









A Survey on the Optimization of LLM Agents
论文链接:https://arxiv.org/abs/2503.12434
项目链接:https://github.com/YoungDubbyDu/LLM-Agent-Optimization
具体的工作部分(每一个小点有哪些模型是怎么做的)文章介绍的很详细了,这里直接精简的介绍下,主要以总结为主(论文在重点地方后面都加了summary)。论文写的还是有点糙,各个章节小节的summary没有凸显出来。 不过agent优化目前没有被整体提出来,虽然有LLM类似工作,但总体总结一下也是好的~
Q: 你们觉得怎么样呢?
摘要
现有LLM agent在很多复杂的agent环境中能力有限,虽然LLM优化技术可以提升常规性能,但难以解决关键agent功能,如长期规划、动态环境交互和复杂决策等。本文对现有使用各种策略来优化LLM AGENT的方法记性总结与回顾。具体分为参数驱动和参数无关的优化方法。重点先介绍了 参数驱动优化,包含基于微调的优化、基于强化学习的优化和混合策略优化。重点包含轨迹数据构建、微调技术、奖励函数设计等。此外也讨论了使用提示工程和外部知识检索的无参数优化方法。最后总结了用于评估和调整的数据集和基准,回顾了Agent的主要应用,并讨论了主要挑战和未来的发展方向。相关参考资料库可在https://github.com/YoungDubbyDu/LLM-Agent-Optimization上获得。
1. 引言
基于LLM的agent和传统的基于规则与强化学习agent是不同的,由于LLM为基座已经具备了强大的通用能力和理解能力,可以使用基于文本的指令执行交互。
存在问题:LLM不是天生用于agent任务的,而是token预测的,因此缺乏以agent为中心的训练,挑战包括:
- 长期规划和多步推理困难,可能错误累计 任务不一致
- 记忆有限难以利用过去的经验反思
- 对新环境适应性有限,难以处理动态环境
- 闭源LLM成本太高
因此,需要agent的优化技术,分为参数驱动优化和参数无关优化。前者包含微调方式(轨迹构建——agent微调)和强化学习优化(传统RL技术和DPO),后者包含基于反馈、经验、工具、RAG、多智能体协作的方式。
与其他综述区别: 现有综述主要是LLM优化 或者 agent的特定能力上,例如记忆、规划、角色扮演等。缺乏对LLM agent整体的优化综述。
整体章节介绍如下:重点在第三章
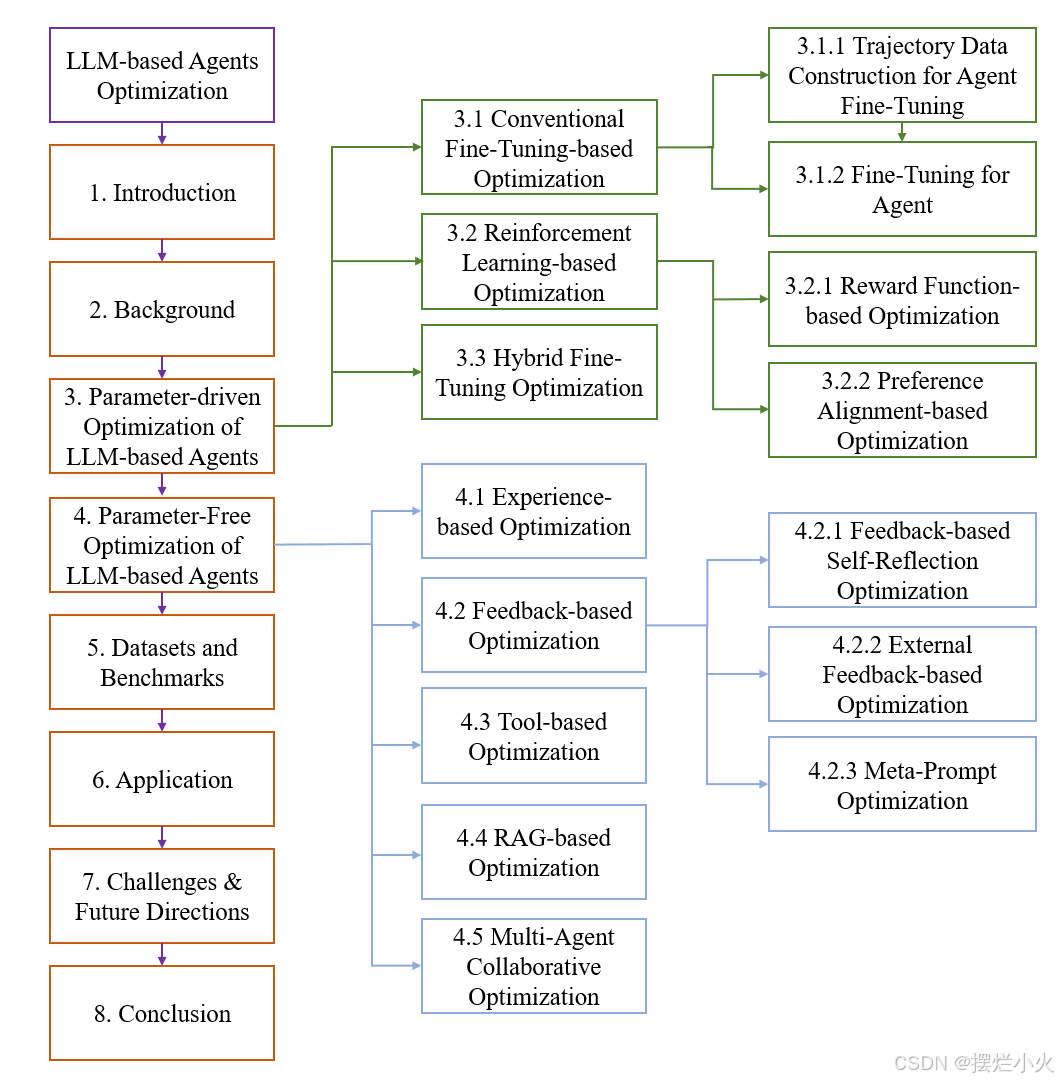
3. 参数驱动的LLM优化
3.1 基于常规微调的优化
分为两个步骤:构建agent任务的高质量轨迹数据——用轨迹微调agent
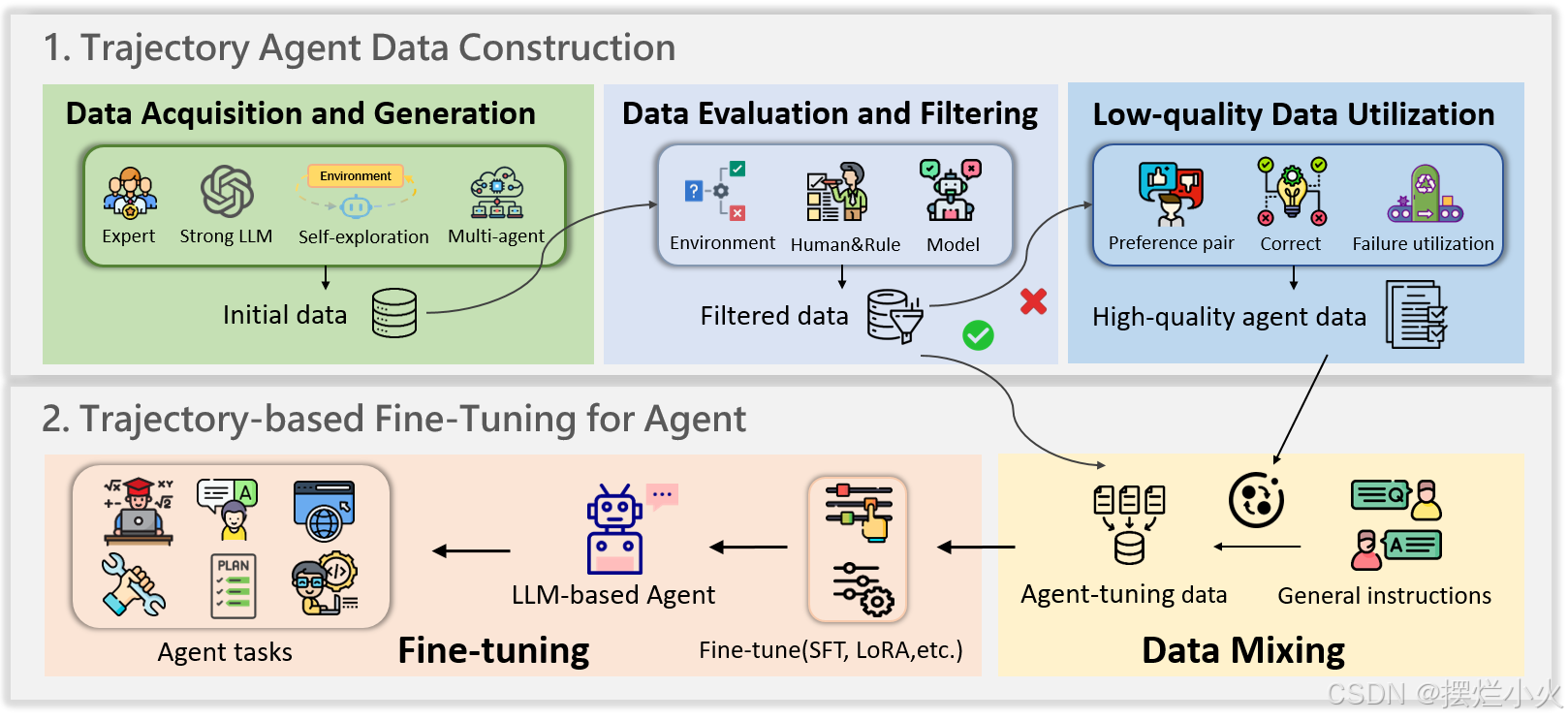
3.1.1 轨迹数据构建
数据构建与生成
具体的方式有4类:
1. 基于专家标注数据:是人类专家手动制作的高质量数据集,黄金标准。大多工作用ReAct风格的专家轨迹作为初始数据集。IPR、ETO、AGILE都使用CoT或ReAct这类方法模仿学习专家轨迹。StepAgent [29]引入了一个两阶段的学习过程,在这个过程中,代理首先观察他们的策略和专家轨迹之间的差异,然后迭代地改进他们的动作。AgentOhana [202]将异构代理专家轨迹转换为统一格式,以提高数据一致性。
2. 强LLM生成的轨迹: 由类似GPT4在环境中交互生出的轨迹。AgentTuning [199]和FireAct [14]采用ReAct和CoT来指导代理行为,同时结合Reflexion [139]改进,提高了生成数据的多样性。NAT [158]在不同的温度设置下生成多个轨迹,使用ReAct提示并在交互期间集成计算器和API等工具。Agent Lumos [192]利用GPT-4和GPT-4V来注释规划和接地模块中的数据集,生成LUMOS-I和LUMOS-O风格的数据。[216]使用GPT-4来模拟问题生成器,行动规划器和环境代理,从而实现迭代交互驱动的数据生成。
3. 自我探索环境交互轨迹: 要训练的actor agent自行与环境生成初始轨迹。SWIFTSAGE [94]利用较长的轨迹历史表示来选择性地对动作进行采样并构建简洁的训练数据集。ENVISION允许agent通过自我纠正和自我奖励机制探索和完善他们的轨迹。STE [154]模拟工具使用和API交互,将反馈和经验存储为记忆,以增强轨迹学习。其他方法侧重于利用额外的模型进行反思和纠正。NLRL [40]通过使用自然语言来表示RL优化过程(例如文本风格的策略,值函数和反馈)引入了一个创新的视角,使代理能够与环境交互并通过RL视图生成轨迹数据。
4. 多智能体交互协作构建: 用多智能体框架扮演不同角色构建轨迹数据。SMART [197]中,智能体依次扮演意图重建器,知识检索器,事实定位器和响应生成器的角色,协作产生全面的答案并构建包含短期和长期交互的轨迹数据集。COEVOL [85]采用两阶段辩论机制来生成初始数据,并由代理人作为顾问,编辑和判断来评估和完善它们,以确保高质量的输出。Self-Talk [153]使LLM能够模拟不同角色之间的对话,生成反映多个视角的训练数据。ATM [219]结合了对抗性交互,攻击者干扰了RAG检索的信息,而生成器产生了对这些干扰具有鲁棒性的响应。
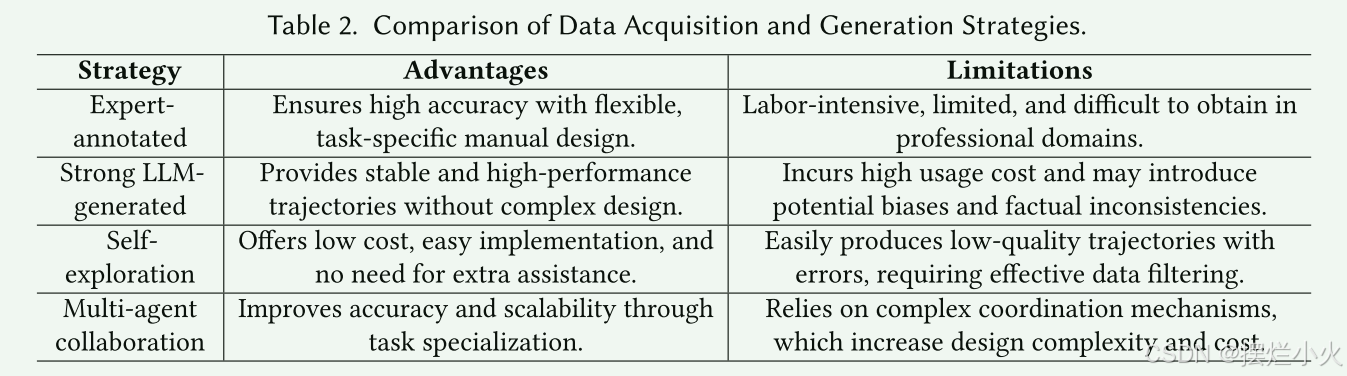
总结: 专家数据好,但是难以获取且标注成本劳动密集;强LLM生成的轨迹可扩展,效果也不错,但API贵 本地部署也消耗资源;自我探索方法 便宜且直接,但是数据效果很差,因为能力很垃圾不稳定;多智能体生成的数据多样性,但结构复杂 成本也相对比较高。因此进行下一步的初始数据过滤
数据过滤与评估
总结为3个方式,具体工作就不一一细讲了(大家可以移步文献 看每个工作是怎么应用的),直接上总结部分
- 基于环境: 来自环境的外部反馈来评估生成的轨迹的质量和成功。一般工作都采用二元反馈成功/失败作为反馈。 定义明确,但缺乏过程反馈(可能中间推理错 答案对)。
- 基于人类/规则: 预定义标准和人类自定义规则。对不同任务设置不同标准(如PPL 手动筛选),可靠可解释,但依赖人类和规则设计。
- 基于模型: 自动化流程无监督,但模型本身存在内在偏差。
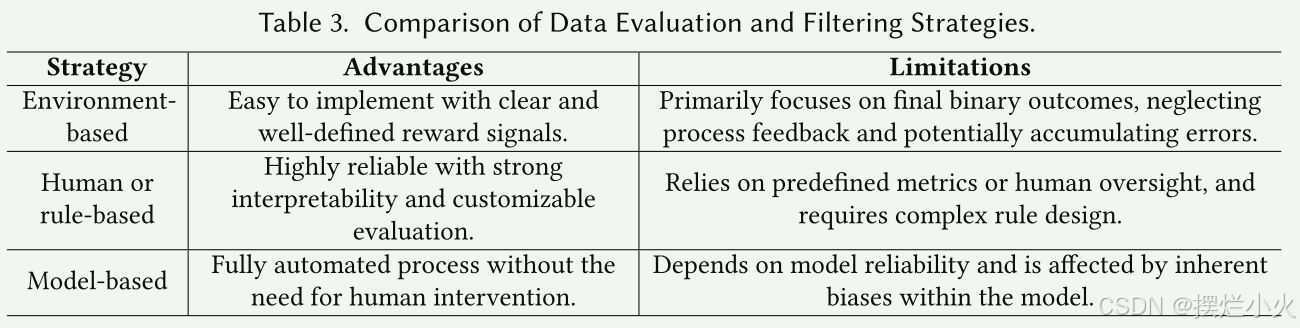
除了高质量的获取,对不合格的低质量轨迹也需要再次利用
- 偏好对比,让模型区分好与坏;
- 基于校正:让模型对不佳的结果进行校正后作为好轨迹;
- 直接利用:让模型识别和学习故障的场景。
3.1.2 agent轨迹微调
微调之前需要先将高质量的agent数据和通用指令的常规微调数据进行混合,保持LLM的基本性能。微调技术这里分3类:
- 标准SFT:包括全参数微调 行为克隆 ,就是经典的SFT
- 参数有效PEFT:使用lora和Qlora
- 自定义微调:特定的策略和目标函数,例如MITO多智能体迭代优化。
所有方法如表:
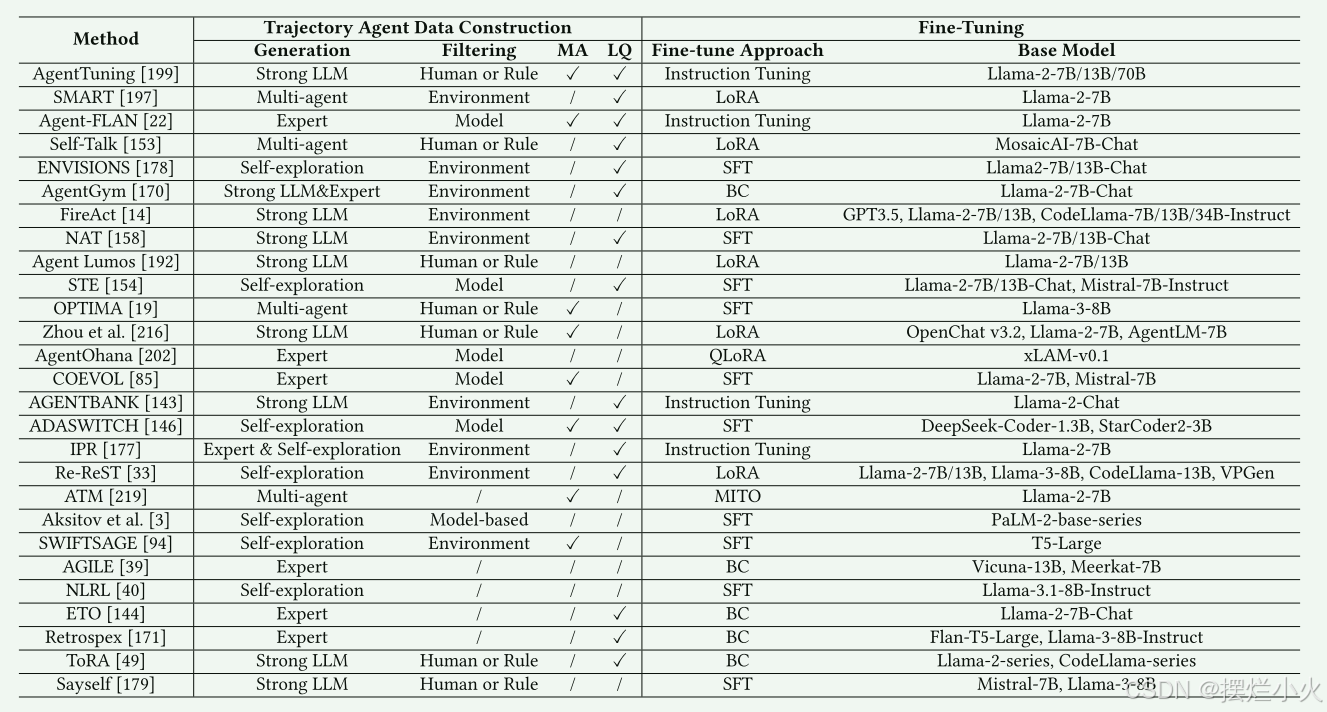
整章总结: 传统的基于微调的优化通过利用高质量的轨迹数据、不同的训练方法和有效的参数调整来有效地增强基于LLM的代理。这种方法确保了强大的任务对齐,受控优化和对特定目标的适应性,使其成为改进代理行为的可靠方法。然而,它也面临着影响其有效性和适应性的固有局限性。这些方法严重依赖于高质量的轨迹数据,使性能取决于数据的可用性和管理。错误积累、过度拟合特定数据集以及难以适应动态环境等挑战可能会阻碍跨不同任务的泛化。此外,微调主要将模型与静态目标对齐,缺乏交互式反馈机制,限制了代理基于实时任务执行来改进其行为的能力。
3.2 基于强化学习的优化
分为基于传统奖励函数和偏好对齐的优化
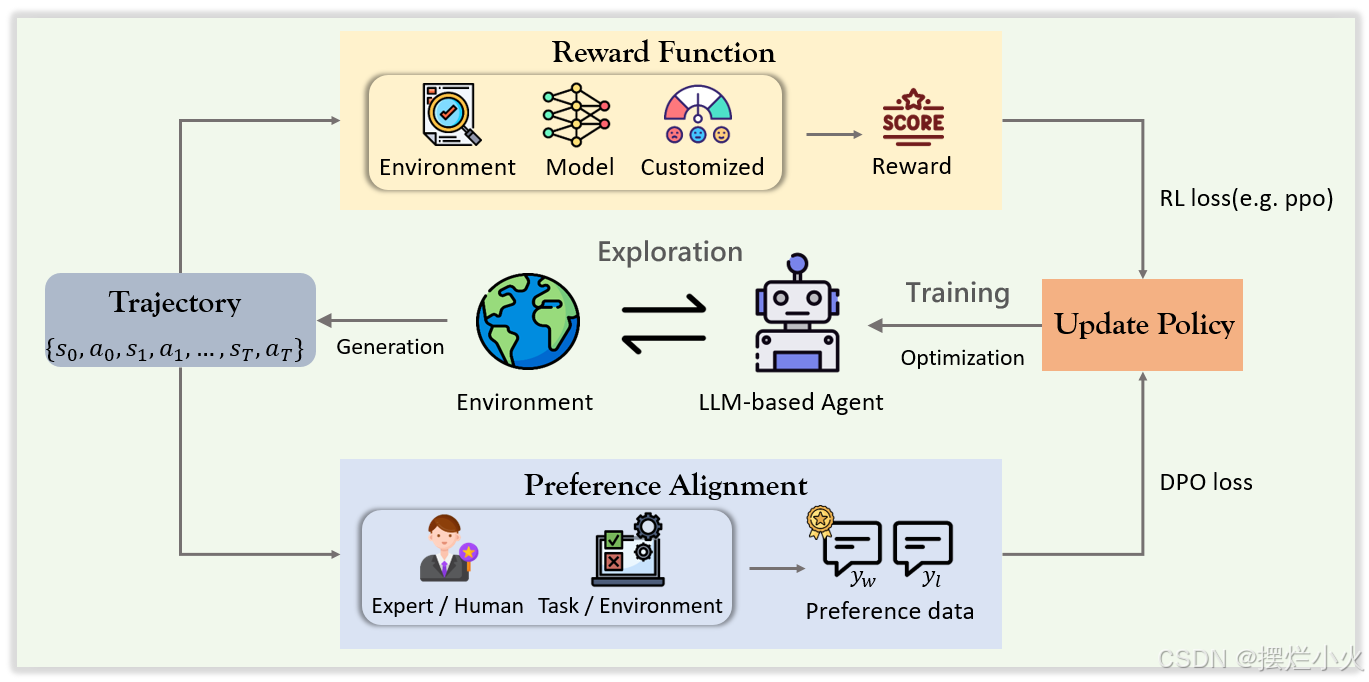
3.2.1 基于奖励函数的优化
使用传统RL范式,奖励模型进行评估之后,采用PPO或AC等方法优化策略
奖励函数的构建主要三个来源:
- 基于环境的奖励:环境和任务反馈当奖励,然而奖励往往离散
- 基于模型的奖励:利用LLM或训练critic模型,但依赖模型的鲁棒性
- 自定义奖励:定制的奖励信号,包括全局、局部、置信度估计等
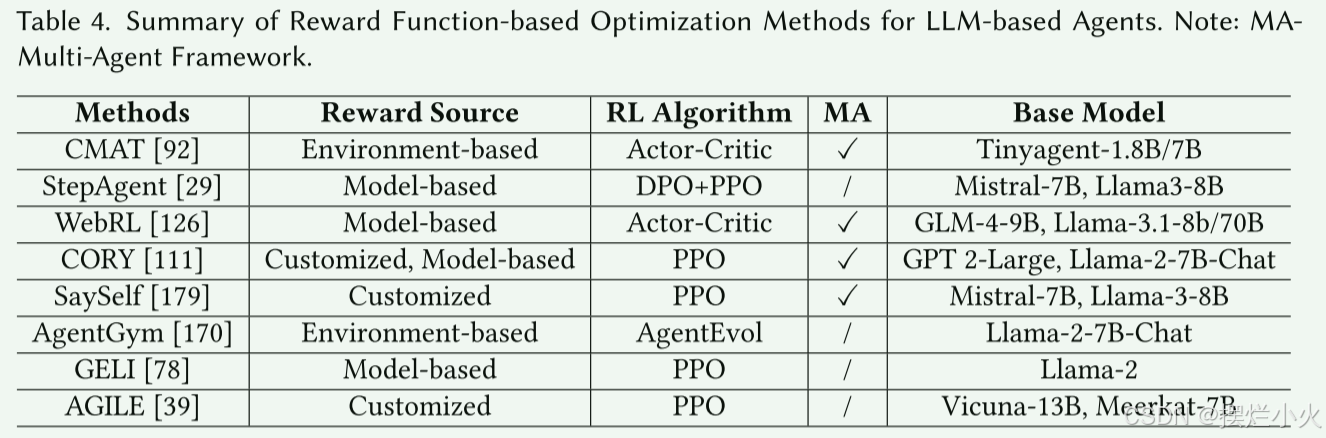
小结: 这类方法使用显式奖励信号迭代改进agent行为,不过设计适当的奖励函数需要仔细考虑目标任务。此外,计算和成本比较复杂。
3.2.2 基于偏好对齐的优化
这里类似于微调方法部分里的,数据过滤与评估
主要是依赖DPO的一些方法,主要流程为偏好数据构建和DPO优化,省略了传统强化学习中显式奖励的构建,而使用偏好对齐来隐式构建。
- 基于专家和人类的偏好优化:通过是人类或者专家来标注偏好数据,定义好的和失败的轨迹。这里效果很好,但是又限制性难以扩展。
- 基于任务和环境的偏好优化:采用环境和任务奖励来区分偏好数据。
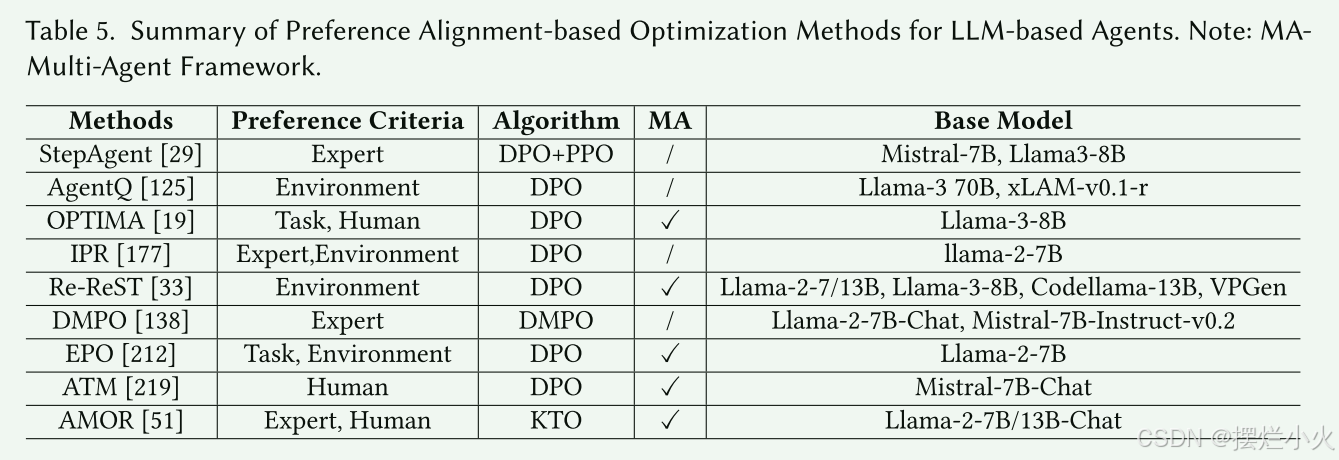
小结: 这类DPO方法简化了训练,并使输出与人类偏好对齐,但严重依赖于偏好数据的质量和覆盖率,限制了高度动态任务的适应性。
3.3 混合参数微调方法
综合SFT和强化学习优化的优势。前者稳定但动态决策一般,后者适合复杂探索,但计算复杂。
- 大部分方法遵循顺序方式。在热身阶段使用 基于行为克隆的SFT,为LLM agent提供基础能力。之后在RL阶段里用PPO、DPO针对特定目标/环境进行agent优化。例如openai的RFT强化微调概念。相关工作包括ReFT [152],AgentGym [170],ETO [144],Re-ReST [33],AGILE [39]和AMOR [51]都在预热阶段利用SFT来训练专家轨迹或策展数据集上的模型。
- 另外的部分方法用迭代方法来改进混合微调范式,在SFT和RL阶段之间交替以提高性能。OPTIMA [19]通过结合迭代SFT和迭代DPO来简化这一点,使LLM代理能够通过SFT从最佳轨迹中学习,同时基于比较偏好使用DPO来改进其理解。类似地,IPR [177]结合了步骤级奖励,从SFT的ReAct式专家轨迹开始,并通过Outcome-DPO和Step-DPO损失迭代完善策略。这些迭代周期通过解决全局和细粒度的改进来确保与任务目标的持续一致。
- 特定机制的混合微调:Retrospex [171]从高质量专家轨迹的SFT开始;后训练阶段,它通过IQlearning训练动作值函数来集成离线RL,允许模型通过RL Critic将固定经验数据与LLM输出相结合,以进行加权评分,从而在动态环境中优化决策。[178]使用SFT来优化自我探索衍生的解决方案,根据任务成功指标从候选池中选择正对和负对。为了简化传统的强化学习,它将强化学习替换为无RL损失,并结合基于MLE的微调损失进行最终优化。
总结: 结合了SFT和RL的优势,平衡结构化指导与自适应优化,拥有更高的灵活性,不过也会面临SFT和RL的相关挑战。但这类方法应该逐渐成为未来创新的重要方向。

















 1600
1600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









