









相关资料
代码:https://github.com/valeoai/ZS3
论文:Zero-Shot Semantic Segmentation
摘要
语义分割模型在扩展到大量对象类的能力方面受到限制。在本文中,我们引入了零采样语义分割的新任务:用零训练样本学习从未见过的对象类别的逐像素分类器。为此,我们提出了一种新的架构,ZS3Net,将深度视觉分割模型与从语义词嵌入生成视觉表示的方法相结合。通过这种方式,ZS3Net解决了在测试时面对可见和未见类别的像素分类任务(所谓的“广义”零射击分类)。性能通过一个自我训练步骤进一步提高,该步骤依赖于对未见过的类的像素进行自动伪标记。
引言
分割方法主要是有监督的,但人们对使用图像级注释或方框级注释的弱监督分割模型越来越感兴趣。我们在本文中提议研究一个补充学习问题,即在训练过程中部分类别完全缺失。我们的目标是重新设计现有的识别架构,毫不费力地适应这些从未见过的场景和物体类别。在训练过程中不需要人工注释或真实样本,只需要未见过的标签。这种方法通常被称为零镜头学习(ZSL)。
近年来,人们一直在积极研究用于图像分类的 ZSL。早期的方法将其作为一个嵌入问题来处理。它们学习如何将图像数据和类别描述映射到一个共同的空间,在这个空间中,语义相似性转化为空间接近性。
在本文中,我们介绍了零镜头语义分割(ZS3)这一新任务,并提出了一种名为 ZS3Net 的架构来解决这一问题:受最近zero-shot分类方法的启发,我们将用于图像嵌入的骨干深度网与依赖于类特征的生成模型相结合。这样就能生成来自未知类别的视觉样本,然后用来自可见类别的真实视觉样本和来自未知类别的合成样本来训练我们的最终分类器。
图像嵌入的骨干深度网+依赖于类特征的生成模型==>来自未知类别的视觉样本
+
来自可见类别的真实视觉样本
训练
方法
Zero-shot学习(Zero-shot learning)可解决训练示例中未包含所有类别的识别问题。要做到这一点,需要对类别进行高层次的描述,以帮助将新类别(未见类别)与已有训练示例的类别(已见类别)联系起来。学习通常是通过利用中间级表示来完成的,中间级表示提供了要分类的类别的语义信息。
一个常见的想法是将语言特征之间的语义相似性从某个合适的文本嵌入空间转移到视觉表示空间。实际上,像 "斑马 "和 "驴子 "这样共享大量语义属性的类别,很可能比 "鸟 "和 "电视 "这样差异很大的类别在表征空间中更接近。这种视觉-文本联合视角使得零镜头识别模型的统计训练成为可能。
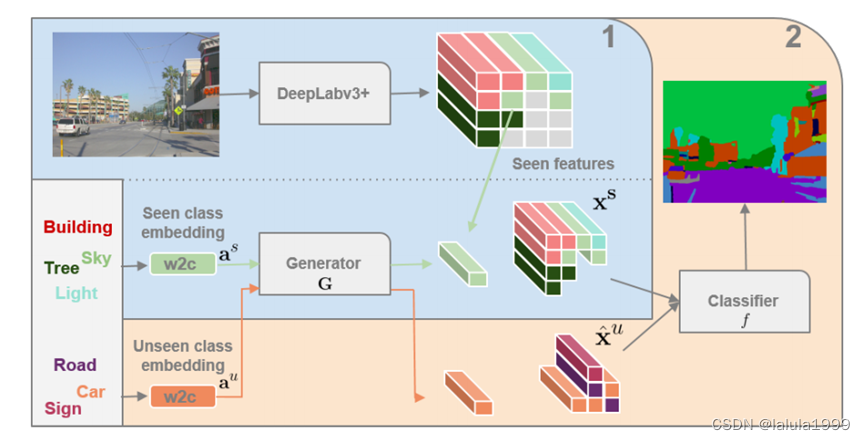
(1)训练生成模型和(2)微调分类层。在(1)中,生成器以已见类标签的word2vec (w2c)嵌入为条件,学习生成与实际DeepLab在已见类上的特征相匹配的合成特征。随后在(2)中,训练分类器从可见类中分类真实特征,从未见类中分类合成特征。在运行时,分类器对来自这两类的真正DeepLab特性进行操作。
在这项工作中,我们要解决的问题是学习一个语义分割网络,该网络能够在一组给定类别之间进行区分,而训练图像只能用于其中的一个子集。为此,我们从现有的语义分割模型入手,对所见数据(图 2 中的 DeepLabv3+)进行有监督损失训练。该模型仅限于训练过的类别,因此无法识别新的未见类别。
为了让语义分割模型同时识别可见和未知类别,我们建议为未知类别生成合成训练数据。这可以通过一个以目标类别的语义表示为条件的生成模型来获得。该生成器会输出分割模型所依赖的像素级多维特征。
一旦生成器经过训练,就可以为未见类别生成许多合成特征,并与已见类别的真实样本相结合。这组新的训练数据将用于重新训练分割网络的分类器(图 2 中的橙色区域 2),使其能够同时处理可见和未知类别。测试时,图像将通过配备了重新训练的分类层的语义分割模型,从而可以预测看到和未看到的类别。
word2vec
我们将在实验中使用在维基百科语料库(约30亿字)中学习的 "word2vec "模型。这种流行的嵌入模型基于skip-gram模型,而skip-gram模型是通过预测目标词典中单词的上下文(附近的单词)来学习的。由于采用了这种训练策略,语料库中经常共享共同语境的词在嵌入向量空间中的位置非常接近。换句话说,这种语义表征有望从几何角度捕捉到相关类别之间的语义关系。
定义和收集像素数据(第 0 步)
我们将编码特征图上的每个空间位置都附加到输入图像的一个像素上,并将其向下采样到相当的尺寸。因此,我们可以为编码特征分配类标签,并在特征空间中构建训练数据。从现在起,"像素 "指的是缩小采样后图像中的像素位置。
我们从 DeepLabv3+ 语义分割模型开始,该模型对所见类别的注释数据进行了有监督损失的预训练。基于这一架构,我们需要从多个可独立用于分类的特征图中选择合适的特征。相反,稍后要微调的分类器必须能够对单个像素特征进行操作。因此,我们选择 DeepLabv3+ 的最后一个1*1卷积分类层和它所提取的特征分别作为我们的分类器 f 和目标特征 x
训练集由三元组组成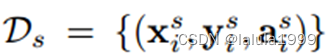
- x:dx维特征映射
- y:相关GT分割映射
- a:类别嵌入映射(它将每个像素与其类别的语义嵌入关联起来)
M × N是编码特征映射的分辨率:x和y
未见过的类别:x和y不可用,只有a
生成模型(第1步)
使用已知类别训练特征生成器。采用“生成矩匹配网络”(GMMN)作为特征生成器。GMNN是一个参数随机生成过程G,使用微分准则来比较目标数据分布和生成的数据分布。
对于每个语义描述a,两个随机总体Xa和生成的样本有较低的最大平均差异。
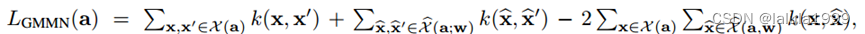
分类模型(第2步)
与DeepLabv3+类似,分类层f由一个1 × 1的卷积层组成。一旦在步骤1中训练了G,就可以对任何类,特别是不可见的类,采样任意多个像素级特征。我们以这种方式建立一个合成的未见训练集 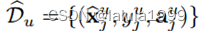 。结合
。结合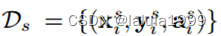 中可见类别的真实特征,这组未见类别的合成特征允许对分类层f进行微调。C中新的像素级分类器变为
中可见类别的真实特征,这组未见类别的合成特征允许对分类层f进行微调。C中新的像素级分类器变为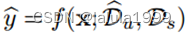 。它可以用于对显示两类对象的图像进行语义分割。
。它可以用于对显示两类对象的图像进行语义分割。
代码复现
本文复现使用的数据集是Pascal-VOC数据集
数据集共有20个类别,可以分为4个大类

以下是对模型训练100轮的整体精度表现:
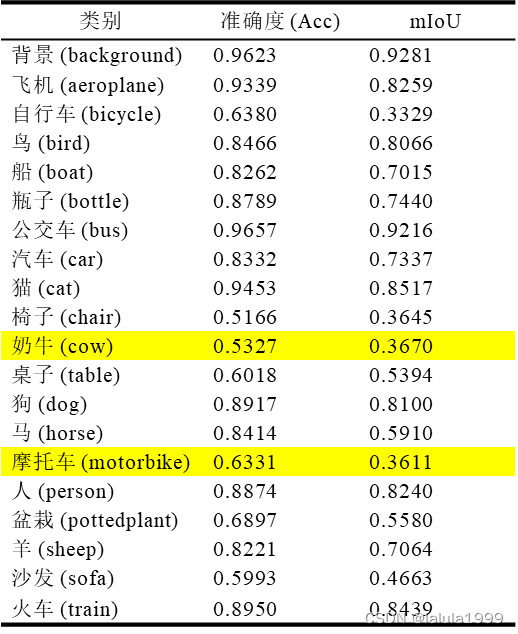
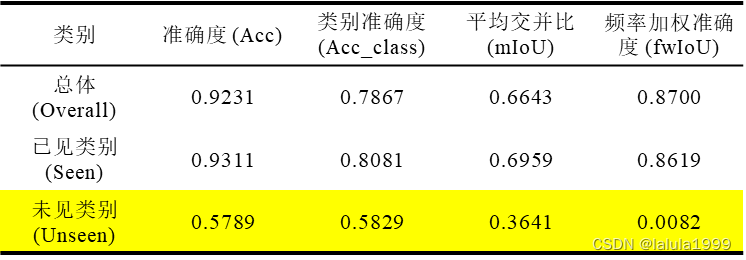
虽然模型在对未知类别预测时的mIoU不高但是准确率还可以,这可能表示模型可能能够大致识别出对象的类别,但难以准确地界定对象的轮廓或边界。


由以上两图可知,虽然模型对类别进行了误分类,但对物体大致位置的识别效果还可以。并且就像人类一样,虽然有误分类,但是误分类的类别属于同一个大类,这说明了相关类别在语义空间的表征情况良好。















 1100
1100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









