










原文链接:https://ojs.aaai.org/index.php/AAAI/article/download/4552/4430
文章提出了 Consensus Adversarial Domain Adaptation (CADA), a novel unsupervised ADA scheme that gives freedom to both target encoder and source encoder.
Objective
To improve the generalization capability of a classifier across domains without collecting
labeled data in the target domain via ADA (与FADA不同,此处并无target samples)
CADA Methodology

Suppose samples
with labels
are collected in the source domain with
possible classes, 与FADA类似,训练可以分为4 steps
1) 利用source domain 数据训练 source encoder and a source classifier
2) Given unlabeled data in target domain , train a target encoder
and fine-tune the source encoder
, such that a discriminator
cannot tell whether a sample is from the source domain or from the target domain after the associated feature mapping (
vs
).
值得注意的是, 和
的参数都是基于step 1训练完的
初始化, 与之前的ADDA,DIFA等model不同,source encoder
的参数在这一轮训练中并非固定。 在之前的model中, 由于
参数的固定,feature mapping is defined by the source encoder and ADA essentially tries to align the feature embeddings of the target domain with the source domain, 在这种情况下,the obtained source encoder is used as an absolute reference, which may deteriorate the DA performance because the alignment could be sub-optimal when the target samples cannot be completely embedded into the imposed representation space. 如果让
的参数拥有更大的自由度,那么就有可能获得更好的域泛化能力。
3) When the in Step 2 is not able to identify the domain label of target samples & source samples, it is an indication that the
and
achieved consensus by mapping the corresponding input data to a shared domain-invariant feature space. Then we fix the paras of the
and train a shared classifier
using the labeled source domain data
。
可以直接用于target domain的分类,因为在step 2 中我们已经使得
and
embed the samples to the domain-invariant feature space。
4) 对于target domain的testing, 我们利用step 2训练好的 将 target test samples 映射到 domain-invariant feature space上,然后利用 shared classifier
进行target domain的分类。
综合上述训练过程,总loss function如下

F-CADA Methodology
F-CADA 和CADA大致相同,除了step3 :
Suppose few labeled samples are available in the target domain. As the most vital step in F-CADA, we design a label learning algorithm to assign presumptive labels
to target unlabeled samples
. Then, we finetune the target encoder obtained in Step 2 and build up a target classifier
using both unlabeled target samples with presumptive labels
and labeled target samples
Evaluations
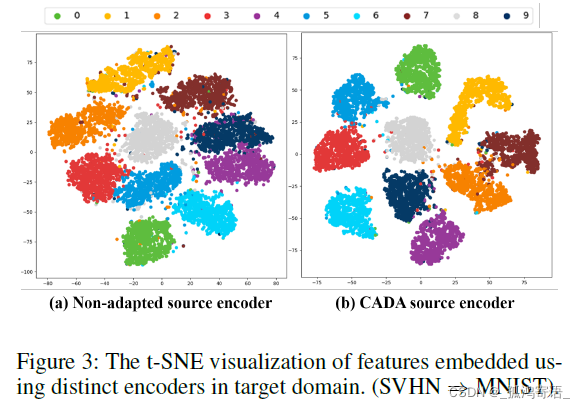
CADA and F-CADA 的evaluation依旧是基于常见的 digit recognition tasks: validates to the task of digit recognition across domains on standard digit adaptation dataset (MNIST, USPS, and SVHN digits datasets) ; 此外还有在 WiFi dataset上的 gesture recognition tasks: the task of spatial adaptation for WiFi-enabled device-free gesture recognition (GR)















 1580
1580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









