






学习目标:
Refining Generative Process with Discriminator Guidance in Score-based Diffusion Models (DG)
学习时间:
4.1-1.7
学习产出:
Abstract
- 介绍了一种利用辅助判别器进行分数调整的生成式SDE。目标是通过估计预训练得分估计值与真实数据得分之间的差距,改进预训练扩散模型的原始生成过程。
- 方法:通过训练一个鉴别器来完成,它可以对扩散的真实数据和扩散的样本数据进行分类。
1、Introduction
- 介绍了一种提高给定预训练评分网络样本质量的正交方法,即直接量化预训练分数估计与真实数据分数之间的差距,并通过辅助判别器网络估计这一差距。
- 通过将估计的差距与预训练的分数估计相加来构建调整后的分数,鉴别器的饱和速度非常快(在10个epoch内),因此可以通过廉价的预算实现如此显著的性能提升。
- 贡献:
- 提出了一种新的生成过程——判别器引导,对给定的预训练分数模型进行调整。
- 表明鉴别器引导样本比非引导样本更接近真实世界的数据
2、Preliminary and Related Works
Score-Based Generative Modeling through Stochastic Differential Equations

1、正向SDE:
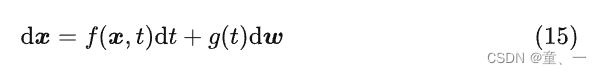
系数只与时间t和当前时刻取值x有关
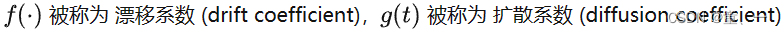
DDPM的公式:
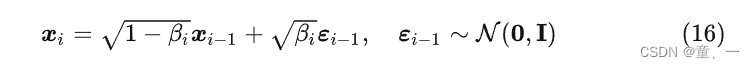
将DDPM写成类似SDE的形式
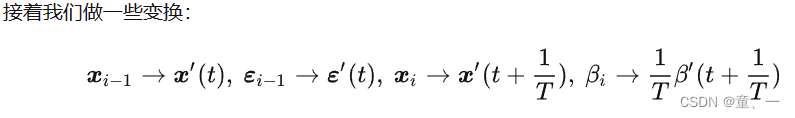


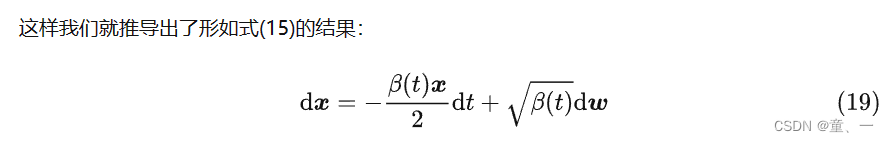
2、逆向SDE
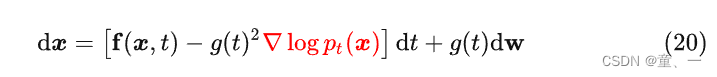
即

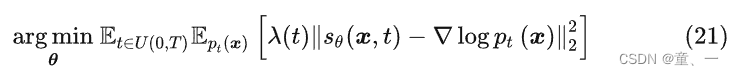
将式20写成ODE形式
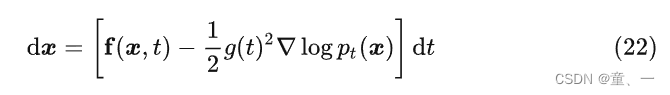
3、得分匹配
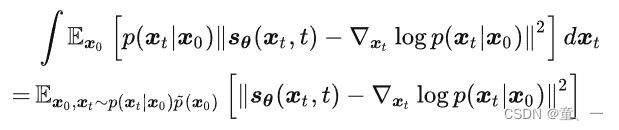
3、Refining Generative Process with Discriminator Guidance
3.1 修正预训练分数估计
分数训练后,根据时间步逆推生成过程(逆向SDE过程):
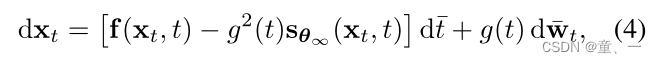
Sθ∞代表收敛后的评分网络,如果θ∞偏离全局最优θ【θ∞≠θ 】则需要使用修正项进行调整。
根据论文中证明本论文逆向过程与逆向SDE一致的定理1可进一步细化式(4):
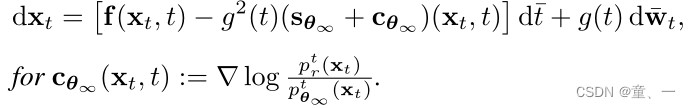
3.2. Discriminator Guidance
cθ∞通常难以处理,因为密度比ptr / ptθ∞是不可接近的。因此,通过训练一个带有附加扩散时间t参数的鉴别器来估计这个密度比。鉴别器训练使用BCE
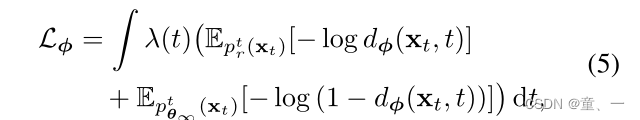
λ为时间权值。鉴别器将扩散的真实数据xt ~ ptr分类为真实数据,将扩散的样本数据xt ~ pθ∞分类为虚假数据。
则修正项可表示为:
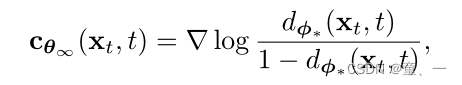
使用BCE损失的最小网络表示:
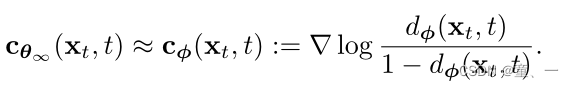
那么DG模型的逆向为:

鉴别器训练过程:

鉴别器快速收敛提高了样本质量

3.3. 与分类器引导联系
将鉴别器与预训练的分类器联系起来。
分类器引导的生成过程: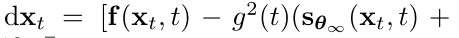
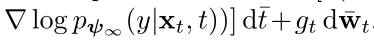
上述公式等价于从(xt,y)的联合分布中采样,因为:
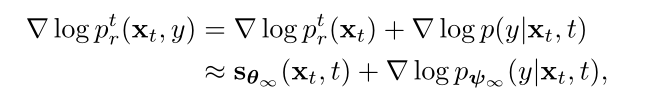
p(y|xt,t)是在t处的分类器。分类器引导通过评估样本是否被类别标签y正确分类来提供关于样本路径的辅助信息,而鉴别器引导是标签不可知的,它只给出样本是否真实的信息。由于从联合分布p(xt,y)中采样只有在分数准确时才有效,因此鉴别器引导通过调整不准确的分数估计与分类器引导产生协同作用。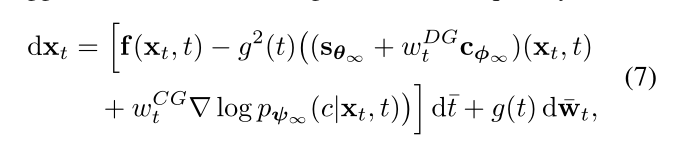
WtDG和WtCG是随时间变化的权重。














 2129
2129











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









