






摘要
知识图中的关系预测旨在预测不完全三元组中缺失的关系,而主流的嵌入范式在测试过程中对不可见实体的处理有限制。在现实场景中,归纳设置更常见,因为训练过程中的实体是有限的。以往的方法利用kg中的隐式逻辑获取归纳能力,但难以精确获取组合逻辑规则的实体无关的关系语义,也难以应对关系语义的稀缺导致的逻辑监督不足。为此,我们提出了一种新的基于图卷积网络(GCN)的LogCo模型,并通过对比表示进行逻辑推理。LogCo首先提取两个实体之间的封闭子图和关系路径,以提供实体独立性。针对监督不足的问题,提出了关系路径实例与子图的对比策略。对于联合训练机制,我们学习了对比表征。最后给出了预测结果和推理的逻辑规则。在12个归纳数据集上的综合实验表明,与SOTA归纳基线相比,LogCo具有出色的性能。
介绍
知识图通过由实体和关系组成的三元组来存储大量的事实。它们被广泛应用于不同的应用场景,如关系提取(Hu et al, 2021)、问题回答(Abdelaziz et al, 2021)和信息检索(V erlinden et al, 2021)。从上下文中提取三元组需要消耗大量资源。因此,一些主要的方法是通过学习关系和实体的表示来实现KG补全或关系预测,例如TransE(Bordes et al, 2013), RESCAL (Nickel et al, 2011), R-GCN (Schlichtkrull et al, 2018) and CompGCN (V ashishth et al, 2020).
然而,上述方法预测关系假设为一个转导设置,这意味着实体在训练和测试期间是固定的。在应用程序场景中,在测试期间将会有新的实体。对于图1(a)中的场景,训练实体和测试实体没有交集,因此如果不重新训练整个模型,之前的传导方法将无法准确预测测试集中实体Bill Gates和W.A.之间的关系。因此,一些研究如GraiL (Teru et al, 2020)更关注具有归纳能力的模型,这种模型可以通过拟合人类认知的隐式一阶逻辑规则(Horn, 1951)来处理看不见的实体。例如,通过以下逻辑规则r1:
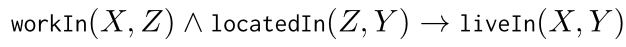
可以推断出测试子图中的关系liveIn。但现有模型主要利用kg中实体和三元组的拓扑结构,归纳关系预测中还存在两个挖掘逻辑问题。首先,归纳关系预测在测试集中存在不可见的实体,这就要求模型在推理时具有实体独立性。虽然kg中的隐式逻辑规则提供归纳能力,但之前的方法(Mai等人,2021;Teru et al, 2020)只关注实体信息,在对实体独立性更为关键的规则的关系语义建模方面存在困难。例如,图1(b)表示r1的归纳预测过程。训练实体Trump、Grand Hyatt和n.y.被泛化为图1(b)中红色标记的变量X、Y、Z。它表明实例化的实体在预测关系liveIn方面不如关系序列(workIn, locatedIn)重要。

其次,虽然逻辑推理提供了归纳能力,但关系语义的稀缺导致了对逻辑规则的监管不足。主流逻辑推理方法(Meilicke et al, 2019)表明,在一个拥有m种关系的KG中,长度N以内的候选规则数量为O(mN),而在真实KG中,逻辑推理过程中只包含少量规则。例如,在图1(b)中,实际上有4个规则的长度在3以内,从Trump到n.y.,但至少有83 = 512个候选规则。规则以千克为单位的详细统计情况如表1所示。需要注意的是,我们将关系路径的数量视为规则的数量,如图1(b)中的蓝色粗路径。由于不可能获得所有有监督的候选逻辑规则,从而限制了归纳关系预测的性能
其次,虽然逻辑推理提供了归纳能力,但关系语义的稀缺导致了对逻辑规则的监管不足。主流逻辑推理方法(Meilicke et al, 2019)表明,在一个拥有m种关系的KG中,长度N以内的候选规则数量为O(m的N次方),而在真实KG中,逻辑推理过程中只包含少量规则。例如,在图1(b)中,实际上有4个规则的长度在3以内,从Trump到n.y.,但至少有8的3次方 = 512个候选规则。规则以千克为单位的详细统计情况如表1所示。需要注意的是,我们将关系路径的数量视为规则的数量,如图1(b)中的蓝色粗路径。由于不可能获得所有有监督的候选逻辑规则,从而限制了归纳关系预测的性能。
为了解决上述问题,我们提出了一个LogCo模型,用于使用对比表示进行逻辑推理的归纳关系预测。LogCo首先在目标关系和关系路径之间抽取预设长度的子图。关系路径将引入关系序列语义,这对于逻辑推理中的实体独立更为重要。其次,通过构建正向和负向关系路径,在LogCo中引入了一种针对逻辑规则监管不足的对比策略。然后,LogCo使用GCN获得结构表示。同时包含拓扑结构和关系序列语义的正样本和负样本都被发送到模型中进行对比表示。最后,LogCo采用了一种结合监督信息和自我监督信息的联合培训机制。逻辑推理由关系路径和目标关系来说明,它们分别被认为是逻辑规则的主体和头部。
我们的主要贡献有三方面:
将关系路径和目标关系分别作为逻辑规则的主体和头部,首次将神经网络模型和离散逻辑集成到LogCo归纳关系预测中。
为了满足KGs中归纳预测的实体独立性,我们将关系路径表示为逻辑规则。针对逻辑推理监督不足的问题,设计了对比策略。LogCo最早通过关系路径对实体无关语义进行补充,并在归纳关系预测中引入对比表示。
在12个归纳数据集上的关系预测实验验证了LogCo与最新归纳方法相比的优越性。同时,LogCo可以获得推理可解释性的逻辑规则。
预备
本节简要介绍一阶逻辑规则及其与关系路径的关系。从KGs中学到的一阶逻辑规则(Muggleton, 1991)是一个Horn子句(Poole, 1993),它由一个原子作为头部和一系列原子作为主体组成。

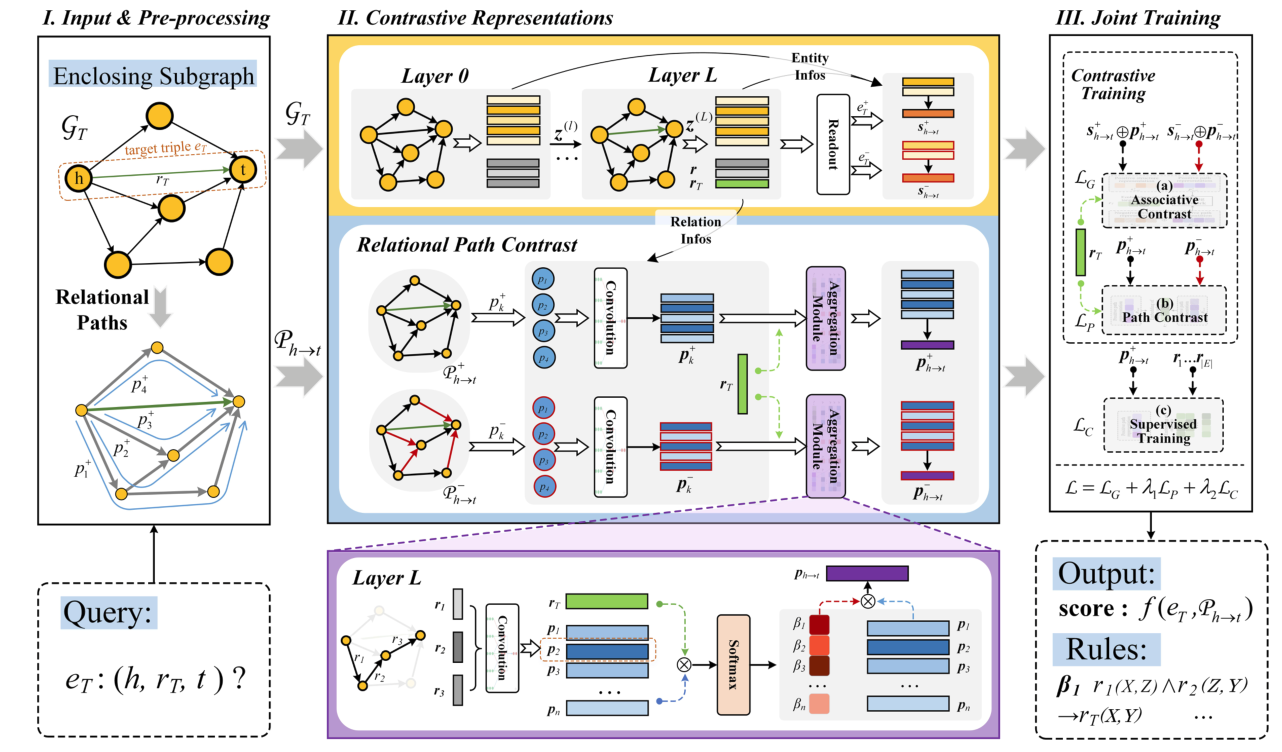
图2:LogCo的整体框架。它首先从KG中提取外围子图和关系路径。然后利用GCN得到子图和关系路径的对比表示。带红框的嵌入是否定的表示。最后,采用联合训练机制对预测模型进行优化。LogCo同时输出预测结果和逻辑规则。
方法
任务定义
初始化和对比构造


对比表示



实验
在本节中,我们首先介绍基准、基线、实验设置和细节。其次,为了验证LogCo算法的有效性,我们对关系预测任务进行了对比实验。然后,我们使用消融研究、权重分析和案例研究来全面论证其性能。
实验设置
Datasets
感应链路预测数据集来源于WN18RR (Dettmers et al, 2018)、FB15K-237 (Toutanova et al, 2015)和NELL995 (Xiong et al, 2017),每一个都分为四个版本。基准数据集的统计数据见(Teru et al, 2020)。数据集的每个版本都由训练kg和测试kg组成,它们的实体完全不同,表明完全归纳设置。
Baselines
用于比较的归纳基线包括基于规则的RuleN (Meilicke等人,2018)、Neural-LP (Yang等人,2017)和DRUM (Sadeghian等人,2019),以及基于图形的GraIL (Teru等人,2020)、CoMPILE (Mai等人,2021)、TACT (Chen等人,2021)和RED-GNN (Zhang和Yao, 2022)。我们还比较了TransE (Bordes et al, 2013)和CompGCN (V ashishth et al, 2020)两种换能器方法,以说明它们对归纳预测的有效性。
Metrics
在比较中,考虑到随机种子和样本,我们实现了分类和排名指标来评估模型的多次运行。AUC-PR是分类任务计算预测召回曲线下面积的一个指标,用于评估三元组是否为真。对于排名指标Hits@10,我们在一般模式下评估它,通过在50个随机负样本中对测试三元组进行排名,并查看真实三元组是否能排名前10。
实验的细节
对于子图提取,我们通过双顶点标记获得3跳封闭子图。在图嵌入过程中,我们采用了一个维数为32的3层GCN。我们在NVIDIA的Tesla V100显卡上实现了实验。不同的参数可能会影响不同数据集上的性能,因此参数是分开调优的。在训练过程中,批大小设置为16,我们使用Adam (Kingma and Ba, 2015)作为优化器,学习率为0.001。在提取关系路径时,我们选择最大长度为Lmax = 2和3。对于超参数λ1和λ2,我们选择λ1, λ2∈[0.8,1.2],我们将在第4.4.1小节中解释这种选择
比较结果
预测结果比较
从表2中关系预测的对比结果可以看出,LogCo明显优在绝大多数数据集。
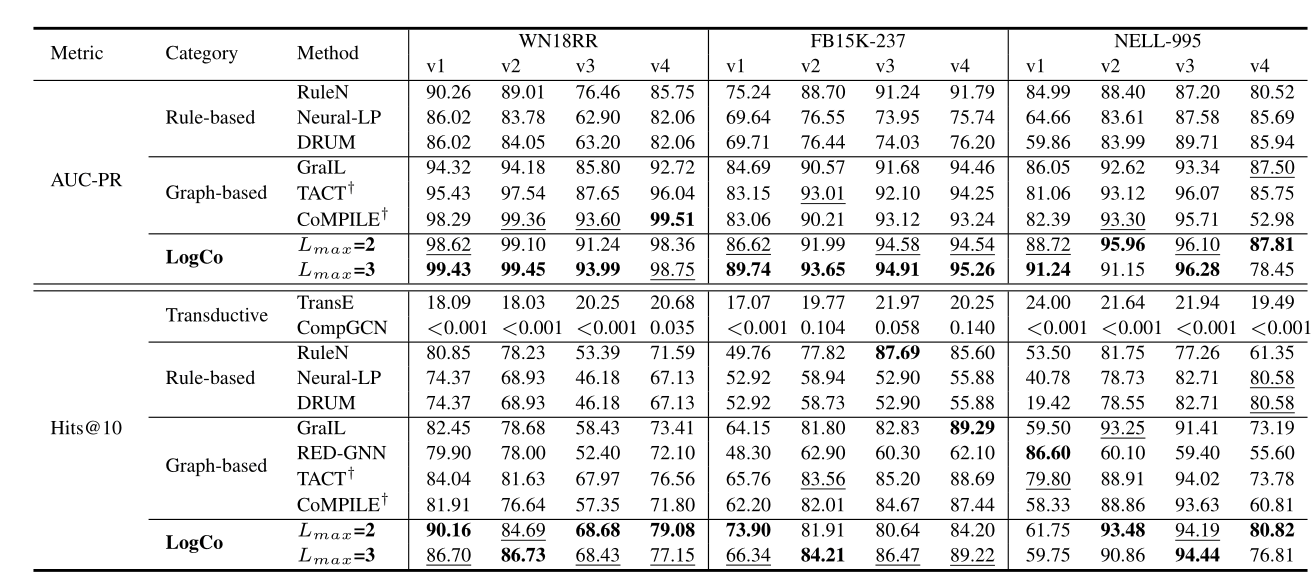
WN18RR, FB15K237和NELL-995的感应基准上AUC-PR(%)和Hits@10(%)结果的比较。†意味着我们通过原始代码重现项目。其他结果来自(Teru et al, 2020)和(Zhang and Y ao, 2022)。最优值和次优值分别用粗体和下划线标记。
对于传导方法,从表2中可以明显看出,它们不适合解决归纳推理,因为Hits@10结果较低。对于基于规则的归纳方法,在AUC-PR中LogCo对WN18RR、FB15K-237和NELL-995的平均boost分别为12.54%、6.65%和7.55%,与基于规则的方法RuleN相比。
经过观察,基于图的归纳方法在大多数数据集上通常比基于规则的方法更有效。与更具竞争力的基于图形的归纳法相比,LogCo在两个指标上的结果都是最优的,这也说明了LogCo的优越性。与GraIL相比,LogCo在AUC-PR中平均性能提高了6.15%,3.04%和2.95%,GraIL是一种基本的基于图的归纳法。对于SOTA方法RED-GNN, CoMPILE和TACT,我们的方法在相同的实验环境中,就这两个指标而言,在大多数数据集上表现更好。这种细微的差异可能是由于LogCo中关系路径的长度是固定的。
除了在训练过程中采样一条负关系路径外,我们实现了多条负关系路径的LogCo。但随着时间的增加,预测结果略有增加。例如,WN18RR_v1上有一个阴性的AUC-PR为99.43%,每epoch花费23.66s,有两个阴性的AUC-PR为99.79%,每epoch花费42.19s。更多结果见附录C.1。另外,我们在Lmax > 3时实现LogCo。但是在提取关系路径时存在循环和噪声,时间越长预测结果越差。当Lmax = 4时,LogCo在WN18RR_v1上的AUC-PR为98.86%。因此,我们记录Lmax = 2,3时的结果。
复杂性比较
此外,LogCo比SOTA方法需要的参数更少,这意味着我们实现了更低的模型复杂性。12个数据集的参数数量如图3(a)、(b)、(c)所示,其中橙、蓝、绿柱分别为TACT、CoMPILE、LogCo的参数数量。结果表明,CoMPILE在WN18RR上需要更多的参数,TACT在FB15K-237和NELL-995上需要多个参数。LogCo在所有12个数据集的复杂性方面表现更好。在WN18RR_v4上LogCo的结果略低于CoMPILE,但是LogCo有17288个参数,而CoMPILE有34465个参数,从一个方面反映了LogCo的优势。

烧蚀结果

我们研究了关系路径对逻辑推理和对比的影响。表3和表4是LogCo在没有所有数据集上的因子的情况下训练模型的结果,方法分别分为两部分。特别是,1)“LogCo w/o路径”删除了LogCo中的关系路径。2) LogCo#1消除了联想对比。3) logco# 2与logco# 1相比,删除了路径对比。∆表示烧蚀模型与LogCo之间的减小。其他参数在训练和测试期间保持不变,以便进行公平的比较。
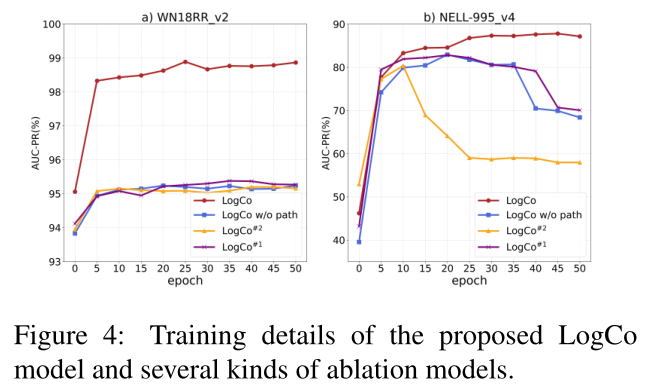
从表3和表4可以看出,AUC-PR和Hits@10值的降低说明我们在LogCo上的贡献都对归纳关系预测有积极的影响。此外,它表明关系路径和对比在NELL-995上比其他两个数据集更有效。特别是,表3中“LogCo w/o Paths”和“LogCo#2”的更大的缩减量验证了路径和对比同时作用时的有效性更明显。这可能是因为更多的规则为逻辑推理提供了更多的关系语义。我们还使用图4来说明LogCo和三个烧蚀模型在三个版本的数据集上的训练细节。通过将AUCPR值与“LogCo w/o path”、“LogCo#1”和“LogCo#2”进行比较,可以明显地看出,在50个epoch之后,LogCo在两个数据集上的学习效果更好,这代表了LogCo的有效性。
权重分析
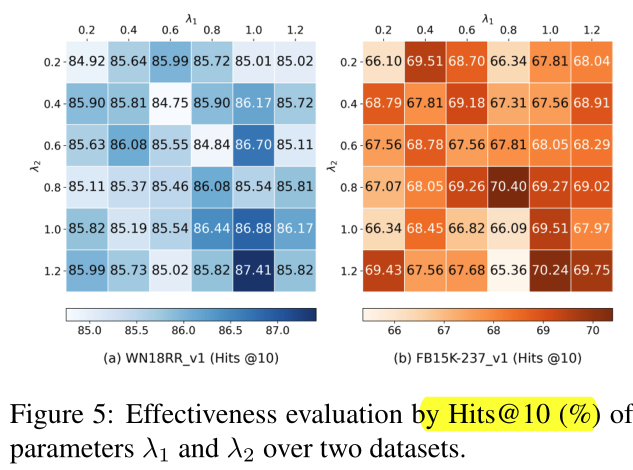
在我们的模型中,λ1和λ2对于训练过程中监督学习和自监督学习的调节功能至关重要,因此我们在λ1和λ2∈[0.2,1.2]的不同值下重新运行训练过程,并在WN18RR_v1和FB15K-237_v1上记录5次测试的平均结果,如图5所示。
案例研究
如第3节所述,LogCo的一个关键优势是显式地表示逻辑推理的一阶规则。表5显示了LogCo在三个数据集上的派生规则示例。每个规则前面的值是相应子图中的置信度值。同一块中的规则具有相同的头部,头部是从一个精确的目标三重中泛化出来的,主体是从预测时的推理路径中泛化出来的。权重β < 0.01的红色规则表示推理时规则不合理。在预测关系时,它们对于逻辑推理不那么重要。总的来说,LogCo通过这些明确的规则实现了可解释性。

相关工作
KGs中的归纳学习
可分为基于规则的和基于图的两个方面。尽管有补充资料的作品,基于统计规则的方法(Galárraga et al, 2013, 2015;Meilicke等人,2018)提出在没有外部知识的情况下求解看不见的实体。他们通过枚举所有候选kg,从kg中归纳出内在规则,并根据预设的阈值选择规则。为了提高可扩展性和减少计算时间,提出了其他可微模型。NeuralLP (Yang et al, 2017)和DRUM (Sadeghian et al, 2019)通过神经控制器系统获取规则,特别是后者捕获规则中原子顺序的前后向信息。这些方法都是基于TensorLog (Cohen, 2016),用矩阵来表示三元组,会造成较高的空间复杂度。
为了解决可扩展性和复杂性问题,提出了一些基于图的归纳方法。GraIL (Teru et al, 2020)从kg中提取子图,并通过图神经网络(GNN)实现归纳能力。CoMPILE (Mai et al, 2021)加强了边和实体之间的消息交互。TACT (Chen et al, 2021)使用关系相关网络来提供关系之间的拓扑模式。REDGNN (Zhang和Y ao, 2022)提出了一个关系有向图来捕获KG的局部证据。
与之不同的是,LogCo同时考虑了这两个方面并利用了图结构,并在规则中捕获了与实体无关的关系语义,用于逻辑推理。
对比学习
对比学习的目的是通过编码相似或不同的样本来获得表示,以提高下游任务的有效性。对于文本的表示,CPC (van den Oord等人,2018)通过使用概率对比损失预测未来信息来获得上下文表示。对于图像,MoCo (He et al, 2020)通过建立一个动量对比损失的大而一致的字典来获得视觉表征。SimCLR (Chen等人,2020)宣称,数据增强的组成、更大的规模和更多的训练周期对于对比任务至关重要。在图网络中,提出了深度图信息max (V elickovic等人,2019)来对比图的补丁表示和相应的高级摘要。对比学习用于文本、图像、图形等。为解决规则监督不足的问题,创新性地将对比策略引入归纳关系预测中。
结论
我们提出了一种新的基于kg中对比表示的逻辑推理归纳关系预测模型,命名为LogCo。在这项任务中,我们要解决两个主要问题。为了从一阶逻辑规则中获得实体独立语义,LogCo在每个子图中提取关系路径。针对关系语义缺乏导致的逻辑规则监督不足的问题,LogCo引入对比表示来获得自监督信息。在12个全归纳数据集上的实验表明了LogCo的有效性,并全面证明了对关系路径和对比的影响。
局限性
LogCo仍然需要在性能和可伸缩性方面进行改进。在LogCo中,可以将路径提取方法开发为具有灵活长度的关系路径。此外,LogCo还可以应用到更多的场景中。例如,LogCo解决了全归纳预测,它可以扩展到传导和归纳学习。我们还打算在常识性知识图(Speer et al, 2017)上实现LogCo,其实体是用于高阶逻辑推理的自由形式文本。
















 501
501











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











