









原文链接:chrome-extension://oemmndcbldboiebfnladdacbdfmadadm/https://arxiv.org/pdf/1802.08735.pdf
Motivation
domain adversarial adaptation最常见的方法是找一个公共特征空间,将源域和目标域数据都映射过去,在该空间进行分布对齐。最近很流行的方法是利用域对抗训练,也就是设置一个判别网络,判断特征数据来自于源域还是目标域,特征提取器通过与判别器的对抗实现特征空间的对齐。当前的domain adversarial training 有以下两个limitaions:
- 特征提取函数如果能力太强的话,特征分布对齐就是一个比较弱的约束。
- 在非保守的领域自适应(也就是没有一个分类器可以同时在源域和目标域中分类的很好),训练模型在源域上执行的太好会损害在目标域上的性能。
本文考虑一个正交假设(orthogonal assumption)即簇假设(cluster assumption):输入分布包含分离的数据簇,相同label的数据会形成一个簇,不同label的数据会属于不同的簇。这样的话,决策边界就不能穿过数据高密度的区域,因为一旦穿过,就意味着将相同label的数据分成了不同类。
作者提出两个相关模型分别解决以上两个问题:
- 虚拟对抗领域自适应模型(VADA),结合领域对抗自适应和一个惩罚项,将决策边界推离数据密度高的地方(penalty term that punishes violation of the cluster assumption)。
- 拥有教师的决策边界迭代细化训练模型(DIRT-T),让分类更专注于目标域。
在保守领域自适应中,VADA就可以工作的很好;在非保守领域自适应中,DIRT-T会帮助VADA工作。
Limitations of DAA
领域对抗训练认为,只要分类器在源域上的泛化误差和特征的JS散度足够小,那么就认为领域自适应效果比较好。但是如果特征提取函数 f 能力太强,并且源域和目标域的数据簇是分离的,那么并不能保证分类器在目标域上的准确率。详细分析见另一篇博客:
Virtual Adversarial Domain Adaptation (VADA)

本文考虑领域自适应的簇假设,即相同类别的数据,会形成一个簇。如果这个假设成立,那么决策边界就应该远离那些数据密集的区域。本文通过最小化条件熵来完成这个任务:
![]()
直觉上看,最小化条件熵就是让分类器对目标域数据的标注结果尽量自信,驱使分类器决策边界远离目标域数据。但是,对于分类器 h 如果不是局部Lipschitz的,那么分类器可以在训练数据的邻域内任意改变预测,会导致:1)条件熵的经验估计不可靠。2)即使经验条件熵被最小化了,决策边界也可能靠近训练数据。所以作者加了一个局部Lipschitz的约束对 h 的能力进行限制:
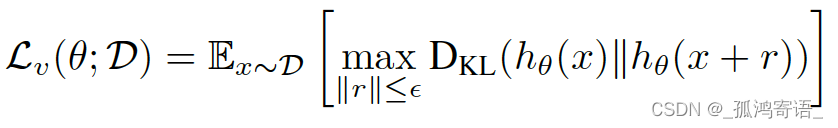
最终我们的特征提取函数 f 优化目标是:
![]()
这个过程称为Virtual Adversarial Domain Adaptation (VADA) model
Decision-boundary Iterative Refinement Training with a Teacher (DIRT-T)

在非保守的领域自适应中,我们假设有下面的不等式:
![]()
其中, ϵs,ϵt 是源域和目标域的泛化误差。这意味着给定一个假设类 H ,最优分类器在源域和目标域上并不一致。文章假设这种情况是因为源域的最佳分类器在目标域上违背了簇假设的约束,也就是穿过了目标域数据密集的区域。
所以作者的解决方法是,先用VADA预训练一个模型,得到一个初始分类器 hθ0 。然后,将目标函数变为 ![]() ,单独进行优化,将决策边界推离目标域数据密度高的区域。这个训练过程称为DIRT。
,单独进行优化,将决策边界推离目标域数据密度高的区域。这个训练过程称为DIRT。
Reference















 1000
1000











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









