







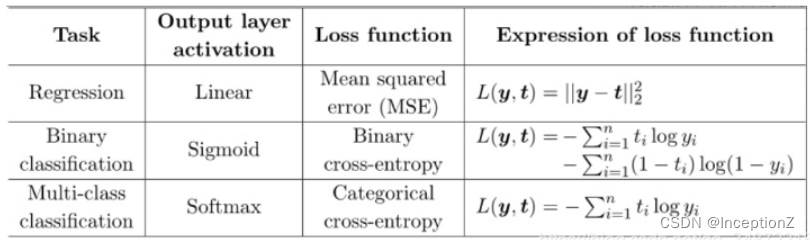
本文尝试回答一下几个问题:
- 为什么分类问题用交叉熵损失而不用均方误差?
- 回归问题为什么不适用交叉熵损失?
1. 为什么分类问题用交叉熵损失而不用均方误差?
开始阅读前,请复习一下softmax的反向传播求导,这一点很重要,有助于理解本问题!!!
首先给出该问题的结论:

常规分类网络最后的softmax层如下图所示:
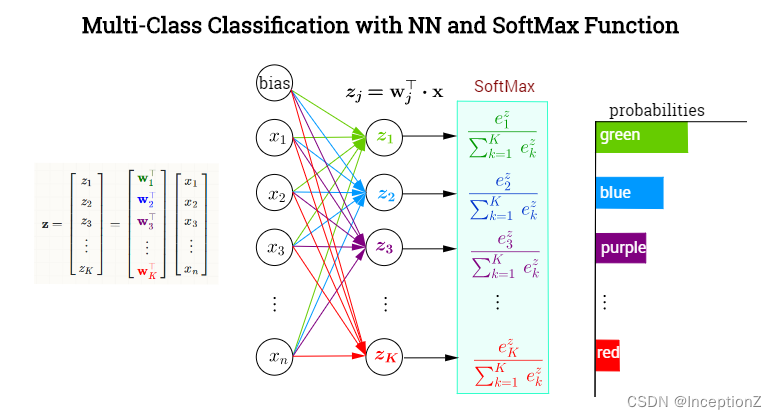
上图为K分类神经网络,令网络的输出为
[
y
^
1
,
…
,
y
^
K
]
\left[\hat{y}_{1}, \ldots, \hat{y}_{K}\right]
[y^1,…,y^K],其对应每个类别的概率;令label为
[
y
1
,
…
,
y
K
]
[y_{1}, \ldots, y_{K}]
[y1,…,yK]。对于某个属于p类的样本,其label中
y
p
=
1
y_{p}=1
yp=1,
y
1
,
…
,
y
p
−
1
,
y
p
+
1
,
…
,
y
K
y_{1}, \ldots, y_ {p-1}, y_{p+1}, \ldots, y_{K}
y1,…,yp−1,yp+1,…,yK均为0。
对于这样的样本,交叉熵损失为:
L = − ( y 1 log y ^ 1 + ⋯ + y K log y ^ K ) = − y p log y ^ p = − log y ^ p \begin{aligned} L &=-\left(y_{1} \log \hat{y}_{1}+\cdots+y_{K} \log \hat{y}_{K}\right) \\ &=-y_{p} \log \hat{y}_{p} \\ &=-\log \hat{y}_{p} \end{aligned} L=−(y1logy^1+⋯+yKlogy^K)=−yplogy^p=−logy^p
均方差损失为:
L = ( y 1 − y ^ 1 ) 2 + ⋯ + ( y K − y ^ K ) 2 = ( 1 − y ^ p ) 2 + ( y ^ 1 2 + ⋯ + y ^ p − 1 2 + y ^ p + 1 2 + ⋯ + y ^ K 2 ) \begin{aligned} L &=\left(y_{1}-\hat{y}_{1}\right)^{2}+\cdots+\left(y_{K}-\hat{y}_{K}\right)^{2} \\ &=\left(1-\hat{y}_{p}\right)^{2}+\left(\hat{y}_{1}^{2}+\cdots+\hat{y}_{p-1}^{2}+\hat{y}_{p+1}^{2}+\cdots+\hat{y}_{K}^{2}\right) \end{aligned} L=(y1−y^1)2+⋯+(yK−y^K)2=(1−y^p)2+(y^12+⋯+y^p−12+y^p+12+⋯+y^K2)
则m个样本的损失为:
ℓ = 1 m ∑ i = 1 m L i \ell=\frac{1}{m} \sum_{i=1}^{m} L_{i} ℓ=m1∑i=1mLi
对比交叉熵损失与均方误差损失,只看单个样本的损失即可,下面从两个角度进行分析
1.1 损失函数角度分析
对比家插上和均方误差损失,可以发现,两者均在 y ^ = y = 1 \hat{y}=y=1 y^=y=1时取得最小值,但在实践中 y ^ p \hat{y}_{p} y^p智慧趋近于1而不是恰好等于1,在 y ^ p < 1 \hat{y}_{p}<1 y^p<1的情况下:
- 交叉熵只与label类别有关, y ^ p \hat{y}_{p} y^p越趋近于1越好
- 均方误差不仅与 y ^ p \hat{y}_{p} y^p有关,还与其他项有关,它希望 y ^ 1 , … , y ^ p − 1 , y ^ p + 1 , … , y ^ K \hat{y}_{1}, \ldots, \hat{y}_{p-1}, \hat{y}_{p+1}, \ldots, \hat{y}_{K} y^1,…,y^p−1,y^p+1,…,y^K越平均越好!
这里解释一下第二条中为什么越平均越好,这里引入不等式法则:

当且仅当如下条件时,等号成立
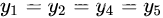
接下来是本小结重点:

而对交叉熵损失,既然类别间复杂的相似度矩阵是难以量化的,索性只能关注样本所属的类别,只要
y
p
y_{p}
yp越接近1就好,这显然是更合理的!
1.2 梯度的角度
这里仅考虑输出层即可,即输出层加上softmax或者sigmoid,因为隐藏层的梯度与其激活函数紧密相关,最终决策分类结果还是softmax或者sigmoid层
下面以softmax为例分析


如果是输出层用的是sigmoid激活函数,也会出现同样问题,这里可以参考:看这个链接的末尾
2. 回归问题为什么不使用交叉熵损失
思考对于回归问题,一般来说是需要预测一个连续值(-∞,+∞);而交叉熵在机器学习任务中通常遇到的场景是标签是离散的,因为如果标签是连续的,无疑会出现积分,计算量大,模型训练时间长。并且在不考虑标签归一化的情况下,如果把一个连续的值,且不在(0,1)范围内的,带入到离散型的交叉熵计算公式中,违背了概率理论。(因为离散情况下,要求概率和为1)
















 5711
5711











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











