






精准率 召回率简单解释
P R定义
P代表precision(精准率),R代表recall(召回率)
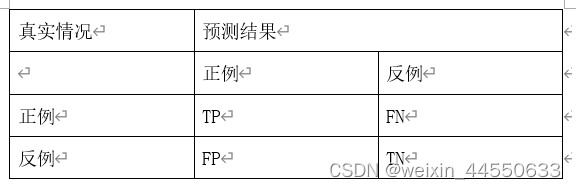
其中,把正例正确地分类为正例,表示为TP(true positive),把正例错误地分类为负例,表示为FN(false negative)。把负例正确地分类为负例,表示为TN(true negative), 把负例错误地分类为正例,表示为FP(false positive)。
precision = TP/(TP + FP)
recall = TP/(TP +FN)
P R的实际含义
精准率(precision)的实际含义是,在所有预测为正例的样本中,真实为正例的比例。
召回率(recall)的实际含义是,在所有真实为正例的样本中,被正确预测为正例的比例。
举个例子,假设有一个垃圾邮件分类器,它要从100封邮件中识别出垃圾邮件。假设其中有20封是真正的垃圾邮件,80封是正常邮件。如果分类器预测出了15封垃圾邮件,其中10封是真的垃圾邮件,5封是误判的正常邮件,那么它的召回率和精准率分别是:
精准率 = 10 / 15 = 0.67,表示分类器预测出的垃圾邮件中有三分之二是真的垃圾邮件。
召回率 = 10 / 20 = 0.5,表示分类器只能找到一半的真正垃圾邮件。
阈值
PR曲线中的阈值是指用来判断样本是否为正例的预测概率的界限。
例如,如果我们有一个分类器,它给每个样本输出一个 [0,1]之间的预测概率,我们可以设置一个阈值,比如0.5,那么大于等于0.5的样本就被认为是正例,小于0.5的样本就被认为是负例。
不同的阈值会导致不同的精确率和召回率,因此我们可以通过改变阈值来绘制PR曲线。
阈值越高,精准率越高,召回率越低;阈值越低,精准率越低,召回率越高。
PR曲线反映了分类器在不同精准率和召回率之间的权衡,通常来说,PR曲线越靠近右上角,表示分类器的效果越好。
阈值越高,精准率越高,召回率越低;阈值越低,精准率越低,召回率越高
这是因为阈值的高低会影响正例的数量和质量。
当阈值越高时,只有预测概率很高的样本才会被判断为正例,这样可以提高正例的质量,也就是说预测为正例的样本中实际为正例的比例会增加,这就是精准率。
但是,阈值越高,也意味着很多实际为正例的样本可能被错判为负例,因为它们的预测概率没有达到阈值,这样就会降低正例的数量,也就是说实际为正例的样本中被预测为正例的比例会减少,这就是召回率。
反之,当阈值越低时,只要预测概率不为零的样本都会被判断为正例,这样可以提高正例的数量,也就是说实际为正例的样本中被预测为正例的比例会增加,这就是召回率。
但是,阈值越低,也意味着很多实际为负例的样本可能被错判为正例,因为它们的预测概率也不为零,这样就会降低正例的质量,也就是说预测为正例的样本中实际为正例的比例会减少,这就是精准率。
所以,阈值越高,精准率越高,召回率越低;阈值越低,精准率越低,召回率越高。
参考 https://blog.csdn.net/guzhao9901/article/details/107961184















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









