



 本文详细介绍了一种基于LSTM的IMDb电影评论情感分析方法,包括数据预处理、模型搭建、训练、评估及预测等步骤,展示了如何使用TensorFlow和Keras实现文本情感分类。
本文详细介绍了一种基于LSTM的IMDb电影评论情感分析方法,包括数据预处理、模型搭建、训练、评估及预测等步骤,展示了如何使用TensorFlow和Keras实现文本情感分类。
ImdbLSTM情感分析
1. 导入库、数据准备
from tensorflow.keras.datasets import imdb
from tensorflow.keras.preprocessing import sequence
from tensorflow.keras.preprocessing.text import Tokenizer
import numpy as np
np.random.seed(10)
2. 数据准备
import re
re_tag = re.compile(r'<[^>]+>')
def rm_tags(text):
return re_tag.sub('', text)
import os
def read_files(filetype):
path = "aclImdb/"
file_list=[]
positive_path=path + filetype+"/pos/"
for f in os.listdir(positive_path):
file_list+=[positive_path+f]
negative_path=path + filetype+"/neg/"
for f in os.listdir(negative_path):
file_list+=[negative_path+f]
print('read',filetype, 'files:',len(file_list))
all_labels = ([1] * 12500 + [0] * 12500)
all_texts = []
for fi in file_list:
with open(fi,encoding='utf8') as file_input:
all_texts += [rm_tags(" ".join(file_input.readlines()))]
return all_labels,all_texts
y_train,train_text=read_files("train")

3 建立模型
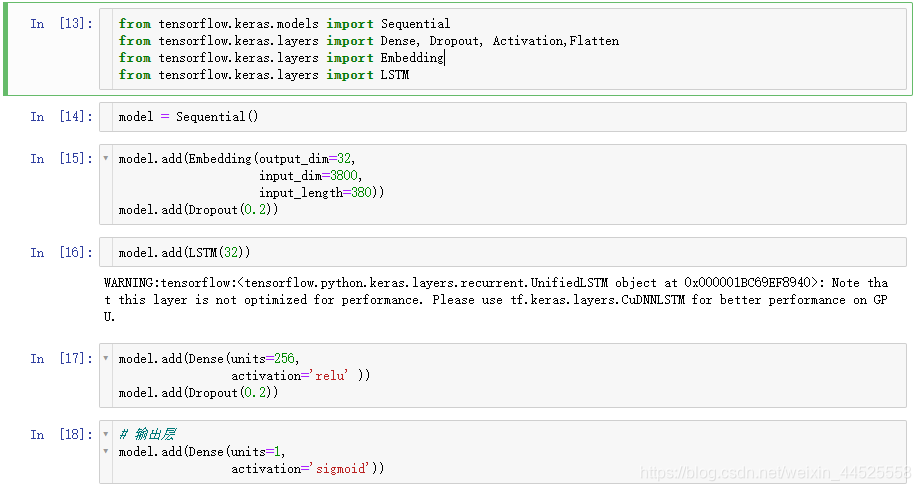
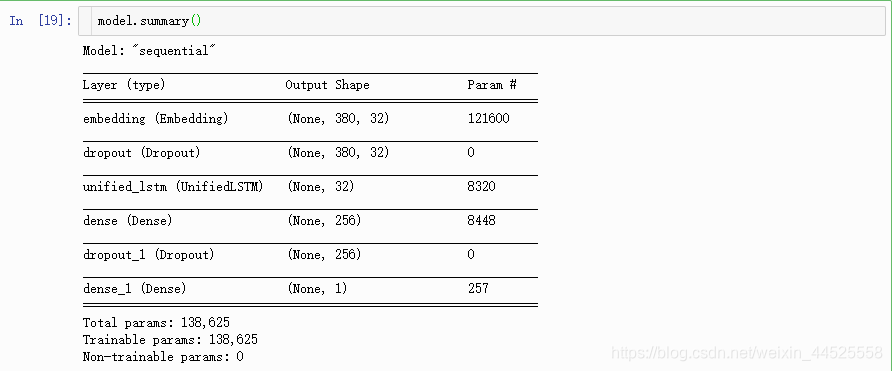
4. 训练模型
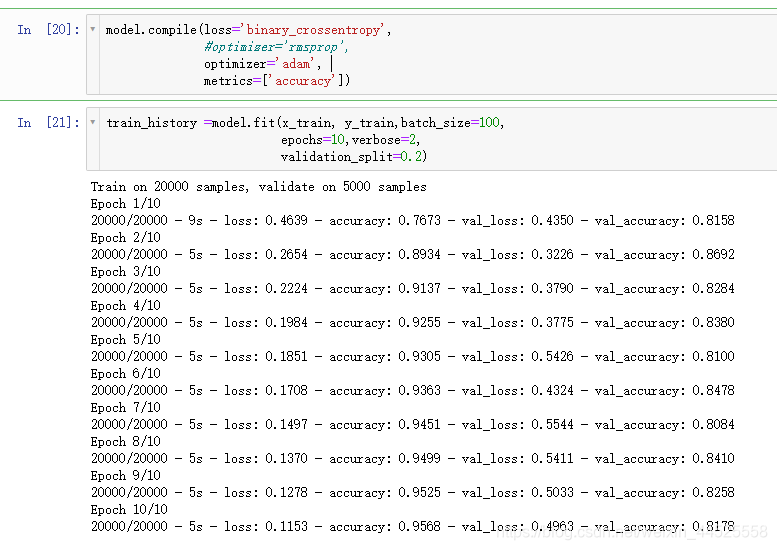
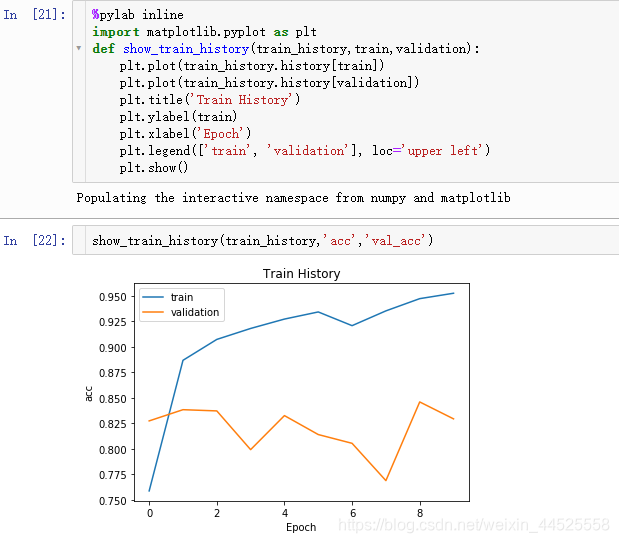
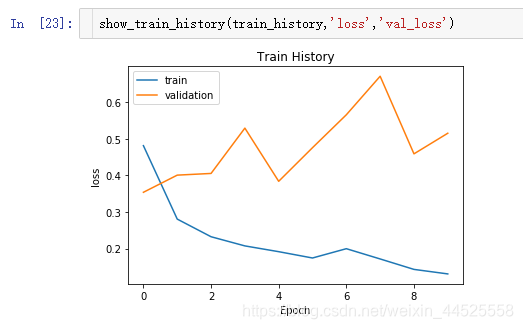
5. 评估模型的准确率
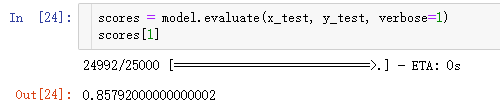
6. 预测概率
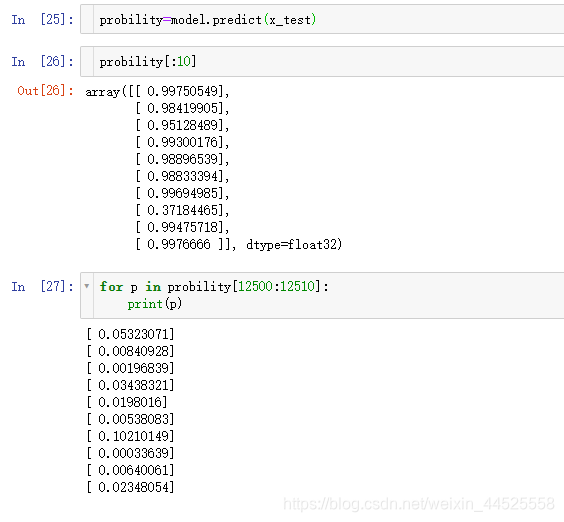
7. 预测结果

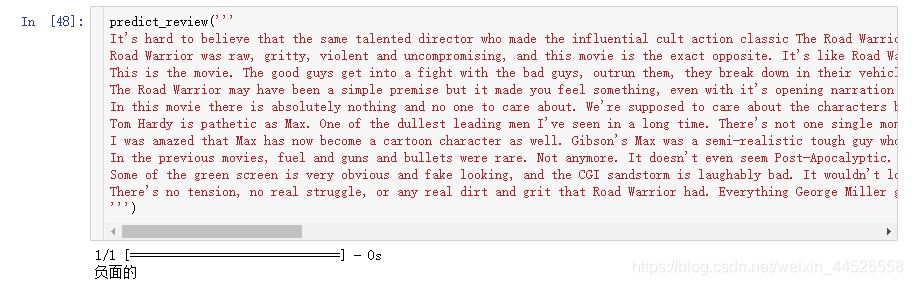
8. 查看预测结果


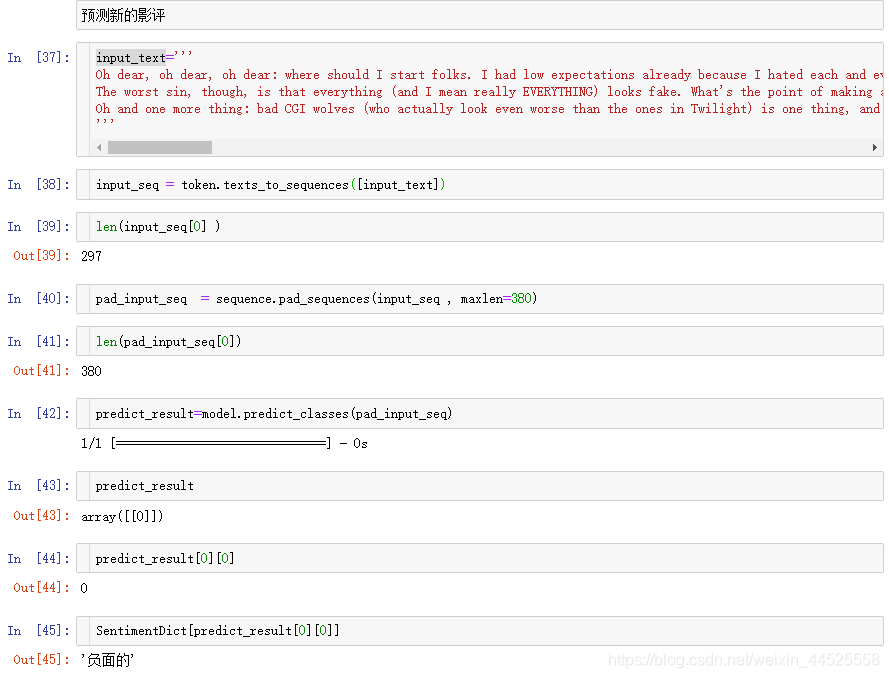

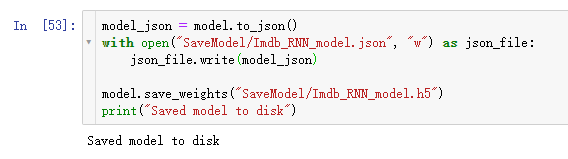
9 serialize model to JSON
保存模型

















 3222
3222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









