,需要先调用文档解析异步提交服务SubmitDocParserJob接口进行异步任务提交,然后调用文档解析(大模型版)状态查询服务QueryDocParserStatus接口进行处理状态查询,最后根据处理状态,调用GetDocParserResult接口进行结果查询。


上面我是至通过本地上传来进行解析的,下面我们可以看下用API的案例:
示例
以Java SDK为例,本地文档上传调用方式的请求示例代码如下,调用submitDocStructureJobAdvance接口,通过fileUrlObject参数实现本地文档上传。
import com.aliyun.docmind_api20220711.models.*;
import com.aliyun.teaopenapi.models.Config;
import com.aliyun.docmind_api20220711.Client;
import com.aliyun.teautil.models.RuntimeOptions;
import java.io.File;
import java.io.FileInputStream;
public static void submit() throws Exception {
// 使用默认凭证初始化Credentials Client。
com.aliyun.credentials.Client credentialClient = new com.aliyun.credentials.Client();
Config config = new Config()
// 通过credentials获取配置中的AccessKey ID
.setAccessKeyId(credentialClient.getAccessKeyId())
// 通过credentials获取配置中的AccessKey Secret
.setAccessKeySecret(credentialClient.getAccessKeySecret());
// 访问的域名,支持ipv4和ipv6两种方式,ipv6请使用docmind-api-dualstack.cn-hangzhou.aliyuncs.com
config.endpoint = "docmind-api.cn-hangzhou.aliyuncs.com";
Client client = new Client(config);
// 创建RuntimeObject实例并设置运行参数
RuntimeOptions runtime = new RuntimeOptions();
SubmitDocParserJobAdvanceRequest advanceRequest = new SubmitDocParserJobAdvanceRequest();
File file = new File("D:\\example.pdf");
advanceRequest.fileUrlObject = new FileInputStream(file);
advanceRequest.fileName = "example.pdf";
// 发起请求并处理应答或异常。
SubmitDocParserJobResponse response = client.submitDocParserJobAdvance(advanceRequest, runtime);
}
以Java SDK为例,传入文档URL调用方式的请求示例代码如下,调用SubmitDocParserJob接口,通过fileUrl参数实现传入文档URL。请注意,您传入的文档URL必须为公网可访问下载的公网URL地址,无跨域限制,URL不带特殊转义字符。
import com.aliyun.docmind_api20220711.models.*;
import com.aliyun.teaopenapi.models.Config;
import com.aliyun.docmind_api20220711.Client;
public static void submit() throws Exception {
// 使用默认凭证初始化Credentials Client。
com.aliyun.credentials.Client credentialClient = new com.aliyun.credentials.Client();
Config config = new Config()
// 通过credentials获取配置中的AccessKey ID
.setAccessKeyId(credentialClient.getAccessKeyId())
// 通过credentials获取配置中的AccessKey Secret
.setAccessKeySecret(credentialClient.getAccessKeySecret());
// 访问的域名,支持ipv4和ipv6两种方式,ipv6请使用docmind-api-dualstack.cn-hangzhou.aliyuncs.com
config.endpoint = "docmind-api.cn-hangzhou.aliyuncs.com";
Client client = new Client(config);
SubmitDocParserJobRequest request = new SubmitDocParserJobRequest();
request.fileName = "example.pdf";
request.fileUrl = "https://example.com/example.pdf";
SubmitDocParserJobResponse response = client.submitDocParserJob(request);
}
正常返回示例
JSON格式
{
"RequestId": "43A29C77-405E-4DC0-BC55-EE694AD0****",
"Data": {
"Id": "docmind-20240712-b15f****"
}
}
-
与其他工具比较
-
相较于传统的OCR软件或其他第三方文档解析工具,文档智能解析(大模型版)的优势在于其深度学习模型的强大处理能力,能够更准确地识别文档内容,并支持多种语言和文档格式。
-
此外,由于它是阿里云生态的一部分,因此在安全性、稳定性方面也有保障,并且可以无缝衔接阿里云的其他服务,如数据库、存储等。
-
三、服务体验评测
1. 产品引导与文档帮助
- 在初次使用过程中,文档智能解析提供了详尽的操作指南和示例代码,对于新手用户来说非常友好。但是,在某些高级功能的使用上,如如何优化解析效果、处理特殊格式文档、提供灵活的数据导出选项等方面,仍然需要更多的指导和支持。
2. 功能满足度
- 文档解析(大模型版)的服务接入便捷,支持多种编程语言的SDK,降低了开发门槛。其查询性能也令人满意,即使是面对大规模文档集也能迅速响应。不过,在处理一些特定领域的专业术语时,可能存在一定的误识别率,这可能是后续版本需要优化的地方。
3. 改进建议
- 增加对特定领域文档的支持,比如医学文献、法律文书等,以提高垂直领域的适用性。
- 提供更多关于如何训练自定义模型的教程,帮助用户根据自身需求定制解析模型。
- 可以提供灵活的数据导出选项,便于与其他系统集成。
- 强化文档管理和协作功能,如版本控制、权限设置等,以适应企业级应用的需求。
4. 联动组合可能性
-
鉴于文档智能解析作为阿里云生态链的一环,未来可以考虑将其与数据分析工具(如MaxCompute)、机器学习平台(PAI)、搜索服务(OpenSearch)等进行更紧密的集成,形成完整的解决方案。
-
例如,在构建智能问答系统时,可以先使用文档智能解析将知识源文档转换成结构化数据,再利用PAI训练模型,最后通过OpenSearch提供高效检索,形成一个闭环的信息处理链条。
四、结论
总体而言,阿里云文档智能解析(大模型版)在处理非结构化数据方面表现优异,尤其是在性能和可扩展性上具有明显优势。虽然存在一些待完善之处,但其强大的基础能力和广泛的适用场景使其成为企业数字转型过程中的有力助手。随着技术的不断进步和完善,相信它会在更多领域展现出更大的价值。
翻译
搜索
复制


















 1236
1236

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











