







跟着吴恩达老师学习机器学习的 第一天,呜呜呜呜呜,我好菜,加油加油!!!
定义
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
简单来说就是在经验学习中改善具体算法的性能。

分类
- 监督学习
- 无监督学习
监督学习
监督学习即算法预测(如房价预测、肿瘤分析),常见的算法包括回归分析(regression,预测一个连续值输出)和统计分类(classification,预测离散值输出)。

无监督学习
给定的数据集没有标签、分类,要求从数据集中找出数据的类型结构。

单变量线性回归
数据集即训练集。m表示训练样本的数量,x表示输入变量即输入特征,y表示目标变量。
代价函数
对于回归问题,我们需要求出代价函数来求解最优解,常用的是平方误差代价函数。
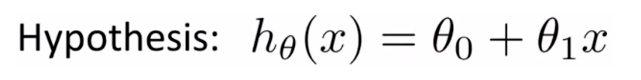
现实的例子中,数据会以很多点的形式给我们,我们想要解决回归问题,就需要将这些点拟合成一条直线,找到最优的 θ0 和 θ1 来使这条直线更能代表所有数据。
如何找到最优解呢,就需要使用代价函数来求解了,以平方误差代价函数为例,最优解即为代价函数的最小值。
平方误差代价函数的主要思想就是将实际数据给出的值与我们拟合出的线的对应值做差,求出我们拟合出的直线与实际的差距。
为了使这个值不受个别极端数据影响而产生巨大波动,采用类似方差再取二分之一的方式来减小个别数据的影响。这样,就产生了代价函数: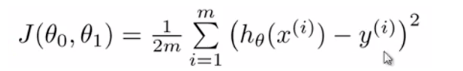
最优解即为代价函数的最小值:
注意:假设函数hθ(x)是关于x的函数,代价函数J(θ0,θ1)是关于θ0、θ1的函数。
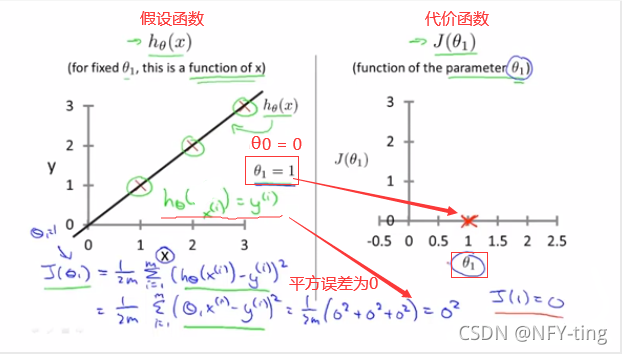
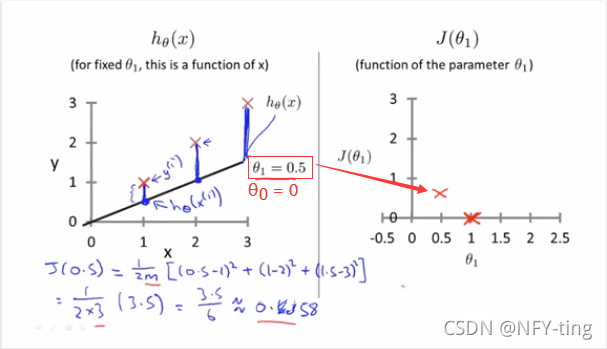
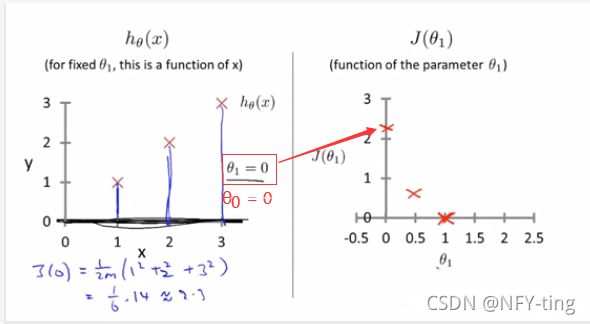
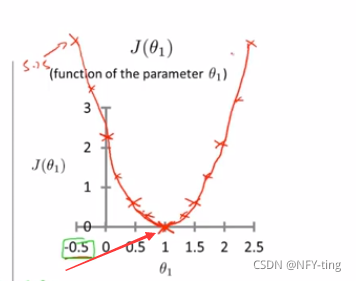
所以在上述的假设函数中,最优解应该是θ1=1,注意此时是只考虑了θ1没有考虑θ0,所以代价函数的图形为平面图形。
接下来探究关于θ0、θ1的代价函数:
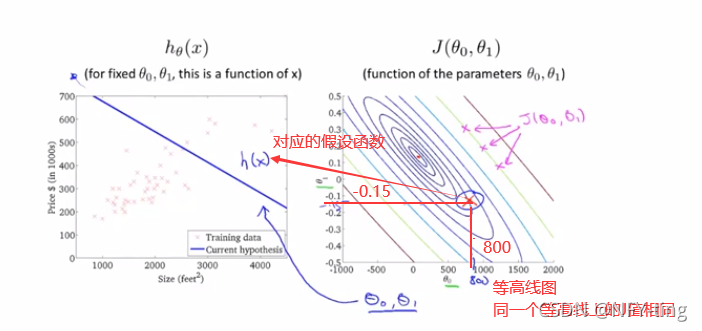
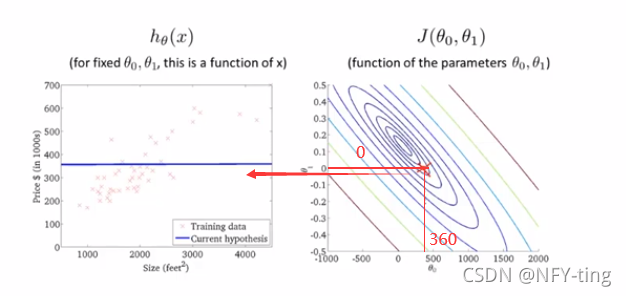
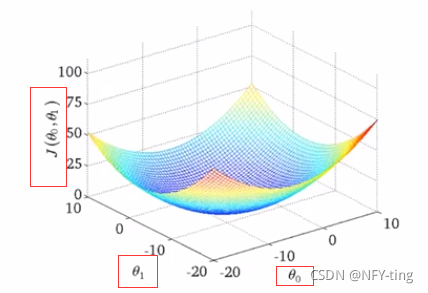
如果更多参数的话,就会更为复杂,两个参数的时候就已经是三维图像。高度即为代价函数的值,可以看到它仍然有着最小值的,而到达更多的参数的时候就无法像这样可视化了,但是原理都是相似的。















 828
828











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









