







性能测量
4.1 引言
容易计算内存的需求大小,只要知道编译后的代码和数据空间的大小就可以了;
数据空间的大小取决于用户所要解决的问题实例的大小。
要确定程序运行时间,需要通过实验来测量。
程序性能不仅依赖操作类型和数量,而且依赖数据和指令的内存模式。
性能测量(performance measurement)关注的是一个程序实际需要的空间和时间。
对运行空间,我们无法明确地考量,这是因为如下两个因素:
-
指令空间和静态分配的数据空间是由编译器在编译时确定的,它们的大小可以用操作系统指令来得到。
-
递归栈空间和动态分配的变量空间可以用程序性能分析方法明确地估算。
对运行时间,首先确定定时机制:
本书使用C++函数clock()来测量时间,它用“滴答”数来计时。在头文件time.h中定义了常数CLOCK_PER_SEC,它记录每秒流逝的“滴答”数,并转换成秒。CLOCK_PER_SEC=1000,滴答一次等于一毫秒。
也有更精确的时间函数,例如QueryPerformanceCounter。
4.2 选择实例的大小
确定实例特征n的值需要以下两个因素:程序执行的时间及执行的次数。

个人理解就是根据实际情况选择合适的实例大小
4.3 设计测试数据
为了使很多程序能够产生最好和最坏复杂度,我们可以徒手设计或借助计算机设计相应的测试数据。可是通常很难设计可以产生平均复杂度的测试数据。
如果不能为预期的复杂度设计一组测试数据,那就从随机生成的数据中选择用时最少(最多,平均)的数据作为测试数据,以得到最好(最坏,平均)复杂度的估算值。
4.4 实验设计
误差在10%以内的测量程序
PerformanceMeasurement.h
#pragma once
#ifndef __PERFORMANCEMEASUREMENT_H_
#define __PERFORMANCEMEASUREMENT_H_
template<class T>
void insertionsort(T a[], int n)
{
//对数组a[0:n-1]实施插入排序
for (int i = 1; i < n; i++)
{
//把a[i]插入a[0:i-1]
T t = a[i];
int j;
for (j = i - 1; j >= 0 && t < a[j]; j--)
a[j + 1] = a[j];
a[j + 1] = t;
}
}
void PerformanceMeasurement();
#endif
PerformanceMeasurement.cpp
#include "_0PerformanceMeasurement.h"
#include "time.h"
#include <iostream>
using namespace std;
void PerformanceMeasurement()
{
int a[1000], step = 10;
double clocksPerMillis = double(CLOCKS_PER_SEC)/ 1000;//每毫秒滴答一次
cout << "The worst-case time,in milliseconds,are" << endl;
cout << "n\tRepetitions\tTotal Ticks\tTime per Sort" << endl;
//次数n = 0,10,20,.,100,200,300,…,1000
for (int n = 10; n <= 1000; n += step)
{
//为实例特征n测量运行时间
long numberofRepetitions = 0;
clock_t startTime = clock();
do
{
numberofRepetitions++;
//用最坏测试数据初始化
for (int i = 0; i < n; i++)
a[i] = n - i;
insertionsort<int>(a,n);
}
while (clock() - startTime < 1000);
//重复运行,直到有足够的时间流逝
double elapsedMillis = (clock() - startTime) / clocksPerMillis;
cout << n << '\t'<< numberofRepetitions <<'\t'<<'\t'<< elapsedMillis <<'\t'<<'\t'<< elapsedMillis/numberofRepetitions << endl;
if(n == 100)
step = 100;
}
}
main.cpp
/*
Project name : allAlgorithmsTest
Last modified Date: 2022年8月13日17点38分
Last Version: V1.0
Descriptions: main()函数,控制运行所有的测试函数
*/
#include <iostream>
#include "_0PerformanceMeasurement.h"
int main()
{
PerformanceMeasurement();
return 0;
}
4.5 高速缓存
4.5.1 简单计算机模型
简单的计算机模型:它的存储由一个一级缓存L1(level 1)、一个二级缓存L2和主存构成。算术和逻辑操作由算术和逻辑单元(ALU)对存储在寄存器(R)中的数据进行处理来完成。图4-5是这个计算机模型的一部分。
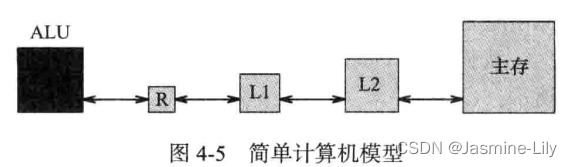
通常,主存的大小是几十或几百MB;二级缓存的大小不足1MB;一级缓存的大小是几十KB;寄存器的数量在8和32之间。程序开始运行时,所有数据都在主存。
要执行一个算术运算,例如加法,首先把相加的数据从主存移到寄存器,然后把寄存器的数据相加,最后把结果写人主存。
我们把寄存器的数据相加所需要的时间作为一个周期。把一级缓存的数据送到一个寄存器所需要的时间是两个周期。如果需要的数据没有在一级缓存,而是在二级缓存,即一级缓存未命中,那么把需要的数据从二级缓存送到一级缓存和寄存器需要10个周期。当需要的数据没有在二级缓存,即二级缓存未命中时,把需要的数据从主存复制到二级缓存、一级缓存和寄存器需要100个周期。我们把写操作,甚至向主存的写操作,算作一个周期,因为不需要等到写操作完成之后再进行下一个操作。
4.5.2 缓存未命中对运行时间的影响
就是会增加程序的运行时间。
减少缓存未命中的数量:目的是减少程序的运行时间,把最近需要处理的数据预载到缓存中,当出现一个缓存未命中时,把需要的数据和相邻字节中的数据装入缓存中。当连续的计算机操作使用的是相邻字节的数据时,这个策略很有效。
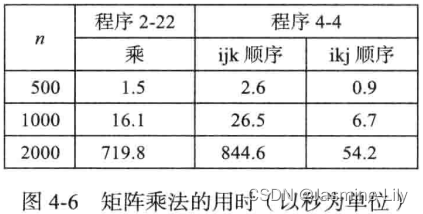
4.5.3 缓存未命中举例-矩阵乘法

把程序4-4的三层嵌套for循环重新排列一下顺序,结果是不变的。我们把程序4-4的嵌套循环顺序称为ijk。当我们把第二层和第三层的for循环交换次序,我们得到的嵌套循环顺序是ikj。一共有3!=6种嵌套循环顺序。由6种嵌套循环顺序分别生成的函数都以同样的数量执行每一种类型的操作。因此你也许认为这些函数所需的运行时间也是相同的。但是错了。改变了循环的次序,也就改变了数据访问模式,进而改变了缓冲未命中的数量,最终影响了运行时间。
在ijk顺序中,数组a和c的元素是按行访问的,数组b的元素是按列访问的。因为同行的元素在存储中是相邻的,而同列的元素在存储中是分开的,所以当数组很大,以至三个数组不能同时存储在二级缓存L2中的时候,访问数组b可能导致很多二级缓存未命中的事件。 在ikj的顺序中,数组a、b和c的元素是按行访问的,因此二级缓存未命中的事件就比较少,因此所需时间也比较少。
















 1291
1291











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











