







——————————————————————————
转载请注明出处:https://blog.csdn.net/weixin_44390691/article/details/105177911
——————————————————————————
一.《IMRAM:Iterative Matching with Recurrent Attention Memory for Cross-Modal Image-Text Retrieval》
这是一篇2020年新鲜出炉的CVPR文章,后面简称IMRAM,趁着还热乎赶紧来欣赏一下。
首先贴一下IMRAM在MSCOCO数据集上的表现:

这是在COCO数据集上的结果,总体来看IMRAM和VSRN这两种方法表现最佳,其中在text retrieval上IMRAM更优,而image retrieval上VSRN更好。
我重点说一下我对IMRAM方法的理解。这个方法总体上分为三步:1)分别提取图像和文本的原始特征;2)用RAM模块探索二者之间细粒度上的对齐关系;3)相似性度量以及损失函数迭代优化。
1.得到跨模态特征表示
对于图像:用一个经过预训练的CNN网络来提取特征。给一张图像I,CNN识别出几个包含语义信息的区域r,并提取出每一个区域对应的特征f,最后把特征变成维度一致的向量v:
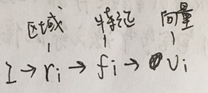
然后
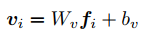
上式中的W和b都是要学习的参数。
对于文本:为了得到图像和文本之间细粒度的对应关系,文章采用双向GRU作为编码器对文本进行编码,得到单词级别的特征。
每一个单词w用一个邻接嵌入向量e表示:
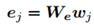
然后用双向GRU对语义信息进行提取:
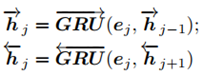
其中h表示hidden state。最后的文本特征用t表示:
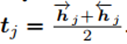
2.用RAM(recurrent attention memory)进行对齐

这个是文中给出的完整框架,其中我圈出来的部分就是一个完整的RAM模块(准确地说是两个RAM,一个用于图像,一个用于文本)。这个示例框架中一共用到了3个RAM模块,每一个RAM都包含一个CAU和一个MDU。
首先是CAU(cross-modal attention unit)。对于query集X和response集Y,CAU的作用是计算每一个x和y之间的相似度,并得到基于x的alignment feature。
首先计算相似度:
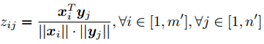
然后将分数z归一化:
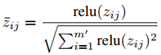
最后得到alignment feature(这里给出的是query是X的情况,如果query是Y就把c的上标改成y):
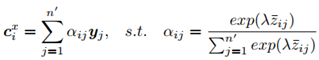
然后是MDU(memory distillation unit)。前面给出的完整框架中一共用了三次RAM,目的是为了对文本和图像进行多次对齐。为了在下一次对齐过程中得到更好的结果,那么就需要在每一次对齐之后再反过来对query features X进行优化。MDU就起到了优化X的作用(带星号表示优化后的特征):
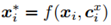
这个f函数是可以任意定义的,这里作者用门机制来定义f函数:
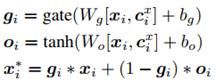
(ps.感觉这里的定义式稍微有点奇怪,g和o的两个式子长得比较像LSTM的门函数和new memory cell,但是最后的x定义式又像是GRU的hidden state的形式。个人觉得这个可能既不是LSTM也不是GRU,而只是作者自己定义的表达式吧……)
3.迭代匹配和损失函数优化
设置迭代次数为k,那么每一步中,一张图像I和一个文本S的匹配分数定义为:
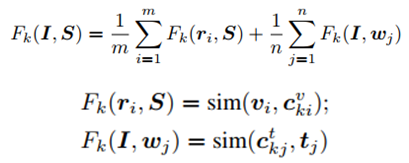
其中sim函数表示相似性度量函数,和前面用过的一样。
最后,I和S的匹配分数为:
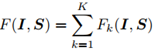
损失函数定义式:
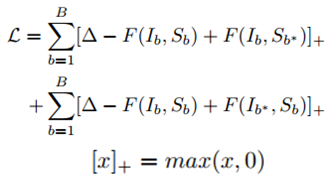
其中带星号的(e.g.Sb*)表示最hard的负样本。
优化的目标是让损失函数最小(即query和正样本的匹配值>query和负样本的匹配值)。这也就意味着:
- 在实验之前需要先对数据集进行预处理,每一个训练样本都要构造成三元组,包含query,positive和negative。
- 这里提到了最hard的负样本,也就是说还需要用curriculum-based mining或者其他手段对负样本进行选择。
二.《Visual semantic reasoning for image-text matching》
这是2019年的一篇ICCV文章,把这两篇放在一起读会发现这两个方法有很多相似之处,而且在IMRAM的实验结果里面也有和VSRN的对比,所以拿出来一起捯饬一下。
这篇文章从方法上来看和上一篇文章非常相似,但是在相同数据集上的表现又各有千秋。下图是VSRN的模型。
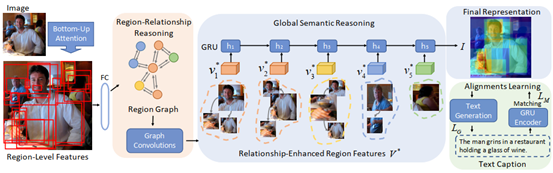
1.提取图像特征
和IMRAM相似,VSRN在这一步也是采取了image→region→feature→vector的步骤来进行图像特征提取,用一个基于ResNet 101的Faster R-CNN来实现。和IMRAM有所不同的是,VSRN在选取ROI时用到了一个机制叫做non-maximum suppression(非极大值抑制):(字丑预警 )

非极大值抑制的作用在于可以过滤掉语义信息相对较少的区域,相当于一次池化操作,最后得到的图片特征也更精确。
2.局部和全局关系推理
区域关系推理:首先要得到不同区域两两之间的相关性,这个相关性用一个分数R来定义:
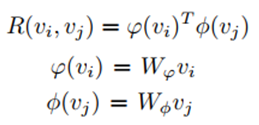
然后对于一张图像就得到了一个拓扑图,再把这个拓扑结构用GCN进行reasoning,最后得到新的V*,即relationship enhanced representation:
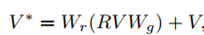
全局关系推理:把V*送到GRU中,保留重要的信息,并过滤不重要的信息,并得到m(相当于new memory cell)作为这张图片的最终表示:
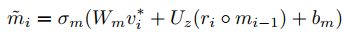
3.损失函数
VSRN的损失函数和IMRAM的基本相同,故不再赘述:
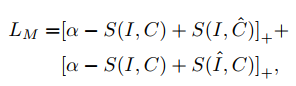
总结:在IMRAM这篇文章中虽然给出了实验结果,但是并没有解释为什么IMRAM和VSRN在两种检索中各有优势的现象。这两篇文章的损失函数、数据集、甚至implementation detail都几乎完全相同,因此我猜测VSRN之所以在image retrieval上的表现更好的原因在于VSRN在提取图像特征时加入了non-maximum suppression机制,增强了图像表示;以及在GCN中还加入了residual connection机制,可能在权重等参数的优化过程中起到了辅助作用。















 1416
1416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









