







相关资料
论文:Decoupling Zero-Shot Semantic Segmentation
代码:https://github.com/dingjiansw101/ZegFormer
摘要
zero-shot语义分割(ZS3)旨在分割训练中未见的新类别。现有工作将 ZS3 表述为像素级zero-shot分类问题,并借助仅使用文本预先训练的语言模型,将语义知识从已见类别转移到未见类别。像素级的 ZS3 表述虽然简单,但却显示出整合视觉语言模型的能力有限,而这些模型通常是用图像-文本对预先训练的,目前在视觉任务中展现出巨大的潜力。受人类经常执行段级语义标注这一观察结果的启发,我们建议将 ZS3 分解为两个子任务:
1. 无类别分组任务,将像素归入分割区域。
2. 对分段进行zero-shot分类。
前一项任务不涉及类别信息,可直接用于为未见类别的像素分组。后一项任务在分段级别上执行,为 ZS3 提供了一种自然的方式来利用预先用图像-文本对(如 CLIP)训练过的大规模视觉语言模型。基于解耦表述,我们提出了一种简单有效的零镜头语义分割模型,称为 ZegFormer,它在 ZS3 标准基准上的表现远远优于之前的方法。
引言
目前研究遇到的问题:
- 它们通常通过仅通过文本预训练的语言模型将知识从可见类转移到不可见类,这限制了它们在视觉任务中的表现。尽管大规模预训练的视觉语言模型(如CLIP和ALIGN)已经在图像级视觉任务上展示了潜力,但如何有效地将视觉语言模型整合到像素级ZS3问题中仍然是未知的。
- 它们通常在像素级视觉特征和语义特征之间建立关联,以实现知识转移,这是不自然的,因为我们人类经常使用单词或文本来描述对象/分割区域,而不是图像中的像素。
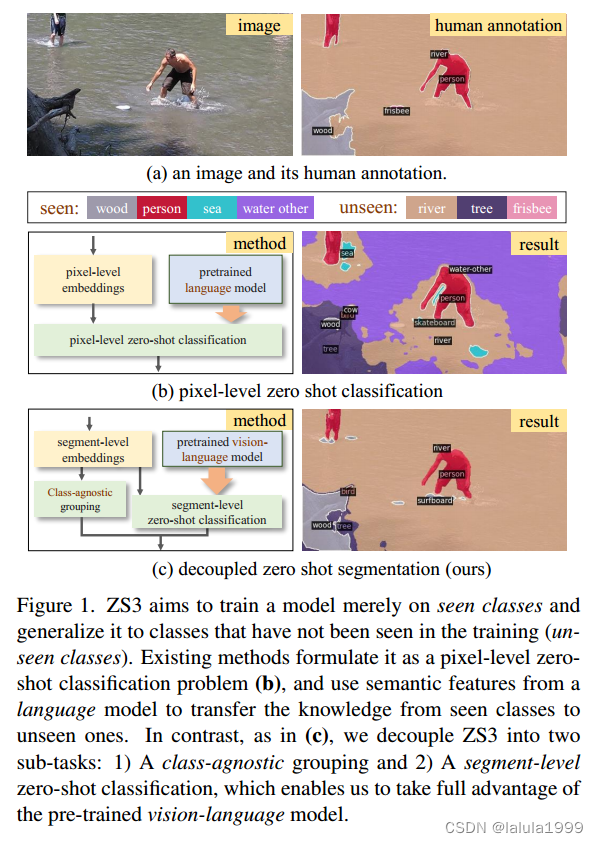
直观的观察是,给定用于语义分割的图像,我们人类可以首先将像素分组为段,然后执行段级语义标记过程。例如,一个孩子可以很容易地将一个物体的像素分组,即使他/她不知道这个物体的名字。
为了实现这种解耦思想,我们提出了一种简单而高效的基于Transformer的zero-shot语义分割模型,称为ZegFormer,它使用Transformer解码器来输出片段级别的嵌入。然后,模型通过一个类别不可知分组(Class-Agnostic Grouping,CAG)的掩码投影和一个片段级别零样本分类(Segment-Level Zero-Shot Classification,s-ZSC)的语义投影来处理输出。
- 掩码投影将每个片段级别的嵌入映射到一个掩码嵌入,通过与高分辨率特征图进行点积,可以获得二进制掩码预测。
- 语义投影建立了片段级别嵌入与预训练文本编码器的语义特征之间的对应关系,用于片段级别的零样本分类(s-ZSC)。
本文的贡献可以总结为以下三个方面:
- 我们提出了一种新的ZS3任务的表述方式,通过将其分解为两个子任务:类别不可知分组和片段级别零样本分类。这种分解方式为将预训练的大规模视觉-语言模型与ZS3集成提供了更自然和灵活的方式。
- 基于这种新的表述方式,我们提出了一种简单而有效的ZegFormer模型用于ZS3,它使用Transformer解码器来生成用于分组和零样本分类的片段级别嵌入。据我们所知,提出的ZegFormer是第一个充分利用预训练的大规模视觉-语言模型(如CLIP)进行ZS3的模型。
- 我们在ZS3的标准基准测试上取得了最先进的结果。消融实验和可视化分析表明,与像素级零样本分类相比,这种分解方式具有明显的优势。
方法
0. 问题定义
如果我们将 S S S表示为注释数据集 D D D的类别集合,即已知类别,而将 E E E表示为测试过程中出现的类别,我们可以将语义分割问题分为三种类型的设置:
- 完全监督的语义分割: E ⊆ S E ⊆ S E⊆S
- 零样本语义分割(ZS3): S ∩ E = Ø S \cap E = Ø S∩E=Ø
- 广义ZS3(GZS3)问题: S ⊂ E S ⊂ E S⊂E
在本文中,我们主要解决GZS3问题,并将 U = E − E ∩ S U = E − E \cap S U=E−E∩S表示为未知类别的集合。
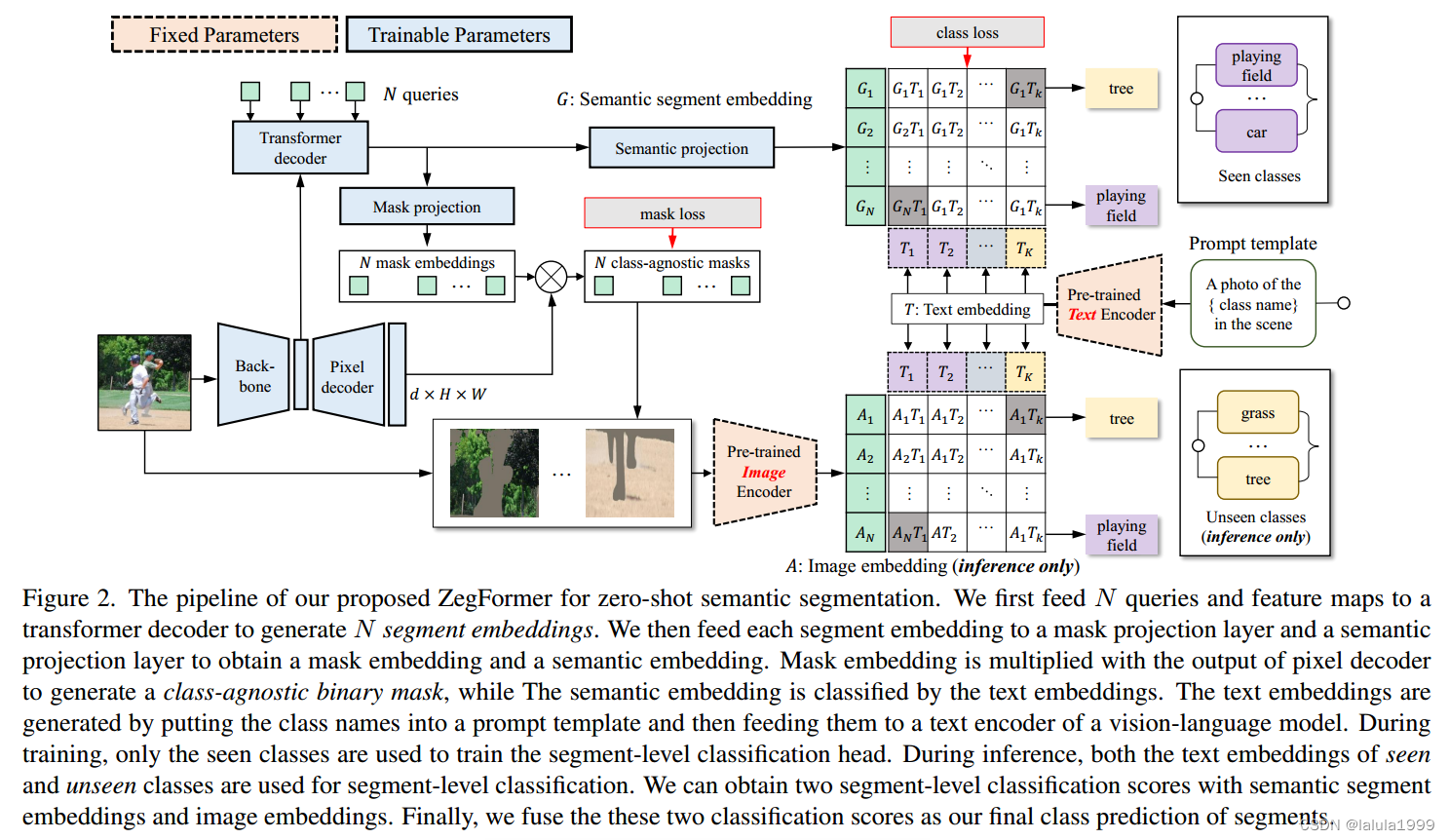
我们提出的ZegFormer用于zero-shot语义分割的流程如下:首先,我们将N个queries和特征图输入到Transformer解码器中,生成N个分割嵌入。然后,我们将每个分割嵌入输入到掩码投影层和语义投影层,得到掩码嵌入和语义嵌入。掩码嵌入与像素解码器的输出相乘,生成一个与类别无关的二值掩码,而语义嵌入则通过文本嵌入进行分类。文本嵌入是通过将类别名称放入提示模板,并将其输入到视觉语言模型的文本编码器中生成的。在训练过程中,只使用已知类别来训练分割级别分类头。在推理过程中,已知和未知类别的文本嵌入都用于分割级别分类。我们可以使用语义分割嵌入和图像嵌入获得两个分割级别分类得分。最后,我们将这两个分类得分融合作为我们对分割的最终类别预测。
1. 分割区域级别的嵌入
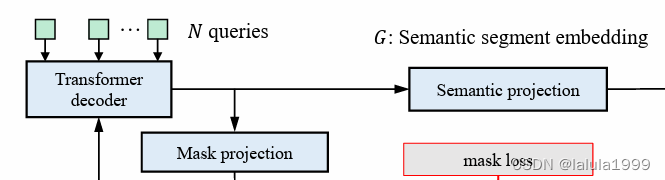
我们选择了Maskformer作为基本的语义分割模型。通过将N个分割查询和一个特征图输入到Transformer解码器中,我们可以获得N个分割级别的嵌入。然后,我们将每个分割嵌入通过语义投影层和掩码投影层,分别得到每个分割的掩码嵌入和语义嵌入。
语义嵌入表示为
G
q
∈
R
d
G_q\in\mathbb{R}^d
Gq∈Rd
分割级别的掩码嵌入表示
B
q
∈
R
d
B_q\in\mathbb{R}^d
Bq∈Rd
2. 类别无关分组
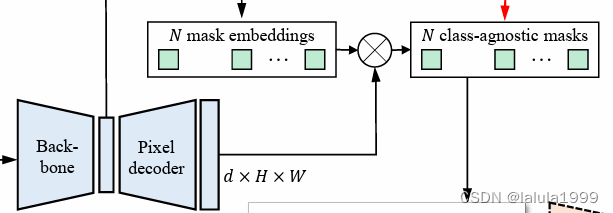
将从像素解码器输出的特征图表示为 F ( I ) ∈ R d × H × W F(I) ∈ ℝ^{d×H×W} F(I)∈Rd×H×W。每个查询的二值掩码预测可以计算为 m q = σ ( B q ⋅ F ( I ) ) ∈ [ 0 , 1 ] H × W m_q = σ(B_q · F(I)) ∈ [0, 1]^{H×W} mq=σ(Bq⋅F(I))∈[0,1]H×W,其中σ是sigmoid函数。需要注意的是,N通常比类别的数量要小。
3. 使用分割级别的语义嵌入进行分割分类
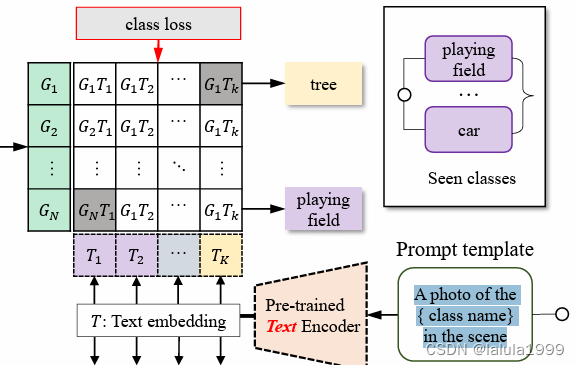
在训练和推理过程中,将类别集合C中的每个“类别名称”放入提示模板(例如“A photo of the {class name} in the scene”),然后输入到文本编码器中。然后,我们可以获得
∣
C
∣
|C|
∣C∣个文本嵌入,表示为
T
=
{
T
c
∈
R
d
∣
c
=
1
,
.
.
.
,
∣
C
∣
}
T = \{T_c ∈ ℝ^d | c = 1, ..., |C|\}
T={Tc∈Rd∣c=1,...,∣C∣},其中在训练过程中
C
=
S
C=S
C=S,而在推断过程中
C
=
S
∪
U
C=S∪U
C=S∪U。在我们的流程中,我们还需要一个“无对象”类别,当分割与任何真值之间的交并比(IoU)较低时使用。对于“无对象”类别,用单个类别名称来表示是不合理的。因此,我们额外添加一个可学习的嵌入
T
0
∈
R
d
T_0 ∈ ℝ^d
T0∈Rd来表示“无对象”。对于一个分割查询,其对已知类别和“无对象”的预测概率分布计算如下:
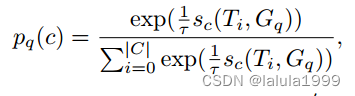
其中,
q
q
q表示查询的索引。
s
c
(
e
,
e
′
)
=
e
⋅
e
′
/
(
∣
e
∣
∗
∣
e
′
∣
)
s_c(e, e') = e·e' / (|e| * |e'|)
sc(e,e′)=e⋅e′/(∣e∣∗∣e′∣)是两个嵌入之间的余弦相似度,其中
e
e
e和
e
′
e'
e′是嵌入向量,
∣
e
∣
|e|
∣e∣和
∣
e
′
∣
|e'|
∣e′∣分别表示它们的范数(欧几里德长度)。
τ
τ
τ是温度参数,用于调整概率分布的平滑程度。
4. 使用图像嵌入进行分割分类
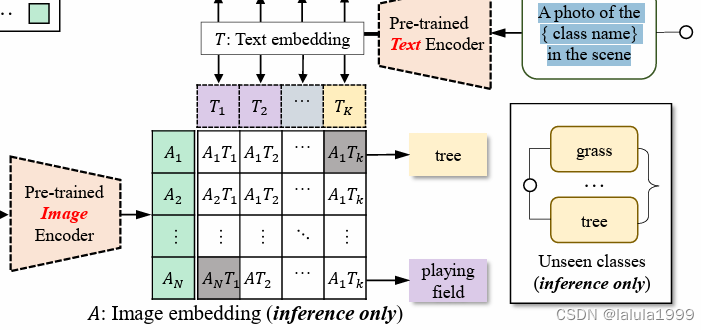
虽然前面的步骤已经可以构成一个独立的ZS3方法,但也可以利用预训练的视觉-语言模型(例如CLIP)的图像编码器来提高分割的分类准确性,这是由于解耦形式的灵活性所带来的。在这个模块中,我们为每个分割创建一个合适的子图像。
这个过程可以表述为,给定一个查询q的二值掩码预测
m
q
∈
[
0
,
1
]
H
×
W
m_q ∈ [0, 1]^{H×W}
mq∈[0,1]H×W和输入图像
I
I
I,创建一个子图像
I
q
=
f
(
m
q
,
I
)
I_q = f(m_q, I)
Iq=f(mq,I),其中
f
f
f是一个预处理函数(例如根据
m
q
m_q
mq生成的掩码图像或裁剪图像)。我们将
I
q
I_q
Iq传递给预训练的图像编码器,并获得图像嵌入
A
q
A_q
Aq。类似于公式1,我们可以计算一个概率分布,表示为
p
q
′
(
c
)
p'_q(c)
pq′(c)。
训练
在ZegFormer的训练过程中,只使用属于 S S S类别的像素标签。为了计算训练损失,对预测的掩码和真实掩码之间进行了二分图匹配。每个分割查询的分类损失为 − l o g ( p q ( c q g t ) ) −log(p_q(c^{gt}_q)) −log(pq(cqgt)),其中如果分割与一个真实掩码匹配,则 c q g t c^{gt}_q cqgt属于 S S S类别,如果分割没有匹配的真实分割,则为“无对象”类别。对于与真实分割 R q g t R^{gt}_q Rqgt匹配的分割,有一个掩码损失 L m a s k ( m q , R q g t ) L_{mask}(m_q, R^{gt}_q) Lmask(mq,Rqgt)。具体而言,我们使用Dice损失和Focal损失的组合来计算掩码损失。
推理
推理过程中,我们将预测的二值掩码和分割的类别得分整合起来,以获得语义分割的最终结果。根据类别的概率得分,我们有三种ZegFormer的变体。
(1) ZegFormer-seg。这个变体使用分割查询的分割分类得分进行推断。由于存在数据不平衡问题,导致预测结果对已知类别有偏差。我们通过降低已知类别的得分来校准预测结果。然后,每个像素的最终类别预测计算如下:
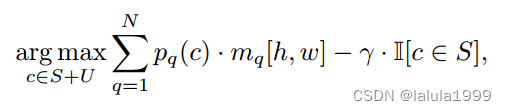
(2) ZegFormer-img. 这个变体的推断过程类似于以上公式。唯一的区别是使用
p
q
′
(
c
)
p'_q(c)
pq′(c)替代了
p
q
(
c
)
p_q(c)
pq(c)。
(3) ZegFormer. 这个变体是我们的完整模型。我们首先对每个查询融合
p
q
′
(
c
)
p'_q(c)
pq′(c)和
p
q
(
c
)
p_q(c)
pq(c),计算如下:
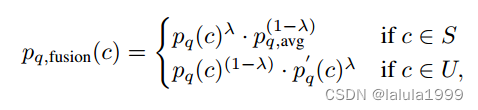
其中,对于属于U类别的c,将
p
q
′
(
c
)
p'_q(c)
pq′(c)和
p
q
(
c
)
p_q(c)
pq(c)的几何平均返回。两个分类得分的贡献由
λ
λ
λ进行平衡。由于如果
c
c
c属于
S
S
S,
p
q
(
c
)
p_q(c)
pq(c)通常比
p
q
′
(
c
)
p'_q(c)
pq′(c)更准确,我们不希望
p
q
′
(
c
)
p'_q(c)
pq′(c)对
S
S
S类别的预测起作用。因此,我们对
p
q
(
c
)
p_q(c)
pq(c)和
p
q
,
a
v
g
=
∑
j
∈
S
p
q
′
(
j
)
/
∣
S
∣
p_{q,avg} = \sum_{j\in S} p'_q(j)/|S|
pq,avg=∑j∈Spq′(j)/∣S∣进行几何平均计算(其中
∣
S
∣
|S|
∣S∣表示已知类别的数量)。这样,已知类别和未知类别的概率可以调整到相同的范围,只有
p
q
(
c
)
p_q(c)
pq(c)对区分已知类别起作用。















 852
852











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









