







《Multilevel Language and Vision Integration for Text-to-Clip Retrieval》(2018 CVPR)
这篇文章引入了一个多层的模型,输入一个描述某个动作的查询语句,就可以从一段没有经过修剪的视频中找出对应的片段。
首先是第一个阶段,在temporal segment proposal阶段注入文本特征。该步骤通过SPN(Segment Proposal Network)网络来实现:

简单来说,SPN网络首先使用3D卷积网络(C3D)对输入视频中的所有帧进行编码,然后用LSTM把query语句S嵌入到特征向量f(S)中,再计算视频特征和f(S)的内积,并用tanh函数激活,来得到注意力权重(attention weight)。
然后是早期融合检索模型。SPN的输出是一组候选的片段,接下来就用早期融合模型来选取最接近query sentence的片段。结构如下。

模型的第一层LSTM处理句子中的单词。第二层的输入是视觉特征嵌入f(R)和第一层生成的每个单词的隐藏状态h。最后就可以通过预测得到一个非线性相似性得分σ(S;R)。
在训练过程中使用的是基于三元组(S; R; R’)的检索损失,其中(S; R)是匹配的语句-片段对,而R’是和S不匹配的负片段。损失函数如下:
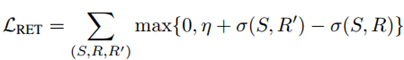
优化该损失函数的最终目的就是使σ(S;R) 越大越好,而σ(S;R’)越小越好。
此外,还引入了captioning loss函数:
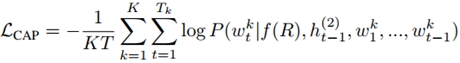
这个函数可以作为该模型的验证步骤,也就是从理论上来说,应该能够从检索到的视频片段中重新生成query sentence。
最后,总体的损失函数由以上两个函数共同构成:
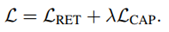
在本文中,λ 取值为0.5。
在实验部分用到了两个数据集:Charades-STA和ActivityNet Caption。这两个数据集都包含文本-视频检索任务所需要的数据注释。下表示在Charades-STA上的检索结果:
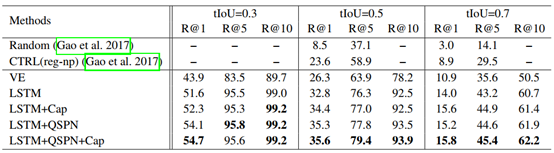
最后一行是文章所提出的完整模型,可以看出几乎所有的情况下该模型都取得了最好的表现。其中,CTRL是2017年提出的一个文本-视频检索的模型。该方法能够在性能上超过CTRL,可能的原因有两点:
- CTRL用的是滑动窗口方法,可伸缩性不强,相比之下本文提出的方法是在更细的粒度上进行检索,因此准确度更高;
- CTRL用的是二进制分类损失,而本文提出的方法用的是基于三元组的损失,此外还引入了captioning loss作为验证,因此精确度更高。
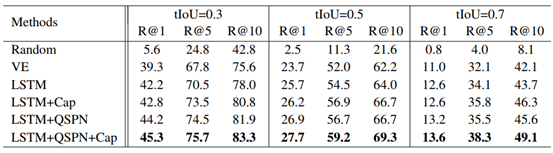
下表是在ActivityNet Caption数据集上的实验结果,和Charades-STA基本一致:















 4403
4403











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









