







数据:链接:https://pan.baidu.com/s/1q1GL16Jix7ErkDBghAjrqg?pwd=o48x
提取码:o48x
介绍
特征介绍:
每个预测的关键点由像素索引空间中的 (x,y) 实值对指定。有 15 个关键点,代表面部的以下元素:
left_eye_center,right_eye_center,left_eye_inner_corner,left_eye_outer_corner,right_eye_inner_corner,right_eye_outer_corner,left_eyebrow_inner_end,left_eyebrow_outer_end,right_eyebrow_inner_end,right_eyebrow_outer_end,nose_tip,mouth_left_corner,mouth_right_corner,mouth_center_top_lip,mouth_center_bottom_lip
这里的左右是指主体的视角。
在一些示例中,一些目标关键点位置丢失(编码为 csv 中的丢失条目,即两个逗号之间没有任何内容)。
输入图像在数据文件的最后一个字段中给出,由像素列表(按行排序)组成,为 (0,255) 中的整数。图像为 96x96 像素。
数据文件:
training.csv: 训练 7049 张图像的列表。每行包含 15 个关键点的 (x,y) 坐标,图像数据为按行排序的像素列表。
test.csv: 1783 个测试图像的列表。每行包含 ImageId 和图像数据作为像素的行排序列表
submitFileFormat.csv : 要预测的 27124 个关键点的列表。每行包含一个 RowId、ImageId、FeatureName、Location。FeatureName 是“left_eye_center_x”、“right_eyebrow_outer_end_y”等。位置是您需要预测的。
评估指标:RMSE
代码
处理数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
import torch.nn as nn # 基本模块
import torch.nn.functional as F #卷积的一些函数
import torch.optim as optim #优化器
import torch.utils.data as data_utils
from torch.utils.data.sampler import SubsetRandomSampler #随机采样
# 解压压缩包的,你也可以自己解压
!unzip ../input/facial-keypoints-detection/test.zip
!unzip ../input/facial-keypoints-detection/training.zip
train_data = pd.read_csv("./training.csv")
test_data = pd.read_csv("./test.csv")
# 转置是为了方便观看。
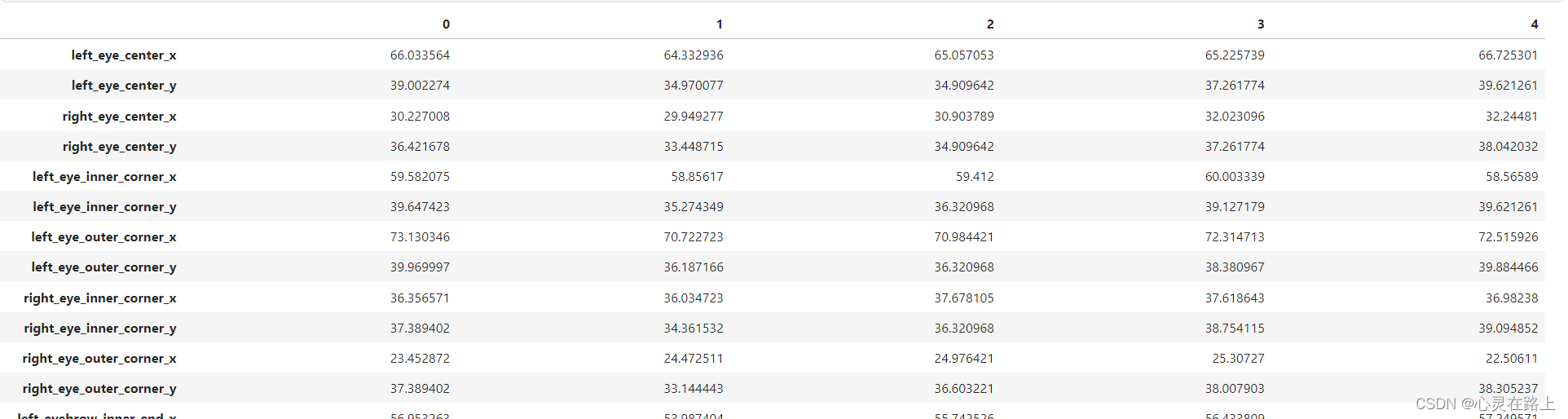
train_data.head().T
# 看一下缺失值
train_data.isna().sum()

# 表示用前一个非缺失值去填充该缺失值
train_data.fillna(method='ffill', inplace=True)
# 通过观察特征信息,了解到最后一列表示的是原图像的像素点。
#这里取出来最后一列 方便后续图形化展示
img_dt = []
for i in range(len(train_data)):
img_dt.append(train_data['Image'][i].split(' '))
X = np.array(img_dt, dtype='float')
# 这里展示下图像,
plt.imshow(X[1].reshape(96,96), cmap='gray')

# 前面的列就是关键点
facial_pts_data = train_data.drop(['Image'], axis=1)
facial_pts = []
for i in range(len(facial_pts_data)):
facial_pts.append(facial_pts_data.iloc[i])
y = np.array(facial_pts, dtype='float')
构建CNN模型
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=4, kernel_size=5) # (b,1,96,96) to (b,4,92,92)
self.conv1_bn = nn.BatchNorm2d(4) #归一化
self.conv2 = nn.Conv2d(in_channels=4, out_channels=64, kernel_size=3) # (b,4,46,46) to (b,64,44,44)
self.conv2_bn = nn.BatchNorm2d(64)
self.conv3 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3) # (b,64,22,22) to (b,128,20,20)
self.conv3_bn = nn.BatchNorm2d(128)
self.conv4 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3) # (b,128,10,10) to (b,256,8,8)
self.conv4_bn = nn.BatchNorm2d(256)
self.fc1 = nn.Linear(256*4*4, 1024)
self.fc2 = nn.Linear(1024, 256)
self.fc3 = nn.Linear(256, 30)
self.dp1 = nn.Dropout(p=0.4)
def forward(self, x, verbose=False):
# 四个层
x = self.conv1_bn(self.conv1(x))
x = F.relu(x)
x = F.max_pool2d(x, kernel_size=2)
x = self.dp1(x)
x = self.conv2_bn(self.conv2(x))
x = F.relu(x)
x = F.max_pool2d(x, kernel_size=2)
x = self.dp1(x)
x = self.conv3_bn(self.conv3(x))
x = F.relu(x)
x = F.max_pool2d(x, kernel_size=2)
x = self.dp1(x)
x = self.conv4_bn(self.conv4(x))
x = F.relu(x)
x = F.max_pool2d(x, kernel_size=2)
# 这里随机丢弃一部分数据,目的是为了尽量避免梯度消失。
#x = self.dp1(x)
x = x.view(-1, 256*4*4)
# 全连接层。
x = self.fc1(x)
x = F.relu(x)
x = self.dp1(x)
x = self.fc2(x)
x = F.relu(x)
x = self.dp1(x)
x = self.fc3(x)
return x
训练和测试
def train_test_split(X, validation_split):
dataset_size = len(X)
indices = list(range(dataset_size))
val_num = int(np.floor(validation_split*dataset_size))
np.random.shuffle(indices)
train_indices, val_indices = indices[val_num:], indices[:val_num]
train_sampler = SubsetRandomSampler(train_indices)
valid_sampler = SubsetRandomSampler(val_indices)
loader_object = data_utils.TensorDataset(torch.from_numpy(X).float(), torch.from_numpy(y).float())
train_loader = data_utils.DataLoader(loader_object, batch_size=32, sampler=train_sampler)
valid_loader = data_utils.DataLoader(loader_object, batch_size=32, sampler=valid_sampler)
return train_loader, valid_loader
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
def training(epochs, model, criterion, device, train_loader, valid_loader, optimizer):
train_error_list = []
val_error_list = []
for epoch in range(epochs):
model.train()
train_loss = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
data = data.view(-1, 96*96)
data = data.view(-1, 1, 96, 96)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
train_loss += loss.item()
loss.backward()
optimizer.step()
train_loss /= len(train_loader.dataset)
eval_loss = testing(model, device, valid_loader)
train_error_list.append(train_loss)
val_error_list.append(eval_loss)
if (epoch+1) % 25 == 0:
print("End of epoch {}: \nTraining error = [{}]\tValidation error = [{}]".format(epoch+1, train_loss, eval_loss))
return train_error_list, val_error_list
def testing(model, device, valid_loader):
model.eval()
test_loss = 0
for data, target in valid_loader:
data, target = data.to(device), target.to(device)
data = data.view(-1, 96*96)
data = data.view(-1, 1, 96, 96)
output = model(data)
loss = criterion(output, target)
test_loss += loss.item()
test_loss /= len(valid_loader.dataset)
return test_loss
n_hidden = 128
output_size = 30
train_loader, valid_loader = train_test_split(X, 0.2)
model = CNN()
model.to(device)
criterion = torch.nn.MSELoss()
optimizer = optim.Adam(model.parameters())
print('Number of parameters: {}'.format(get_n_params(model)))
train_error_list, valid_error_list = training(500, model, criterion, device, train_loader, valid_loader, optimizer)
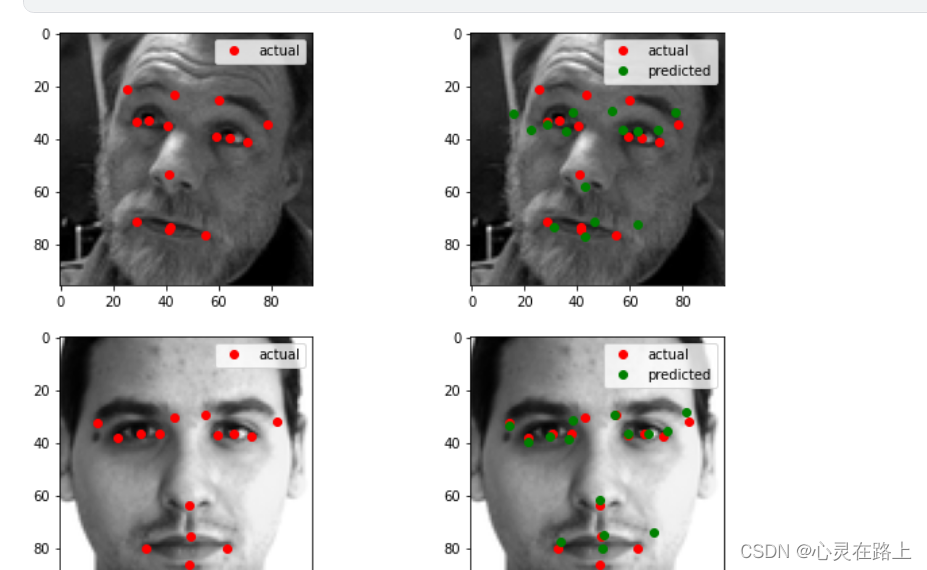
打印出来看看效果
def plot_samples(X, y, model, num_samples):
fig, axes = plt.subplots(nrows=num_samples, ncols=2, figsize=(10,20))
for row in range(num_samples):
sample_idx = np.random.choice(len(X))
x = X[sample_idx]
x = torch.from_numpy(x).float().view(1,1,96,96).to(device)
actual_y = y[sample_idx]
pred_y = model(x)
img = X[sample_idx].reshape(96,96)
actual_y = np.vstack(np.split(actual_y, 15)).T
pred_y = pred_y.cpu().data.numpy()[0]
pred_y = np.vstack(np.split(pred_y, 15)).T
axes[row, 0].imshow(img, cmap='gray')
axes[row, 0].plot(actual_y[0], actual_y[1], 'o', color='red', label='actual')
axes[row, 0].legend()
axes[row, 1].imshow(img, cmap='gray')
axes[row, 1].plot(actual_y[0], actual_y[1], 'o', color='red', label='actual')
axes[row, 1].plot(pred_y[0], pred_y[1], 'o', color='green', label='predicted')
axes[row, 1].legend()
plot_samples(X, y, model, 5)
预测
img_dt = []
for i in range(len(test_data)):
img_dt.append(test_data['Image'][i].split(' '))
test_X = np.array(img_dt, dtype='float')
test_X_torch = torch.from_numpy(test_X).float().view(len(test_X),1,96,96).to(device)
test_predictions = model(test_X_torch)
test_predictions = test_predictions.cpu().data.numpy()
keypts_labels = train_data.columns.tolist()
def plot_samples_test(X, y, num_samples):
fig, axes = plt.subplots(nrows=1, ncols=num_samples, figsize=(20,12))
for row in range(num_samples):
sample_idx = np.random.choice(len(X))
img = X[sample_idx].reshape(96,96)
predicted = y[sample_idx]
predicted = np.vstack(np.split(predicted, 15)).T
# print(img, predicted)
axes[row].imshow(img, cmap='gray')
axes[row].plot(predicted[0], predicted[1], 'o', color='green', label='predicted')
axes[row].legend()
plot_samples_test(test_X, test_predictions, 6)

这绿色看起来是有点吓人哦。















 3293
3293











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









