







相关资料
摘要
大型预训练视觉-语言模型(VLMs),如CLIP,尽管具有显著的泛化能力,但极易受到对抗性样本的攻击。本研究从文本提示这一新颖角度出发,而不是广泛研究的模型权重(在本研究中固定不变),来研究VLMs的对抗性鲁棒性。我们首先展示了对抗性攻击和防御的有效性都对所使用的文本提示非常敏感。受此启发,我们提出了一种通过为VLMs学习鲁棒文本提示来提高对对抗性攻击的抵抗力的方法。我们提出的方法,名为对抗性提示微调(APT),在计算和数据效率方面都非常有效。我们进行了广泛的实验,涵盖了15个数据集和4种数据稀疏性方案(从1-shot到完整训练数据设置),以展示APT相较于手工设计的提示和其他最先进的适应方法的优越性。APT在分布内性能以及在输入分布偏移和跨数据集下的泛化能力方面表现出色。令人惊讶的是,通过简单地向提示中添加一个学习到的词,APT可以显著提高准确性和鲁棒性(ϵ = 4/255),与手工设计的提示相比分别平均提高了+13%和+8.5%。在我们的最有效设置中,改进进一步提高,分别达到了+26.4%的准确性和+16.7%的鲁棒性。
引言
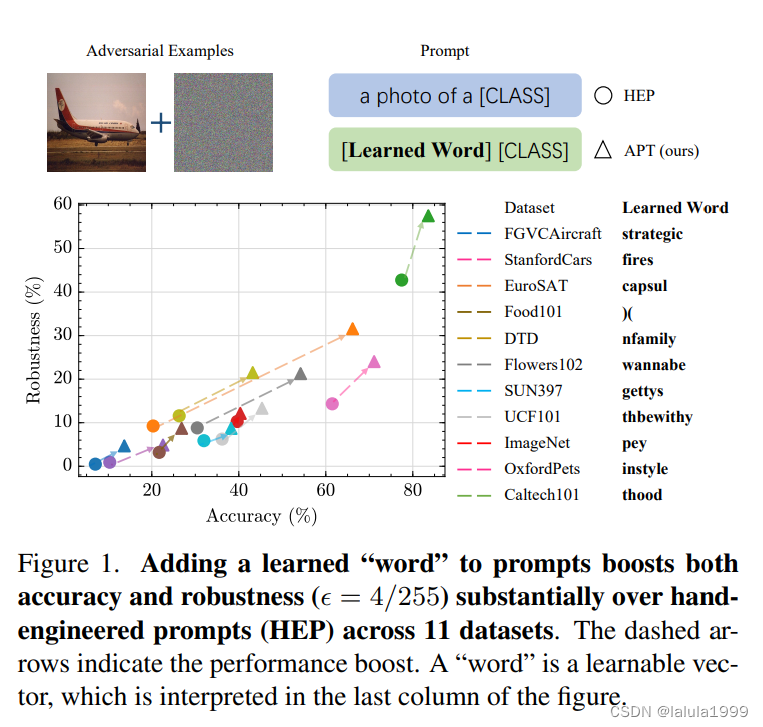
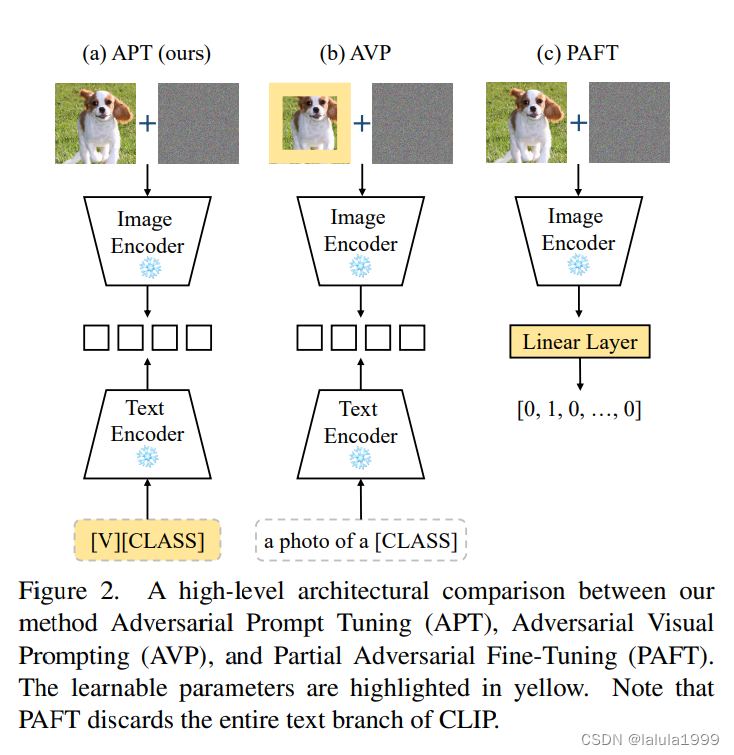
当前对抗性鲁棒性的适应方法集中在模型权重上,即对抗性微调或图像像素上,即对抗性视觉提示。尽管文本输入对VLMs的准确性有显著影响,并且具有如VLMs简单支持(因此不需要修改架构)、参数效率高等优点,但以前很少研究文本提示在对抗性鲁棒性方面的应用。本工作旨在通过研究文本提示在对抗性鲁棒性中的作用,提出一种新的方法来调整文本提示以提高对抗性鲁棒性(见图2)。
文本提示如何影响CLIP的对抗性攻击和防御。我们的主要发现包括:
- 对抗性攻击的强度对生成对抗性示例时使用的提示很敏感;
- 当用于攻击的提示与受害者模型在推理中使用的提示相同时,几乎所有最强的对抗性示例都是生成的;
- CLIP的对抗性鲁棒性对用于推理的提示很敏感。
前两个发现为如何提示强大的对抗性攻击提供了启示。最后一个发现促使我们提出对抗性提示微调(APT)来学习基于对抗性示例的鲁棒文本提示,以提高其对抗性鲁棒性。APT以软提示的形式参数化提示,即将类别嵌入与一系列可学习的向量连接起来(如图3所示)。这些向量构成了数据和类别的上下文描述。它们可以统一为所有类别共享,或者特定于每个类别。然后提出了三种不同的提示策略,以生成训练对抗性示例,可学习的向量被优化以最小化预测损失,如交叉熵。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









