






IMRAM: Iterative Matching with Recurrent Attention Memory
for Cross-Modal Image-Text Retrieval
摘要
问题:采用细粒度的方式探索图像文本的双向检索,平等地考虑所有的语义,统一的对齐他们,不考虑复杂性
idea:提出IMRAM,通过多个对齐步骤捕获图像和文本之间的对应关系。提出IMRAM,通过多个对齐步骤捕获图像和文本之间的对应关系。
1 介绍
粗粒度对应:如Wang等人[26]采用两个分支的深度网络分别将图像和文本映射到嵌入空间中。
问题:粗略地捕捉了模态之间的对应关系,因此无法描绘视觉与语言之间的精细互动。
细粒度对应:Karpathy等[11]提取了每个图像和文本的片段特征(即图像区域和文本词),并提出了每个片段对之间的密集对齐。
问题:由于图像和文本之间存在较大的异质性差距,现有的基于注意力的模型,例如[13],可能无法很好地抓住多个区域-词片段对之间的最佳成对关系。
本文:
1.提出了具有循环注意记忆的迭代匹配框架,用于跨模态图像-文本检索,称为IMRAM。
(1)具有跨模态注意单元的迭代匹配方案,以对齐不同模态的片段;迭代匹配方案可以逐步更新跨模态注意核心,积累线索来定位匹配语义。
(2)内存蒸馏单元,动态聚合前期匹配步骤到后期匹配步骤的信息。记忆蒸馏单元可以通过增强跨模态信息的交互来提炼潜在的对应关系。
贡献:
1.首先,我们提出了一种用于跨模态图像-文本检索的迭代匹配方法来处理语义的复杂性。
2.我们提出了一种循环注意记忆的迭代匹配方法,该方法结合了跨模态注意单元和记忆蒸馏单元,以细化图像和文本之间的对应关系。
2 相关工作
:(1)粗粒度匹配方法,通过将整幅图像和全文映射到一个共同的嵌入空间中,在全局范围内挖掘对应关系;
(2)细粒度匹配方法,在细粒度层面探索图像片段和文本片段之间的对应关系
3 方法

3.1跨模态特征表示
图像特征表示
我们使用了预训练的深度CNN,例如Faster R-CNN。具体来说,给定图像I, CNN检测图像区域并为每个图像区域ri提取特征向量fi。我们进一步将fi通过线性投影变换为d维向量vi,如下所示:
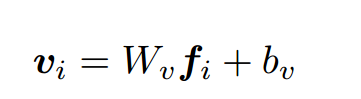 其中Wv和bv都是待学习的参数。
其中Wv和bv都是待学习的参数。
文本特征表示
我们提取了文本的词级特征,这可以通过双向GRU作为编码器来完成。
我们在文本S中使用双向GRU从正向和反向两个方向总结信息:
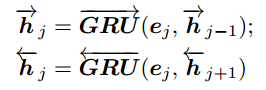
上面代表正向GPU隐藏状态
下面代表反向GPU隐藏状态
3.2 循环注意记忆
循环注意记忆的目的是通过循环地精炼先前片段对齐的知识来对齐嵌入空间中的片段。
它可以看作是一个块,它接受两组特征点,即V和T,并通过一个跨模态注意单元来估计这两组特征点之间的相似性。
查询集X,响应集
记忆蒸馏单元用于精炼注意力结果,以便为下一次对齐提供更多的知识。
跨模态注意单元:为X中的每个特征xi总结Y中的上下文信息。每对(xi, yj)之间使用余弦函数的计算相似度:
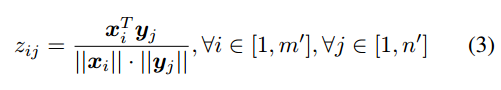
我们进一步将相似性得分z归一化为:
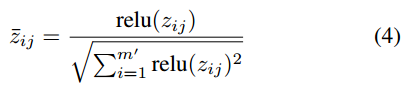
![]()
内存蒸馏装置(MDU)
为了提炼下一次对齐所需的对齐知识,我们采用了一个内存蒸馏单元,通过动态地将查询特征X与相应的基于X的对齐特征Cx聚合来更新查询特征X:
内存块
我们将跨模态注意单元和内存蒸馏单元整合到一个RAM块中,其公式为:
3.3 循环注意力的迭代匹配
具体来说,给定图像I和文本S,我们分别基于I和S,使用两个独立的RAM块推导出两种迭代匹配策略:
我们迭代地执行RAM()总共K步。
在每一步k,我们可以得到I和S之间的匹配分数:
 其中F(ri,S)和F(I, wj)分别定义为基于区域的匹配分数和基于单词的匹配分数。它们的推导如下:
其中F(ri,S)和F(I, wj)分别定义为基于区域的匹配分数和基于单词的匹配分数。它们的推导如下:
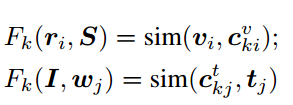
3.4 损失函数
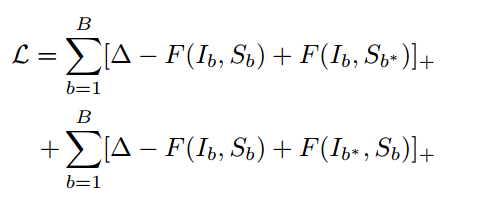















 3982
3982











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









