









原文链接:https://arxiv.org/abs/2007.09222
Motivation
1. 语义分割领域的数据标注通常难以获取。由于数据标注需要大量的时间人力,因此在训练时所使用的训练数据往往难以完美匹配测试时的要求。
作者提出了两种场景,分别为跨城市迁移和真实合成样本迁移。
- 跨城市迁移:由于不同城市数据因为建筑风格等一系列差异,在用A城市数据训练出的模型,在B城市做测试时可能很难达到理想的效果。
- 真实合成样本迁移:由于数据标注困难,因此有研究者提出使用计算机合成数据进行训练。如图下图左上角为GTA5游戏的图像。游戏图像是由计算机建模形成,因此很容易获取其标注数据,并且理论上游戏图像数据量是无限的。但同样将合成数据应用到现实真实数据中,效果通常不令人满意。
2. 对于大多数传统方法而言,特征对齐仅仅是在全局上的对齐(perform the alignment from a holistic view),无法保证其在类别上也对齐 (ignoring the underlying class-level data structure in the target domain) 。
此文尝试在辨别器中加入类别信息(incorporate class information into the discriminator),使辨别器的输出不再是单纯的域类别,而是既包含域类别,又包含类别信息( align features at a fine-grained level)。
Methodology
Revisit Traditional Feature Alignment

如图所示,特征对齐的目标是两点:
- 红色(target domain)和蓝色(source domain)尽可能靠近。
- 虚线(classifier)能够将加减号(样本类别)划分开。
由于传统的辨别器只是分辨特征是来自source domain还是target domain,因此带来的问题就如图所示。
虽然红色(target domain)和蓝色(source domain)靠近,但仅仅只全局上的靠近,分类器(虚线)很难将样本类别(加减号)分离。
Fine-grained Adversarial Learning

该网络与传统的对抗方法相比最大的差异在辨别器,传统的辨别器输出两通道的特征,分别代表source domain和target domain。而FADA网络,它在此处输出2K个通道,K为样本类别数。因此在对特征生成器监督的过程中附加了类别信息,使特征类别也具有对齐的趋势。
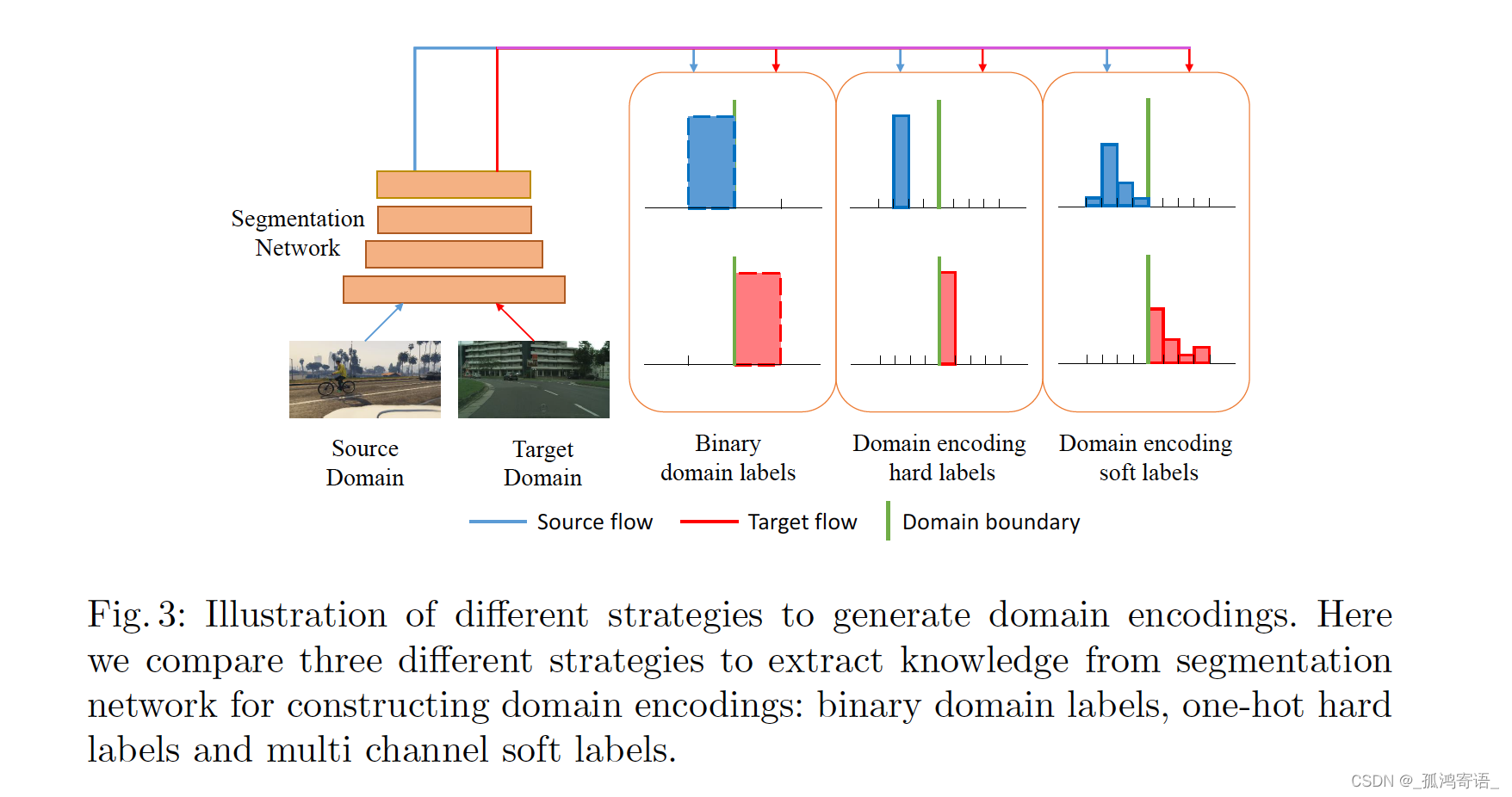
传统GAN binary discriminator 输出的domain labels是 [1; 0] 和 [0; 1], 此文输出的domain encodings 用 [a; 0] 和 [0; a] 表示, 其中a是一个K-dimensional vector















 2786
2786











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









