







神经网络的介绍:(2017.11-ICCV)Feed Forward and Backward Run in Deep Convolution Neural Network
常用优化函数的介绍:(2016.09-arXiv)An overview of gradient descent optimization algorithms
常用数据集:MSCOCO简介

持续更新:
最新——2019.10.10
| 一、知识点总结 |
?1、卷积层的作用、池化层的作用、全连接层的作用、激活函数的作用
- 卷积层:是一组平行的特征图(feature map),它通过在输入图像上滑动不同的卷积核并执行一定的运算而组成。作用如下:
- 相当于一个特征提取器来提取特征。
- 提供了位置信息。
- 减少参数个数。
- 池化层:指下采样层,它把前层神经元的一个集群的输出与下层单个神经元相结合。池化运算在非线性激活之后执行。(最大池化、平均池化、L2范数池化等)作用如下:
- 有助于减少参数的数量并避免过拟合。
- 可作为一种平滑手段消除不想要的噪音。(提取主要特征)
- 保持一定程度的旋转和平移不变性(最大汇合可以带来非线性)
- 全连接层:全连接层的每一个节点都与上一层每个节点连接,是把前一层的输出特征都综合起来,输出为一个值。所以该层的权值参数是最多的。作用如下:
- 起到“分类器”的作用(将学到的“分布式特征表示”映射到样本标记空间);
- FC可视作模型表示能力的“防火墙”(fine tuning中有FC比较好)
- 激活函数:定义了给定一组输入后神经元的输出。作用如下:
- 将线性网络输入值的加权和传递至激活函数以用于非线性转换。
- 激活函数决定是否应该激活神经元,即是否有参数传递。
?2、前向传播和反向传播
- 前向传播:从输入经过各种网络层,得到输出求得损失函数值的过程。
- 反向传播:通过损失函数值调节网络各层的参数值的过程。求偏导的过程。
?3、常见的激活函数(sigmoid、tanh、ReLU、Leaky ReLU、softmax)
激活函数应保证可微性、单调性。
- 激活函数输出值有限时,基于梯度的优化方法更加稳定;
- 输出无限的时候,模型的训练更加高效。
- 激活函数接在bn之后,所以激活函数的输入被限制在了 (-1, 1) 之间

sigmoid( 不建议使用):
- 输出值落在(0, 1)之间,期望均值为 0.5 ,不符合 均值为 0 的理想状态;
- 受现有的梯度下降算法所限(严重依赖逐层的梯度计算值),Sigmoid函数对落入 (-∞,-5) ∪ (5,+∞) 的输入值,梯度 计算为 0,发生 梯度弥散。因此该函数存在一正一负 两块“死区”
- 最大梯度为0.25,容易出现梯度消失;
tanh( 不建议使用):
- 将 期望均值 平移到了 0这一理想状态。(相对于sigmoid)
- 本质上依然是Sigmoid函数,依然无法回避一左一右两块 “死区”
✅ ReLU(目前标配):
- He初始化 (对relu网络有利);
- conv->bn->relu (默认采用relu);
- 彻底 消灭 了 正半轴上 的 死区,负半轴上 的 死区直接到 0点 ;
- 计算超简单;
- 有助于使模型参数稀疏
ReLU 6:f(x)=min(max(0,x),6)
- 正半轴上 的 死区 死灰复燃,从Relu的 (-∞,0) 蚕食至 Relu6的 (-∞,0) ∪ (6,+∞)
- 15年bn出来之后,输入被归一化到了 (-1, 1) 之间。因此,relu6的设计就显得没有必要。
Leaky ReLU:
- 对 Relu 函数 新增一 超参数 λ(0.01或者0.001),以解决负半轴的死区问题;
- 合适的 λ值 较难设定 且较为敏感,导致在实际使用中 性能不稳定
- 将 Leaky Relu 函数 中的 超参数 λ 设置为 和模型一起 被训练到 的 变量,以解决λλ 值 较难设定 的问题。优点:更大自由度。缺点:更大的过拟合风险。
?总结:
- Sigmoid 和 tanh(x) 不建议使用;
- Relu最常用;计算简单(反向传播涉及除法)、避免梯度消失(正向无饱和区)、防止过拟合(负向输出为0)
- 为了进一步提高模型精度,Leaky Relu、参数化Relu、随机化Relu 和 ELU 均可尝试(但四者之间无绝对的高下之分);
- “ conv -> bn -> relu ” 套件目前早已成为了CNN标配module。
?4、常见的优化函数(SGD、Adagrad、Adadelta、RMSprop、Adam、Nadam)
BGD(Batch gradient descent):
- 每次更新需要计算整个数据集的梯度,(慢!)
- 最后能够保证收敛于极值点(凸函数收敛于全局极值点,非凸函数可能会收敛于局部极值点)
SGD(Stochastic gradient descent):
- 更新针对每一个样本集x(i) 和y(i),每次则只更新一次。(快!)
- 以高方差进行快速更新,可以让梯度计算跳出局部最优,最终到达一个更好的最优点(目标函数出现会出现抖动);
MBGD(Min-batch gradient descent):
- 每一次利用一小批样本,n 个样本进行计算(n:50~256)
- 减少了参数更新的变化,这可以带来更加稳定的收敛;
- 可以充分利用矩阵优化,最终计算更加高效。(但是不保证好的收敛性!受学习率影响)
?总结以上三个:
- 都需要预先设置学习率,整个过程都采用相同的学习率进行计算。
- 选择一个合适的学习率是非常困难的事情
- 预先制定学习率变化规则
Momentum:
- 原理:判断当前梯度方向与上一次方向是否一致,一致则进行加强,反之,减弱;
- 优点:加速SGD算法的收敛速度;降低SGD算法收敛时的震荡
- 新增一阶动量
NAG(Nesterov accelerated gradient):
- 考虑的是上一时刻的动能和近似下一点的梯度。
Adagrad:
- 自适应优化算法,针对高频特征更新步长较小,而低频特征更新较大(适合应用在特征稀疏的场景)
- 新增二阶动量,使用不同的learning rate
- 缺点:随着训练的进行,学习率将会变得无限小,此时算法将不能进行参数的迭代更新。
Adadelta、RMSprop:
- 都是adagrad算法的优化版,用于解决adagrad算法学习率消失的问题
Adam(Adaptive Moment Estimation):
- 另一种自适应参数更新算法,
- 是RMSProp算法和Momentum的结合版,一阶与二阶动量结合
Nadam:
- Nesterov + Adam
?优化器选择总结:
- 当训练数据特征较为稀疏的时候,采用自适应的优化器(Adagrad, Adadelta, RMSprop, Adam);
- SGD通常训练时间更长,但是在好的初始化和学习率调度方案的情况下,结果更可靠
- Adam(Nadam)可能是最佳的选择。
 | 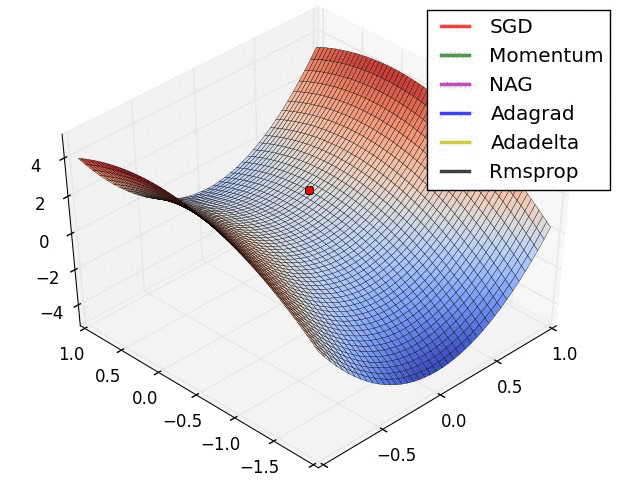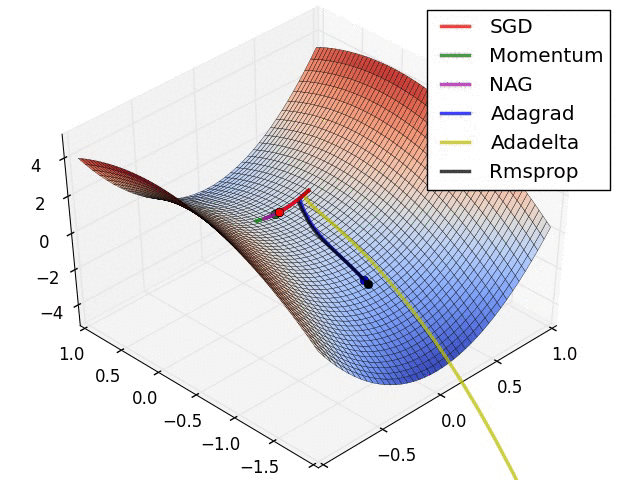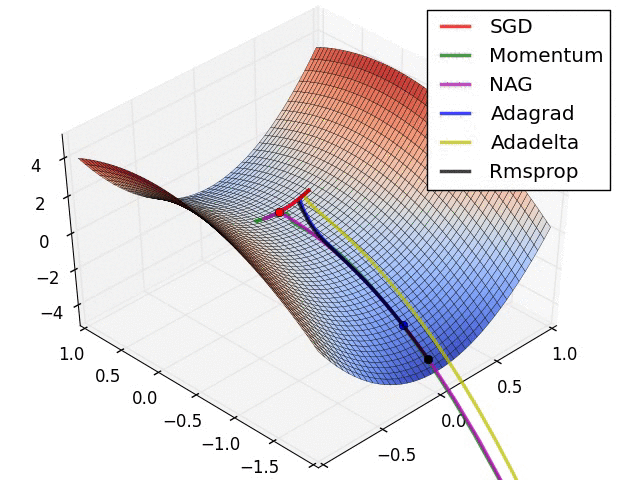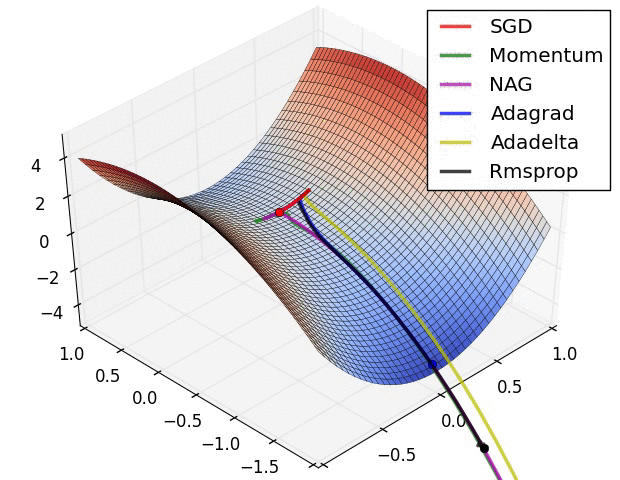 |  |
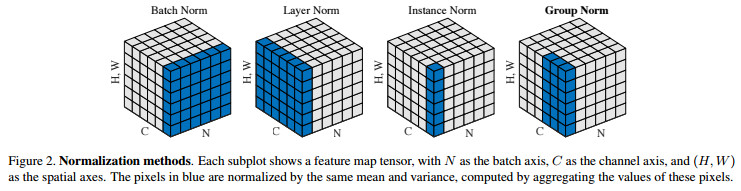
?5、常见的归一化(BN、LN、IN、GN、SN)
BN(Batch Normalization,2015.02):
- 沿着通道计算每个batch的均值和方差,求出归一化,
- 加入缩放和平移变量γ和β(用来学习的),使其符合标准正态分布。
- 针对不同神经元输入计算均值和方差,同一个batch中的输入拥有相同的均值和方差。(???)
- 缺点:对batchsize的大小敏感,太小的话不能代表整个数据集的分布。
- 适用于DNN、CNN,不适用RNN(因为深度不固定的原因)
?BN的作用:(学习率、激活函数、dropout、L2正则化)
- 对于初始化要求没那么高,可以使用更高的学习率;(BN之前同层不同层的scale都不一样,而需要使用最小的学习率才能保证梯度有效下降)
- 移除或使用较低的dropout,
- 降低L2正则化项权重衰减系数,
- 取消Local Response Normalization层;
- 可以解决反向传播过程中的梯度问题(它让每一层的输出归一化到了均值为0方差为1的分布,对激活函数友好)
LN(Layer Normalizaiton,2016.07):
- 同层神经元输入拥有相同的均值和方差,不同的输入样本有不同的均值和方差;(???)
- 适用于RNN效果比较明显,但是在CNN上,不如BN。
IN(Instance Normalization,2016.07):
- 可以加速模型收敛,保持每个图像实例之间的独立,适用于图像风格化。
GN(Group Normalization,2018.03):
- 将channel方向分group,然后每个group内做归一化,算(C//G)HW的均值;
- 与batchsize无关,不受其约束。
SN(Switchable Normalization,2018.06):
- 使用可微分学习,为一个深度网络中的每一个归一化层确定合适的归一化操作。
?归一化总结:
将输入的图像shape记为[N, C, H, W]:
- batchNorm是在batch上,对NHW做归一化,对小batchsize效果不好;
- layerNorm在通道方向上,对CHW归一化,主要对RNN作用明显;
- instanceNorm在图像像素上,对HW做归一化,用在风格化迁移;
- GroupNorm将channel分组,然后再做归一化;
- SwitchableNorm是将BN、LN、IN结合,赋予权重,让网络自己去学习归一化层应该使用什么方法。
?6、防止过拟合(overfit)的方法
- 正则化:即在对模型的目标函数(objective function)或代价函数(cost function)加上正则项。(L1正则与L2正则)理由:(比如拟合的三次项方程y=4x3 + 3x2 + 2x +5 为过拟合。因为加了正则化,变成了y= 3x2 + 2x +5)
- 提前停止迭代:当迭代过程中准确率不再上升时停止,或者是损失函数停止下降的时候。
- dropout:在每次训练过程中随机将部分神经元的权重置为0,即让一些神经元失效,这样可以缩减参数量。
- 数据集增广:重采样、加噪音、GAN也可以啊。
?7、正则化的定义(L1正则与L2正则):
为什么需要正则化:
- 结构风险最小化: 在经验风险最小化的基础上(也就是训练误差最小化),尽可能采用简单的模型,以此提高泛化预测精度。
- 正则化是结构风险最小化的一种策略实现。
正则化:
- 又叫做罚项,是为了限制模型的参数,防止模型过拟合而加在损失函数(目标函数)后面的一项。
 |  |  |  |  |
L1 正则化(lasso回归):
- 公式也很简单,直接在原来的损失函数基础上加上权重参数的绝对值之和(L1范数)。L1可以让一部分特征的系数缩小到0,从而间接实现特征选择。所以L1适用于特征之间有关联的情况。
L2 正则化(岭回归):
- 公式非常简单,直接在原来的损失函数基础上加上权重参数的平方和(L2范数)。L2让所有特征的系数都缩小,但是不会减为0,它会使优化求解稳定快速。所以L2适用于特征之间没有关联的情况。
缺点:
- 以增大训练误差为代价,来减少测试误差。
?8、二分类的评价指标:(准确率、精准率、召回率、混淆矩阵、AUC)
准确率:算法分类正确的数据个数/输入算法的数据的个数。类别不均衡,缺点:特别是有极偏的数据存在的情况下,不适用。
混淆矩阵:二分类问题的混淆矩阵由 4 个数构成。首先我们将二分类问题中,我们关心的,少数的那一部分数据,我们称之为正例(positive)。第 1 个字母表示算法预测正确或者错误,第 2 个字母表示算法预测的结果。
精准率:预测为正例的那些数据里预测正确的数据个数。例如,在预测股票的时候,我们更关心精准率。
召回率:真实为正例的那些数据里预测正确的数据个数。在预测病患的场景下,我们更关注召回率。
F1 score:精准率和召回率的兼顾指标:是精确率和召回率的调和平均数,最大为1,最小为0。。
ROC:平面的横坐标是false positive rate(FPR),纵坐标是true positive rate(TPR)。如果得到一个位于此直线下方的分类器的话,一个直观的补救办法就是把所有的预测结果反向,即:分类器输出结果为正类,则最终分类的结果为负类,反之,则为正类。
AUC:定义为ROC曲线下的面积(取值范围在0.5和1之间),AUC值大的分类器效果更好。
?9、常见卷积类型(卷积、反卷积、空洞卷积、可形变卷积)
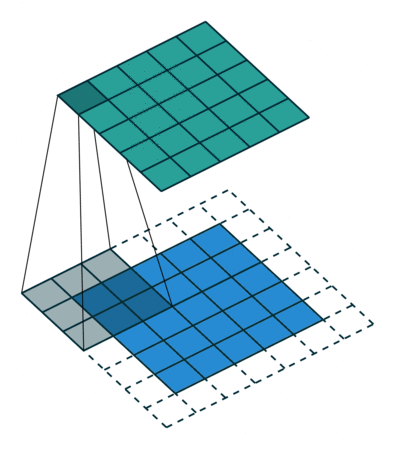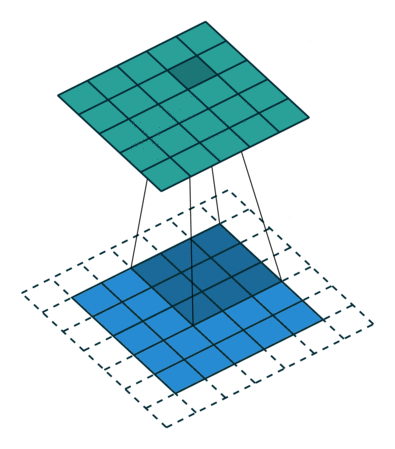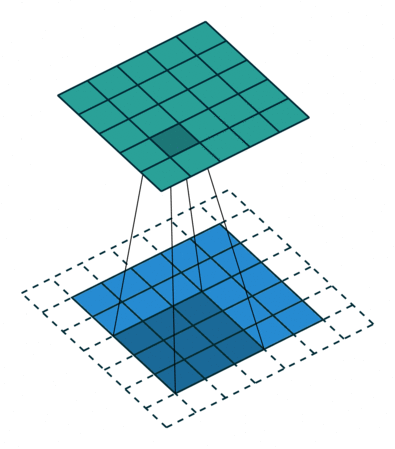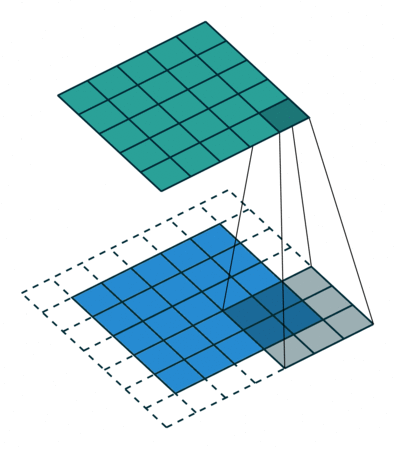 | 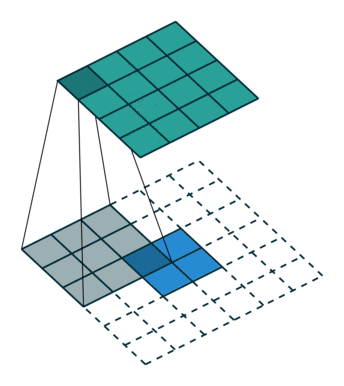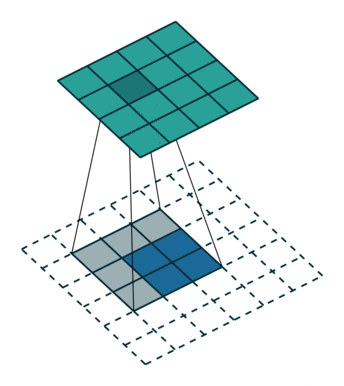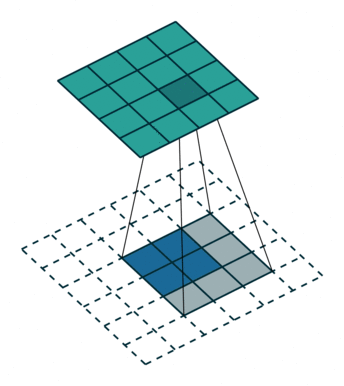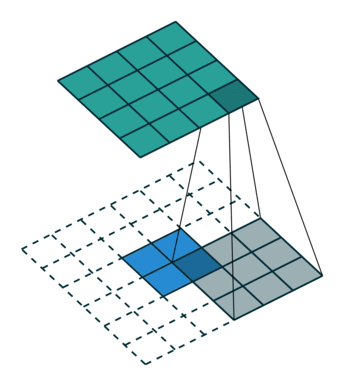 | 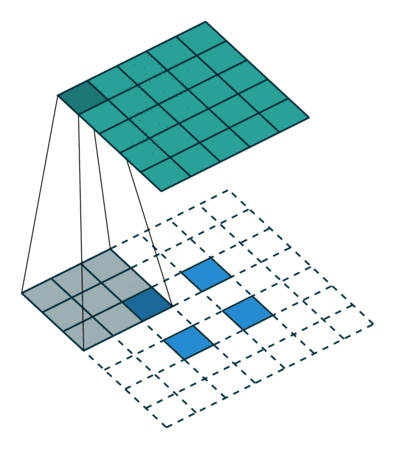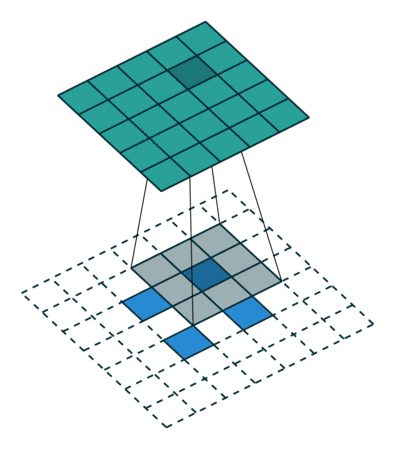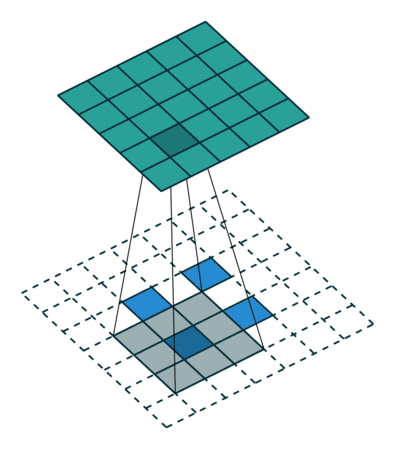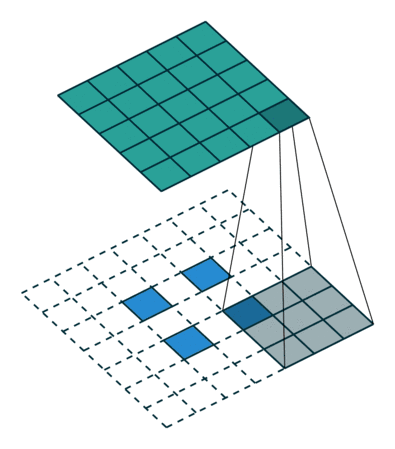 | 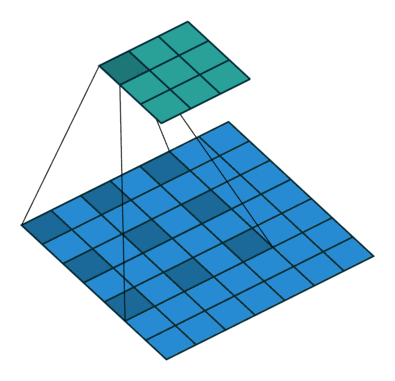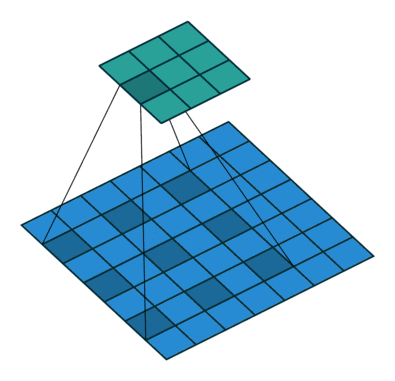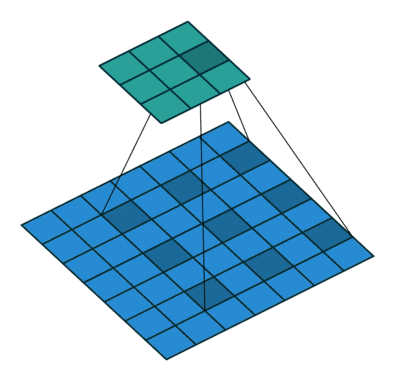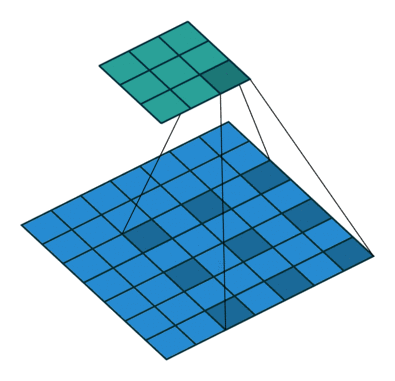 |
空洞卷积的作用:
- 在不增加计算量的基础上可以增大感受野。
- 感受野计算:3 + 4 x (r-1) (卷积核大小3x3、生在率:r)(正常卷积的r=1)
??可形变卷积(DCN V1:deformable convolution networks,2017.03)【论文原文】【参考】
- 感受野不再是规则的正方形(图1);
- 给每个采样点一个offset(通过额外的conv层学习得到,图2);
- 将input feature map和offset共同作为deformable conv的输入;
- ROI pooling通过一个额外的FC层来学习offset

 |  |
??可形变卷积(DCN V2:deformable convolution networks,2018.11)【论文原文】【参考】
动机:因为V1中的offset不可控导致引入了过多的context,而这些context可能是有害的。
改进:
- 增加更多的Deformable Convolution
- 让Deformable Conv不仅能学习offset,还能学习每个采样点的权重(modulation)
- 模拟R-CNN的feature(knowledge distillation)
缺点:不支持cudnn,速度慢。
?10、常见的损失函数()
0-1损失函数(0-1 lossfunction):
- 多适用于分类问题中,预测错误,输出值为1;明预测正确,输出为0。
- 缺点:过于理想,基本不用。
感知损失函数(Perceptron Loss):
- 对0-1损失函数的改进,给一个误差区间,只要在误差区间内,就认为是正确的。
平方损失函数(quadratic loss function):(欧式损失函数-非凸函数)
- 指预测值与真实值差值的平方,多用于线性回归任务中。
Hinge损失函数(hinge loss function):(合页损失)
- 通常适用于二分类的场景中,可以用来解决间隔最大化的问题,常应用于著名的SVM算法中。
对数损失函数(Log Loss):
- 常用于逻辑回归问题中,让概率p(y|x)达到最大值。
交叉熵损失函数(cross-entropy loss function):(凸函数0
- 本质上也是一种对数损失函数,常用于多分类问题中。
- 常用于当sigmoid函数作为激活函数的情景,因为它可以完美解决平方损失函数(多分类任务中,存在多个局部平缓区域)权重更新过慢的问题。
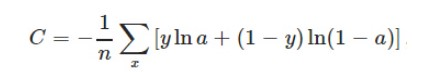
- 解决类别不平衡问题,调整正负样本的权重(负样本即包括背景);
- 对困难样本的损失分配比较大的权重,控制难易分类样本的权重。

?11、NMS非极大值抑制
对每一类进行NMS:
- 先根据score进行降序排序,
- 然后计算最高的score和其他框的iou,
- 去掉iou大于阈值的检测框。
?12、降低模型复杂的方法?
- (2015.03)模型蒸馏技术:将复杂网络中的有用信息提取出来迁移到一个更小的网络上。
- (2018.07)利用AutoML进行网络结构的优化:可将网络计算复杂度作为约束条件之一,得到更优的结构。
- (2017.04)mobile net :使用深度可分离卷积(depthwise separable convolutions)替代传统卷积
- (2017.07)shuffle net:逐点分组卷积、channel shuffle。
- 模型剪枝:将很多kernel的权重很小的删除,将剩余的权重进行重构。
- 量化:把连续的权值进一步稀疏化、离散化(比如4.01和3.99都用4.0来表示)
- 哈夫曼编码:数据重复越多,熵越低,哈夫曼编码就越能用短的码值来表示更多的数字,编码的效率就越高
?13、Dropout的原理及作用
原理步骤:
- 1)在开始,随机删除掉隐藏层一半(自定义p)的神经元(只是不参与下一步的权重更新,并没有真正删除)(相当于每次训练不同的网络);
- 2)然后,在删除后的剩下一半的神经元上正向和反向更新权重(变为1/p)和偏向;
- 3)再恢复之前删除的神经元,再重新随机删除一半的神经元,进行正向和反向更新w和b;
- 4)重复上述过程
注:
- 只能在训练中使用,测试和实际使用时不能有 Dropout 操作,只是每个权重参数乘以概率P;
- 数据量小的时候,dropout效果不好,数据量大了,dropout效果好
- dropout如何选择概率:input 的dropout概率推荐是0.8, hidden layer 推荐是0.5
?14、卷积的参数量和计算量如何计算(以及卷积层输出大小计算)?
卷积层输出大小计算:
- 公式:O = (W - F + 2P) / S+1,输入图片(Input)大小为I=W x W,卷积核(Filter)大小为F x F,步长(stride)为S,填充(Padding)的像素数为P;
- 除不尽的结果都向下取整
- SAME填充方式:填充像素。conv2d函数常用
- VALID填充方式:不填充像素,Maxpooling2D函数常用。
1、普通卷积:
参数量:
- 和图像大小无关,是参与计算参数的个数,占用内存空间。
- (Cin (K x K) + 1 ) x Cout:(Cin:输入通道、核大小:K x K、Cout :输出通道)
和输入图像的大小也有关系
Conv所占的比重通常是最大的
错的(Cin x K x K ) x Hout x Wout x Cout:(Cin:输入通道、核大小:K x K、Cout :输出通道、Hout x Wout:输出大小)
FLOPs(floating point operations)(浮点运算量,指计算量):
-
(Cin x 2 x K x K ) x Hout x Wout x Cout:乘2是因为有加法
例如下图:Image大小为 5x5,卷积核大小为 3x3,则:- 那么(1 x 2 x 3 x 3 -1 ) x 3 x3 x 1= 153 (不带偏置,以上公式皆为带偏置)
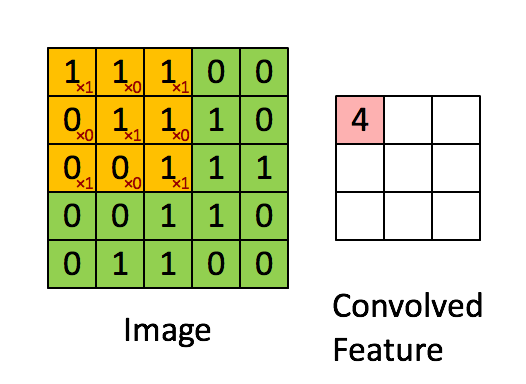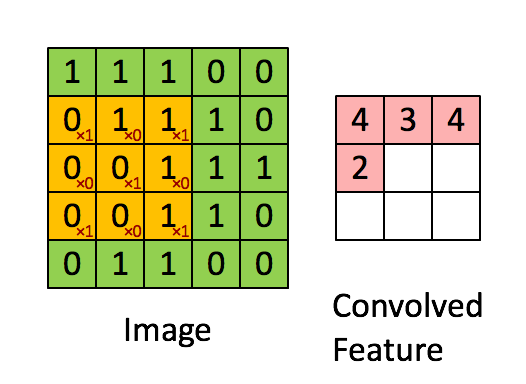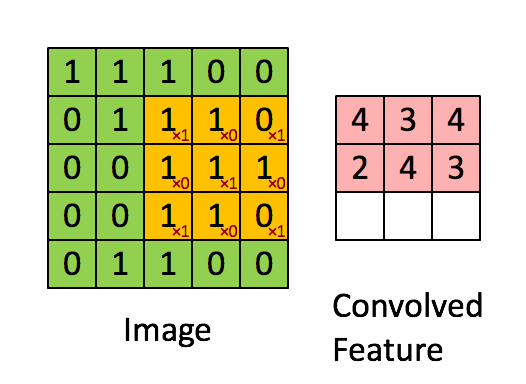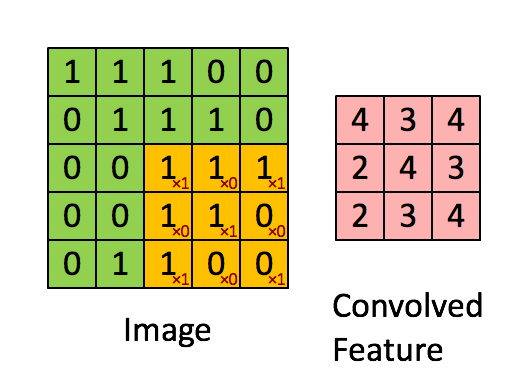
2、可分离卷积:
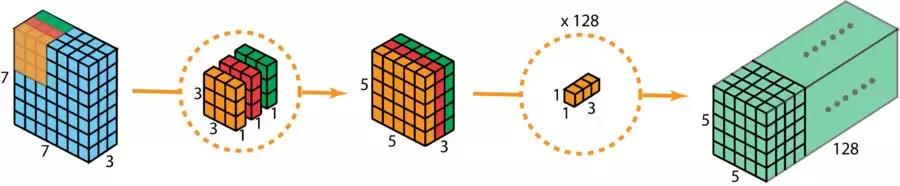

?15、RoIPooling、RoIAlign的原理与区别
RoIPooling:(Faster RCNN中使用)
- 使生成的候选框region proposal映射产生固定大小的feature map;
- 经过两次量化会产生像素偏差(misalignment)(20 x 20 变成 14 x 14 )
RoIAlign:(在Mask RCNN中使用)
- 使生成的候选框region proposal映射产生固定大小的feature map;
- 映射过程中保留浮点数,使用双线性内插的方法获得坐标为浮点数的像素点上的图像数值,然后进行最大池化操作;
- 对检测小物体效果更好
?16、
| 二、训练技巧总结 |
?1、对卡在局部极小值的处理方法:
- 1.调节步伐:调节学习速率,使每一次的更新“步伐”不同;
- 2.优化起点:合理初始化权重(weights initialization);常用方法有:
- 高斯分布初始权重(Gaussiandistribution):满足mean=0,std=1的高斯分布x∼N(mean,std2)
- Xavier 初始权重:满足x∼U(−a,+a)的均匀分布, 其中 a = sqrt(3/n)
- MSRA 初始权重:满足x∼N(0,σ2)的高斯分布,其中σ = sqrt(2/n)
- Uniform 初始权重:满足min=0,max=1的均匀分布,x∼U(min,max)
- He 初始权重:
- 均匀分布初始权重(Uniform distribution):
- Glorot 初始权重:
- 稀疏矩阵初始权重(sparse matrix):
- 3.预训练网络(pre-train),使网络获得一个较好的“起始点”,如最右侧的起始点就比最左侧的起始点要好。
?2、多任务学习中标签缺失如何处理?
- 一般做法是将缺失的标签设置特殊标志,在计算梯度的时候忽略。
?3、梯度消失和梯度爆炸的区别以及解决方法?
出现原因:
- 深度学习基于梯度学习,前面层的梯度是后面层的乘积,随着层数的增加,就会发生梯度消失或者梯度爆炸。
区别:
- 在求导连续乘积后,一个值特别大、一个值特别小;
解决方法:
- 引入Gradient Clipping(梯度裁剪),将梯度约束在一个范围内,这样不会使得梯度过大。
- 预训练模型+微调
- 正则化L1、L2
- ReLu、leakyrelu等激活函数(代替sigmoid)
- BN归一化
- 残差结构
?4、sync BN,multi-scale training/testing,deformable conv,soft-nms???
?5、目标检测不平衡的类型?(类别、尺度、位置、任务损失、类别损失、IoU)【论文原文】
1、类别不平衡:
- 前景和背景的不平衡、前景中不同类别的输入包围框个数不平衡;
2、尺度不平衡:
- 输入图像和包围框的尺度不平衡,不同特征层对最终结果贡献不平衡;
3、空间不平衡:
- 不同样本对回归损失的贡献不同
- 正样本IoU分布不平衡
- 目标在图像中的位置不平衡
4、目标函数不平衡:
- 不同任务(比如回归和分类)对全局损失的贡献不平衡(一般而言分类loss多)
?5、
待续…——2019.8.19















 2905
2905











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









