






4.目标检测与YOLO
4.1目标检测要做什么
4.1.1目标检测问题
目标检测是在给定的图片中精确找到物体所在位置,并标注出物体的类别。物体的尺寸变化范围很大,摆放物体的角度,姿态不定,而且可以出现在图片的任何地方,并且物体还可以是多个类别。
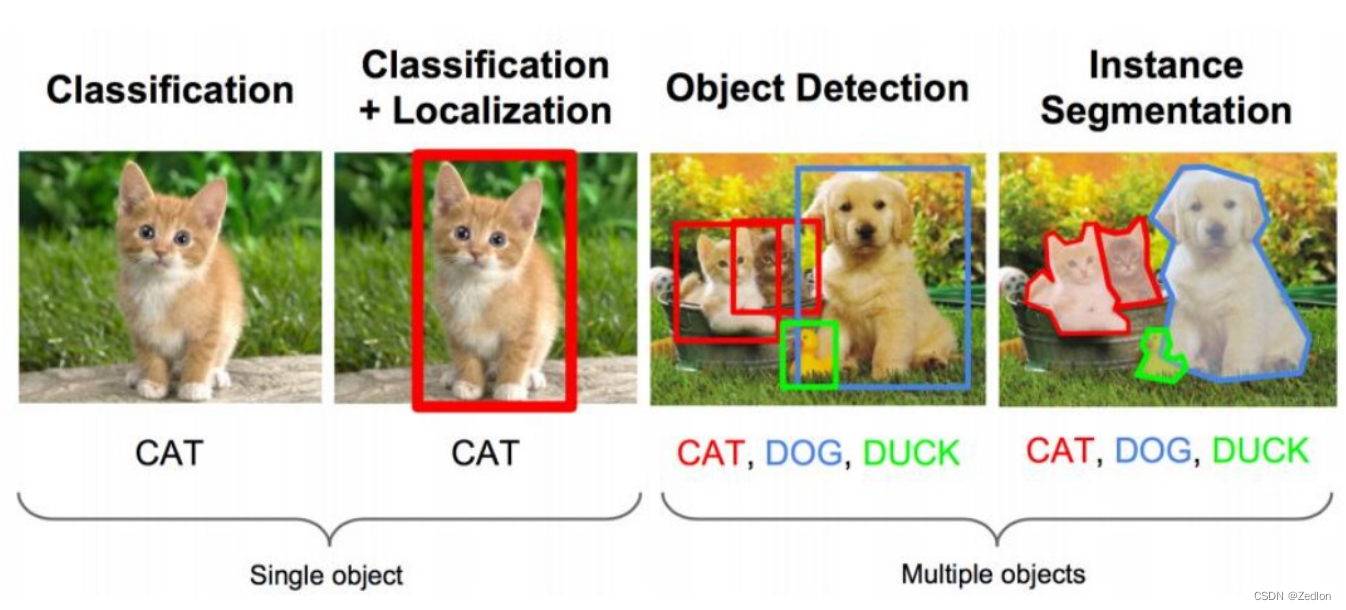
4.1.2分类问题与目标检测
分类问题:是否有目标
检测问题:有什么目标
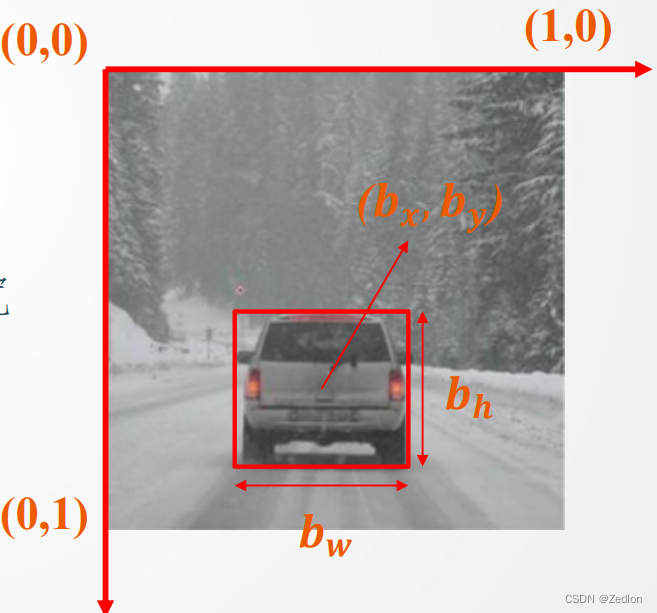
定位:定位方式1——对角线顶点坐标 1/对角线顶点坐标2
定位方式2———中心点坐标/长/宽
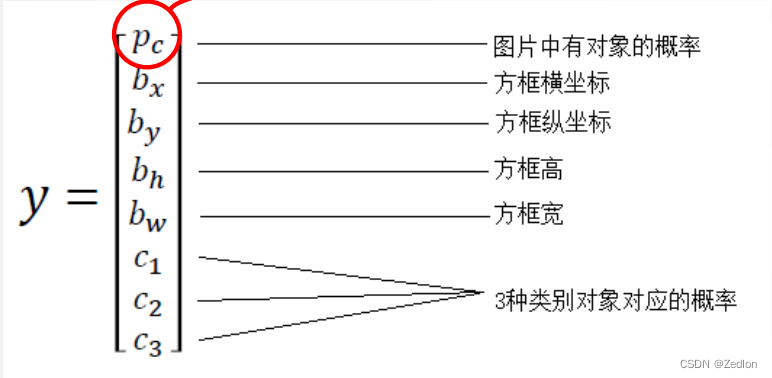
数据集输出表达:
Pc = 1 :图片中有目标 Pc = 0 :图片中无目标
目标检测实例:实际图像中有多个目标

4.1.3目标检测技术发展
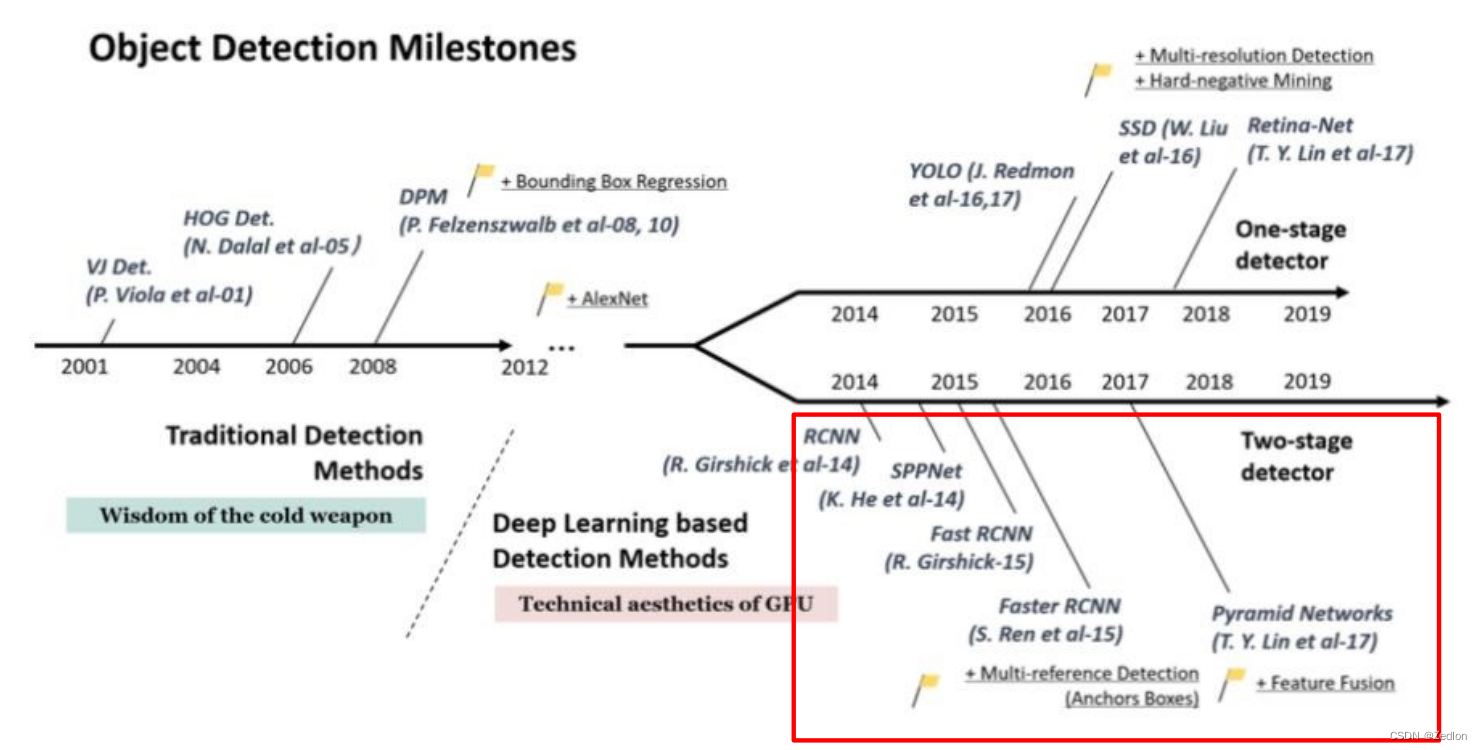
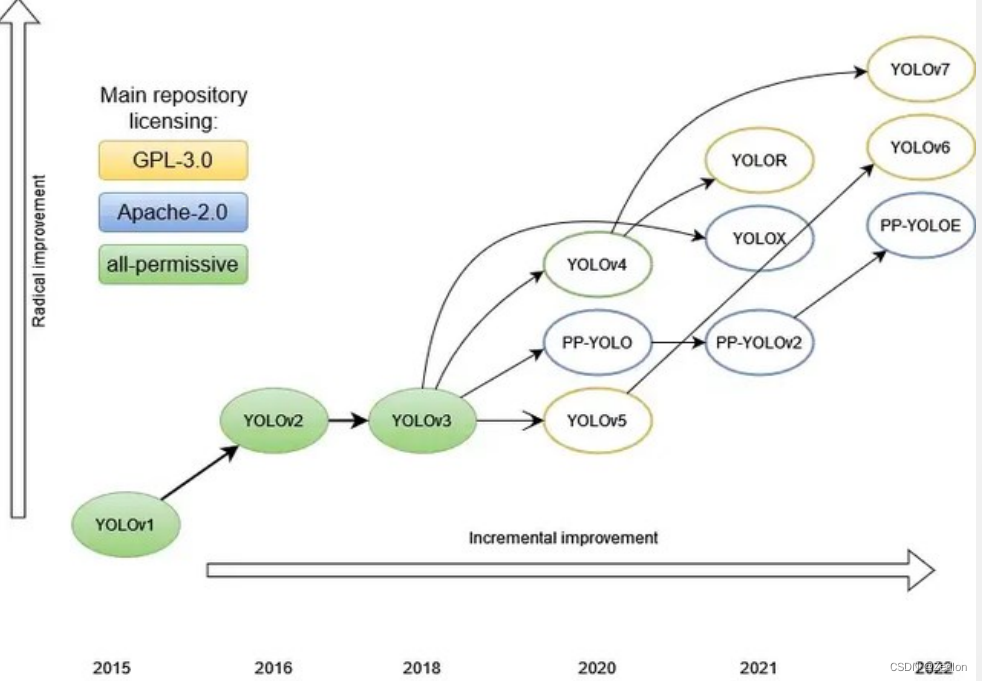
YOLO家族发展:
一步法(two-stage) : 无需候选框,直接出最终结果。优点是快。
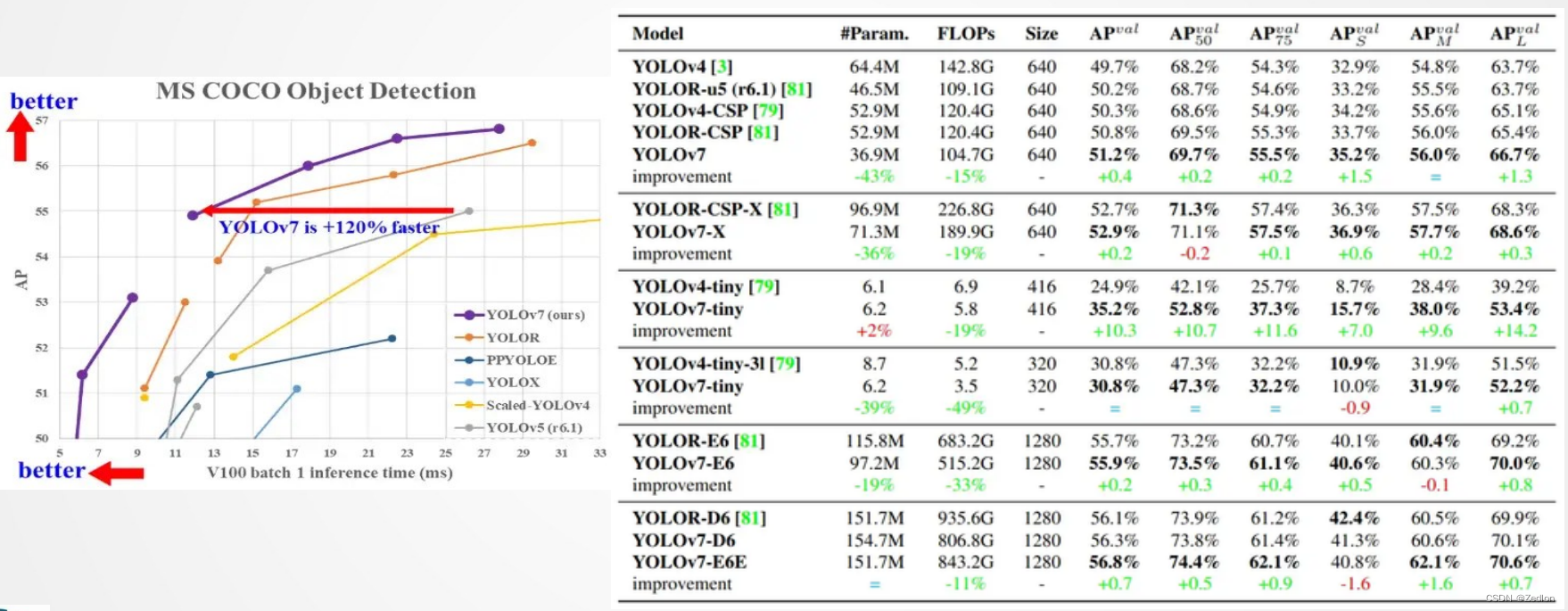
YOLO V7性能:
4.2 目标检测基本思想
4.2.1 滑动窗口
以一个比图片小的窗口大小的框,从图片左上角连续往右扫描,到头后再向下平移一个像素点继续从左到右扫描,直到图片全部被扫描。
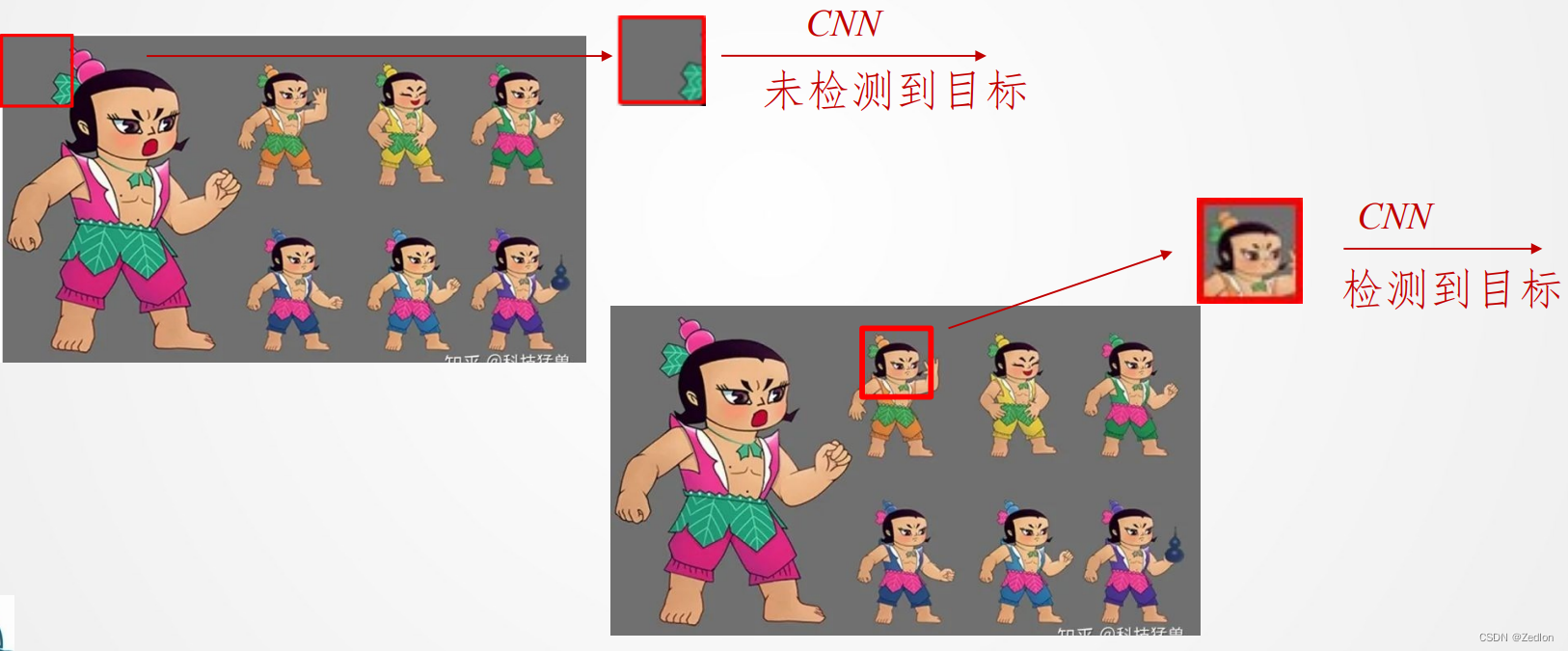
滑动窗口的问题1
滑动次数太多,计算太慢
假设图片为𝑤宽,ℎ高,识别一幅图片需要𝑇时间,则需要: 𝑤 ∗ ℎ ∗ 𝑇的总时间。
例如:图片大小448 × 448,识别一个目标需要0.05s,则: 总时间= 448 ∗ 448 ∗ 0.05 ≈ 10000𝑠,约3小时!
滑动窗口的问题2
目标大小不同,每一个滑动位置需要用很多框
图片宽度和高度都不相同,比例也不相同,因此需要取很多框。
例如:标准框100*50大小
• 取50*50,50*25,200*50,200*100等不同大小,在面积和宽高比变化
• 假设面积变化3类(0.5,1,2), 宽高比3类(0.5,1,2),则共有9种。 总时间是原来的9倍: 总时间= 10000 × 9 = 90000𝑠,约1天3小时!
4.2.2滑动窗口的改进
一般图片中,大多数位置都不存在目标。
可以确定那些更有可能出现目标的位置,再有针对性的用CNN进行检测——两步法(Region Proposal)
两步法依然很费时!
进一步减少出现目标的位置,而且将目标分类检测和定位问题合在一个网络里——一步法(YOLO)
简化的二分类问题:只检测一类(葫芦娃脸)
分成互补重叠的cell
产生问题:目标的大小和位置?

4.2.3一步法基本思想
分类问题扩展为回归+分类问题

问题1:有一个框里有多个,有个多个框里有一个,怎么办?
多个框里有一个目标,取目标中心点所在框
一个框里有多个,暂不能解决

问题 2 :多类目标怎么办?
使用独热编码扩展类别数
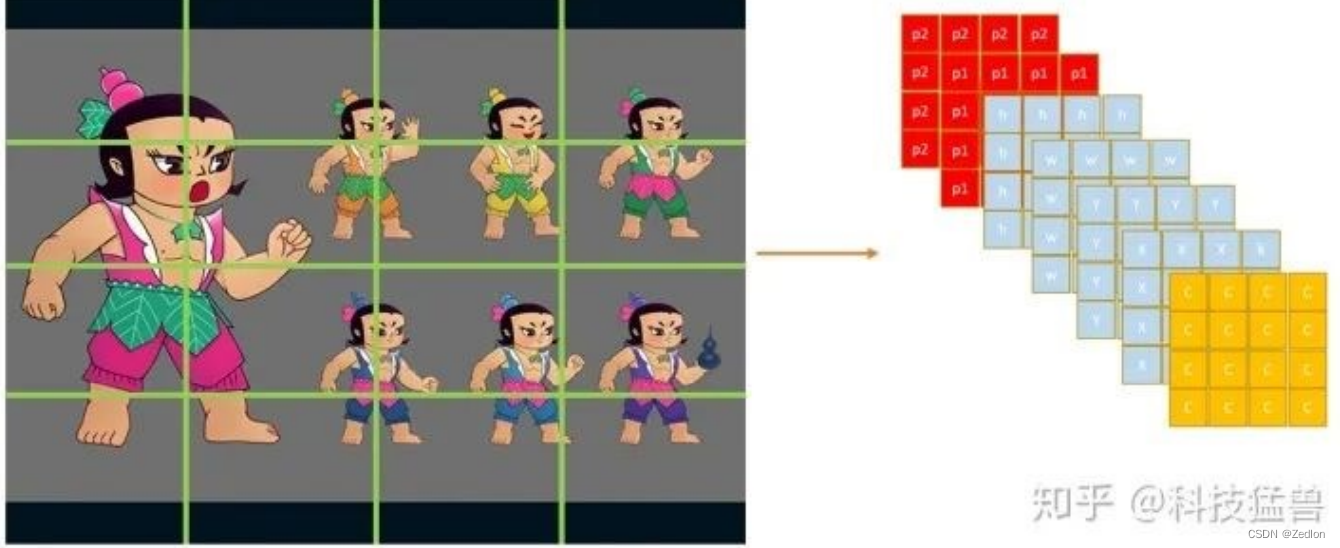
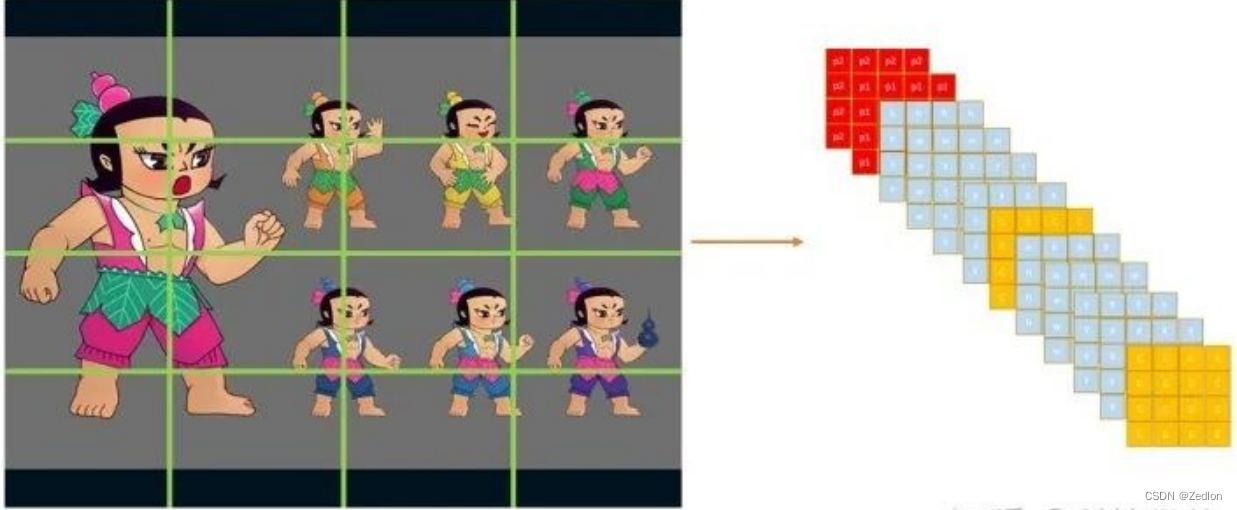
问题3:小目标怎么办?
使用单独网络拟合小目标,即设置多个bounding box.
4.3YOLO网络结构
4.3.1YOLO网络结构
4.3.2YOLO模型处理
YOLO网络输入:
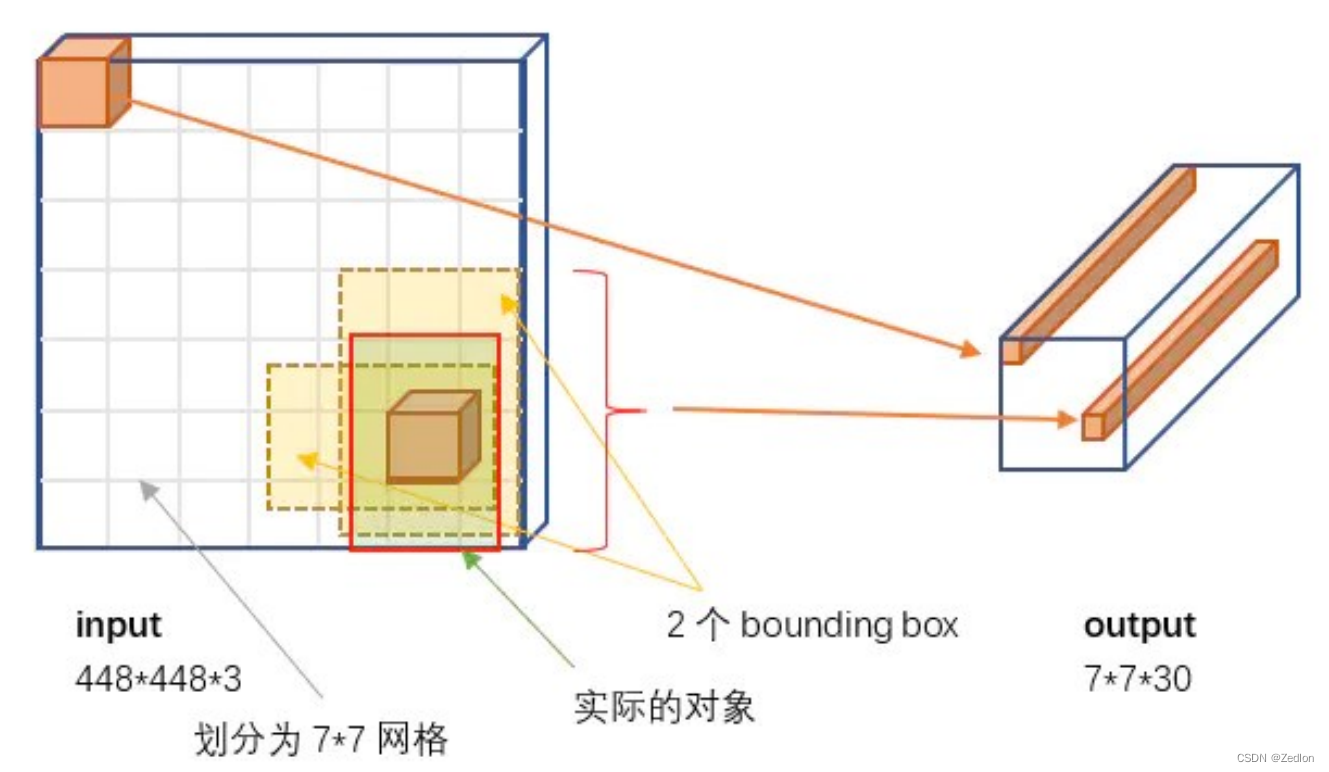
YOLO v1在PASCAL VOC数据集上进行的训练,因此输入图片为 448 × 448 × 3。实际中如为其它尺寸,需要resize或切割成要求尺寸。
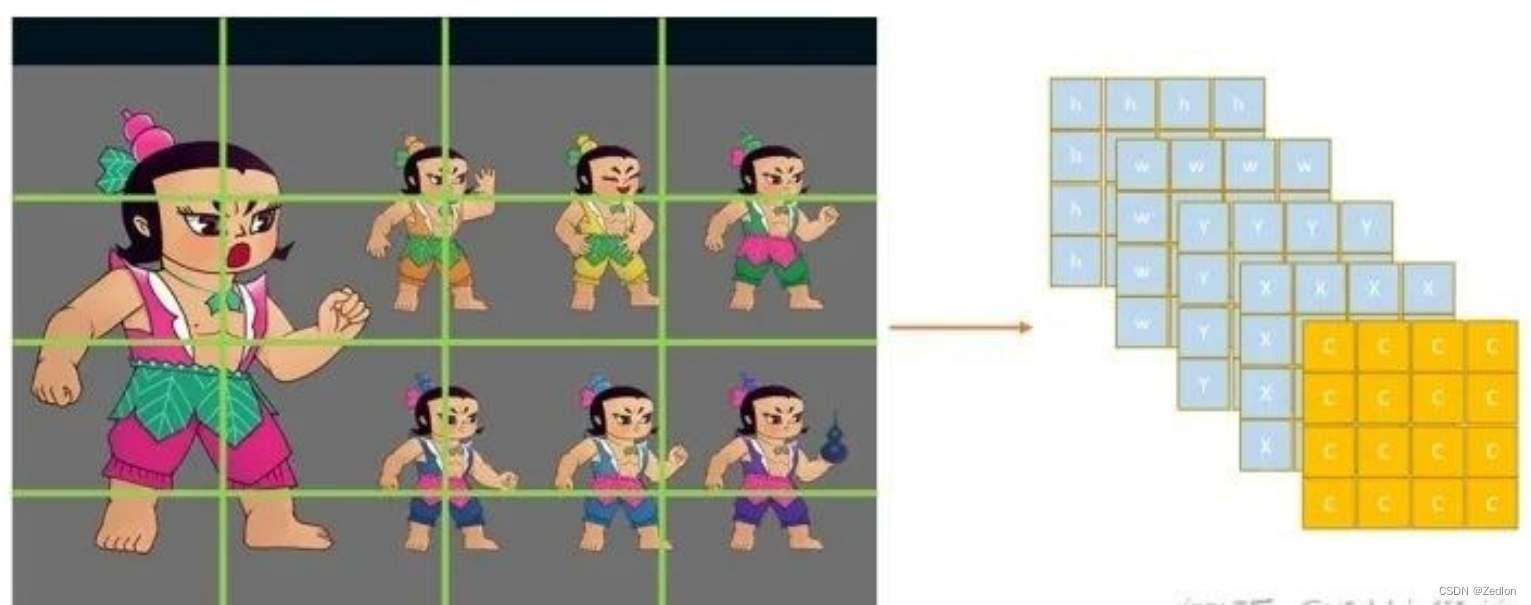
YOLO模型处理:𝟕 × 𝟕网格划分
将图片分割为 𝑆 2个grid(𝑆 = 7),每 个grid cell的大小都是相等的
每个格子都可以检测是否包含目标
YOLO v1中,每个格子只能检测一种物体(但可以不同大小)。

YOLO网络输出
输出是一个7 × 7 × 30的张量。对应 7 × 7个cell
每个cell对应2个包围框(bounding box, bb),预测不同大小和宽高比,对应检测不同目标。每个bb有5个分量,分别是物体的中心位置(𝑥, 𝑦)和它的高 (ℎ) 和宽 (𝑤) ,以及这次预测的置信度。 在右图中,每个框代表1个预测的bb,粗细代表不同的置信度,越粗得越高。

在上面的例子中,图片被分成了49个框,每个框预测2个bb,因此上面的图中有98个bb
4.4包围框与置信度
4.4.1YOLO包围框
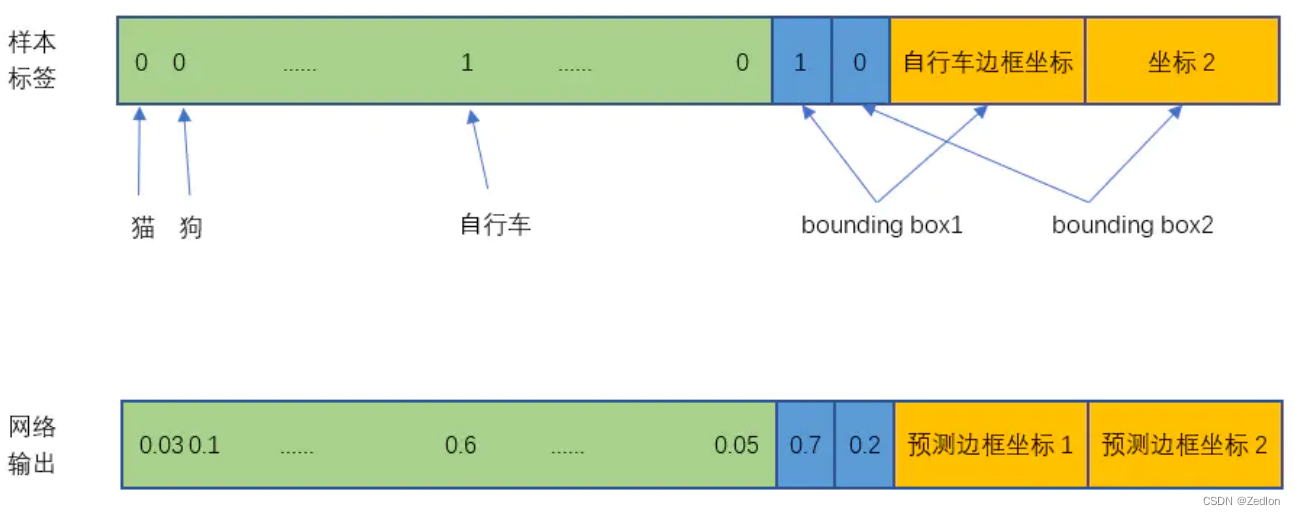
我们有 𝑠 2个框,每个框的bb个数为𝐵,分类器可以识别出𝐶种不同的物体,那么所有整个ground truth的长度为𝑆 × 𝑆 × (𝐵 × 5 + 𝐶)
YOLO v1中,这个数量是30
YOLO v2和以后版本使用了自聚类的anchor box为bb, v2版本为𝐵 = 5, v3中 𝐵 =9
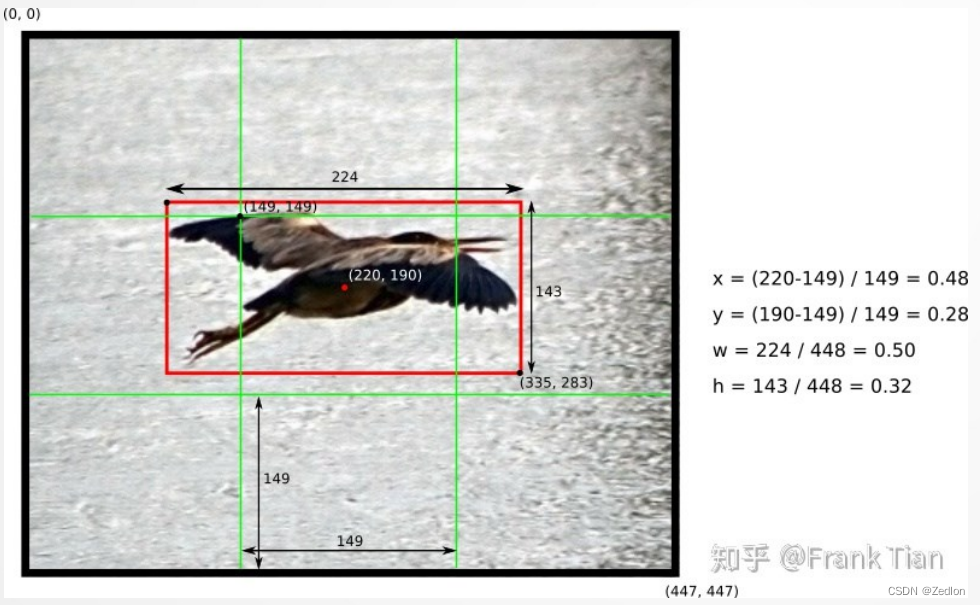
处理细节——归一化
四个关于位置的值,分别是𝑥, 𝑦, ℎ和𝑤,均为整数,实际预测中收敛慢
因此,需要对数据进行归一化,在0-1之间。
例子是一个448*448的图片,有3*3的grid,每个 cell是149。目标中心点是(220,190)
4.4.2YOLO置信度
处理细节——置信度置信度计算公式:![]()
Pr(𝑜𝑏𝑗)是一个grid有物体的概率
IOU是预测的bb和真实的物体位置的交并比。
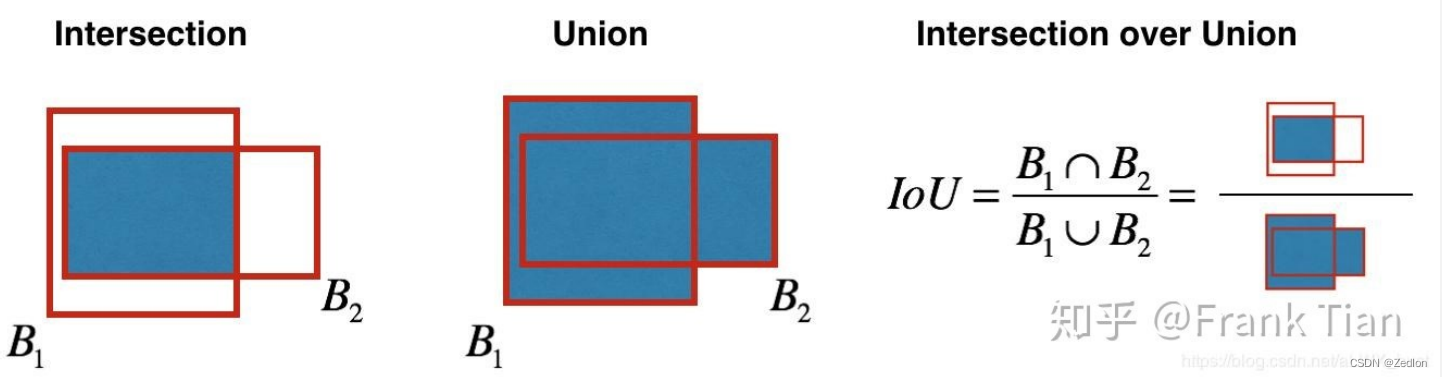
𝐼𝑂𝑈:图中绿框为真实标注,其余五个颜色框为预测值,可计算对应𝐼𝑂𝑈
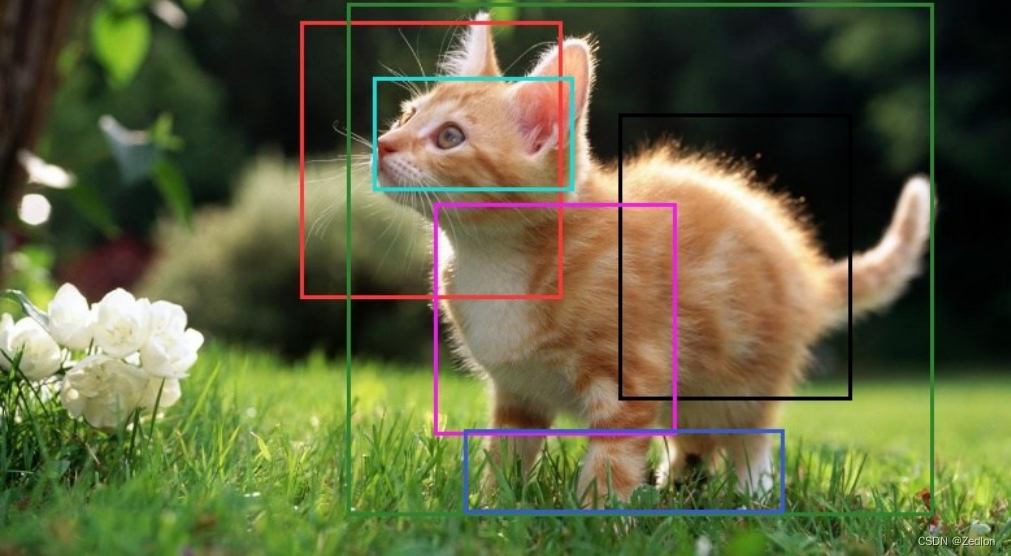
4.4.3训练值与预测值
处理细节——训练值(ground truth)
Pr(𝑜𝑏𝑗)的ground truth:三个目标中点对应格子为1,其它为0

处理细节——训练数据与网络输出
4.5损失函数
4.5.1YOLO损失函数
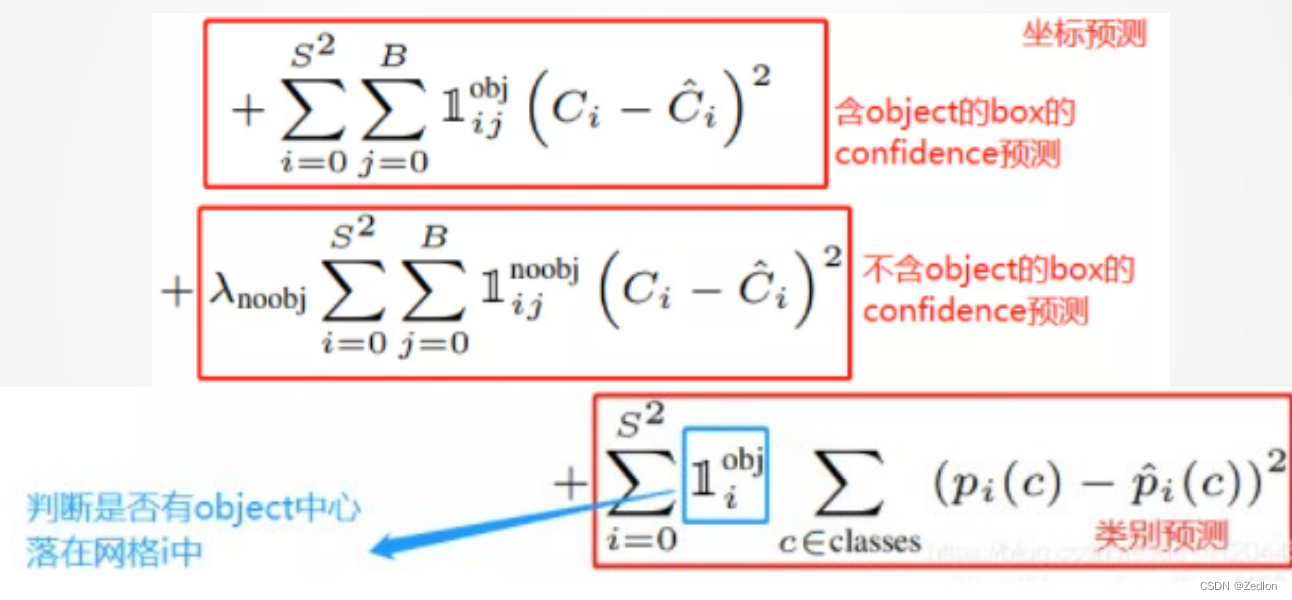
YOLO损失函数(一共五项)

YOLO损失函数——边界框对应损失项

为什么第2项要开根号?让误差更显著,保证回归精度

YOLO损失函数——𝝀取值

4.6 训练与NMS
4.6.1 非极大值抑制
保留了这么多边界框,预测中一个物体可能被多个边界框包围;实际物体只对应一个边界框,如何解决个问题呢?NMS
NMS核心思想是:选择得分最高的作为输出,与该输出重叠的去掉,不断重复这一过程直到所有备选处理完。
NMS算法要点
1. 首先丢弃概率小于预定IOU阈值(例如0.5)的所有边界框;对于剩余的边界框:
2. 选择具有最高概率的边界框并将其作为输出预测;
3. 计算“作为输出预测的边界框”,与其他边界框的相关联IoU值;舍去IoU大于阈值的边界框;其实就是舍弃与“作为输出预测的边界框”很相近的框框。
4. 重复步骤2,直到所有边界框都被视为输出预测或被舍弃
NMS算法示例
汽车不止一次被检测

1. 它首先查看与每次检测相关的概率并取最大的概率。图中选概率为0.9的方框;
2. 进一步查看图像中的所有其他框。与当前边界框较高的IoU的边界框将被抑制。因此图中0.6和0.7概率的边界框将被抑制。(此时面包车已经只剩一个边界框)
3. 从概率最高的所有边界框中选择下一个,在例子中为0.8的边界框;
4. 再次计算与该边界框相连边界框的IoU,去掉较高IoU值的边界框。
5. 重复这些步骤,得到最后的边界框:

4.6.2 数据集训练
预训练与训练
YOLO先使用ImageNet数据集对前20层卷积网络进行预训练,然后使用完整的网络,在PASCAL VOC数据集上进行对象识别和定位的训练和预测
训练中采用了drop out和数据增强来防止过拟合。
YOLO的最后一层采用线性激活函数(因为要回归bb位置),其它层都是采用Leaky ReLU激活函数:
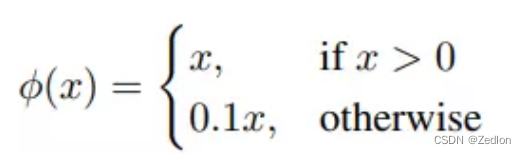
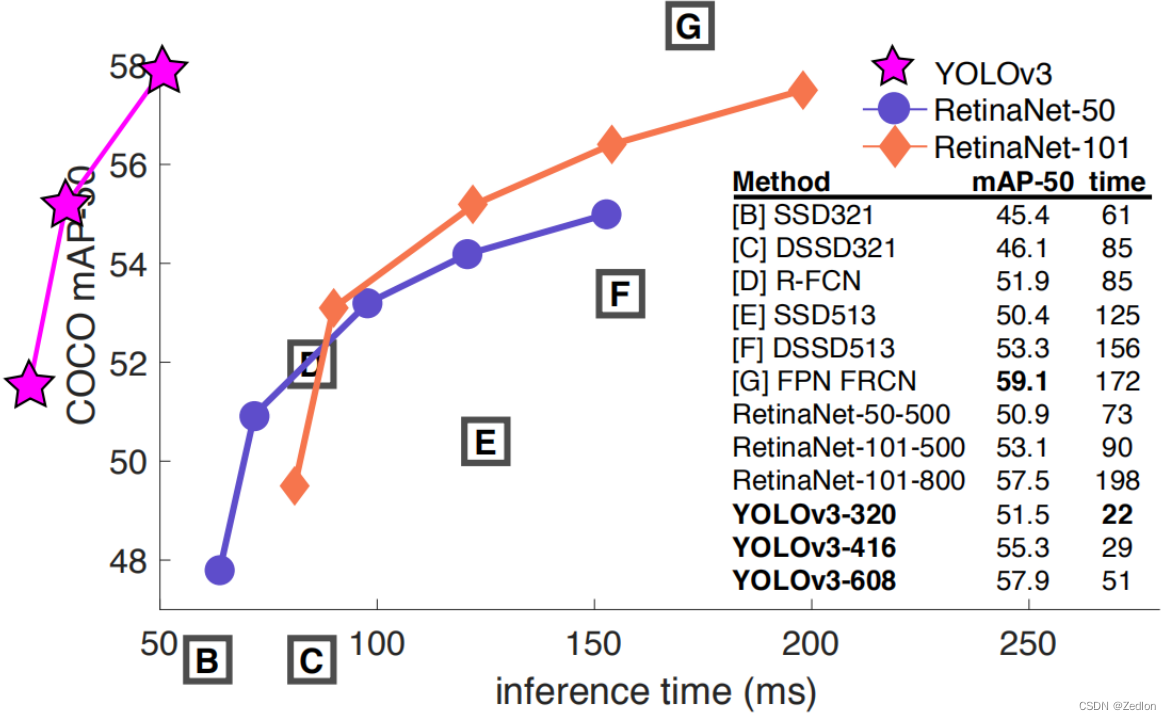
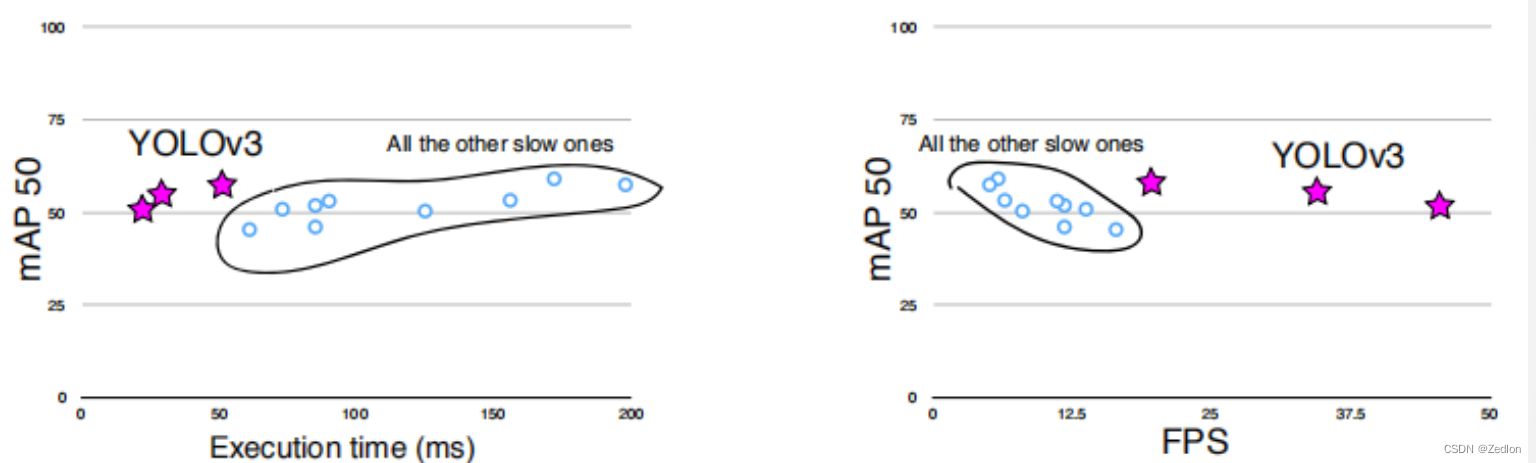
YOLO v3模型效果
4.7 语义分割
4.7.1语义分割
语义分割关注如何将图像分割成属于不同语义类别的区域。值得一提的是,这些语义区域的标注和预测都是像素级的。下图展示了语义分割中图像有关狗、猫和背景的标签。可以看到,与目标检测相比,语义分割标注的像素级的边框显然更加精细。

计算机视觉领域还有2个与语义分割相似的重要问题,即图像分割和实例分割。我们在这里将它们与语义分割简单区分一下。
• 图像分割将图像分割成若干组成区域。这类问题的方法通常利用图像中像素之间的相关性。它在训练时不需要有关图像像素的标签信息,在预测时也无法保证分割出的区域具有我们希望得到的语义。
• 实例分割又叫同时检测并分割。它研究如何识别图像中各个目标实例的像素级区域。与语义分割有所不同。
• 以上一张ppt中的两只狗为例,图像分割可能将狗分割成两个区域:一个覆盖以黑色为主的嘴巴和眼睛,而另一个覆盖以黄色为主的其余部分身体。而实例分割不仅需要区分语义,还要区分不同的目标实例。如果图像中有两只狗,实例分割需要区分像素属于这两只狗中的哪一只。
语义分割数据集
我们画出前5张输入图像和它们的标签。在标签图像中,白色和黑色分别代表边框和背景,而其他不同的颜色则对应不同的类别。
n = 5
imgs = train_features[0:n] + train_labels[0:n]
d2l.show_images(imgs, 2, n);

4.8风格迁移
4.8.1简介
如果你是一位摄影爱好者,也许接触过滤镜。它能改变照片的颜色样式,从而使风景照更加锐利或者令人像更加美白。但一个滤镜通常只能改变照片的某个方面。如果要照片达到理想中的样式,经常需要尝试大量不同的组合,其复杂程度不亚于模型调参。
在本节中,我们将介绍如何使用卷积神经网络自动将某图像中的样式应用在另一图像之上,即风格迁移。
这里我们需要两张输入图像,一张是内容图像,另一张是样式图像,我们将使用神经网络修改内容图像使其在样式上接近样式图像。

方法
首先,我们初始化合成图像,例如将其初始化成内容图像。该合成图像是样式迁移过程中唯一需要更新的变量,即样式迁移所需迭代的模型参数。
然后,我们选择一个预训练的卷积神经网络来抽取图像的特征,其中的模型参数在训练中无须更新。深度卷积神经网络凭借多个层逐级抽取图像的特征。我们可以选择其中某些层的输出作为内容特征或样式特征。
以之前放的图像为例,这里选取的预训练的神经网络含有3个卷积层, 其中第二层输出图像的内容特征,而第一层和第三层的输出被作为图像的样式特征。 接下来,我们通过正向传播(实线箭头方向)计算样式迁移的损失函数 ,并通过反向传播(虚线箭头方向)迭代模型参数,即不断更新合成图像。
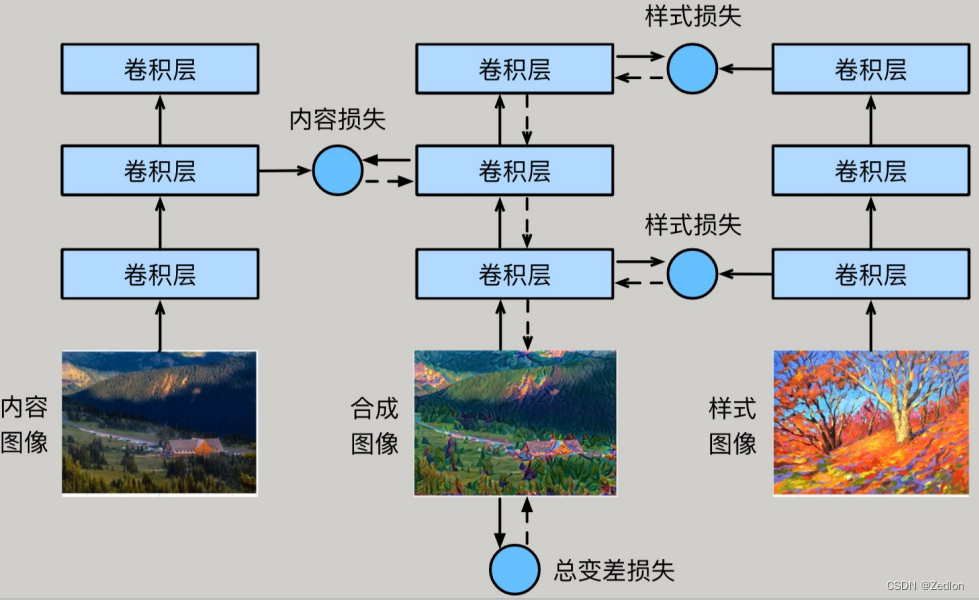
样式迁移常用的损失函数由3部分组成:
内容损失(content loss)使合成图像与内容图像在内容特征上接近
样式损失(style loss)令合成图像与样式图像在样式特征上接近
总变差损失(total variation loss)则有助于减少合成图像中的噪点。
最后,当模型训练结束时,我们输出样式迁移的模型参数,即得到最终的合成图像。
4.8.2内容代价函数
选定隐藏层l,用𝑎 𝑙 [𝐶]表示图片C在第l层的激活项输出,𝑎 𝑙 [G]表 示图片G在第l层的激活项输出,则定义内容代价函数如下:
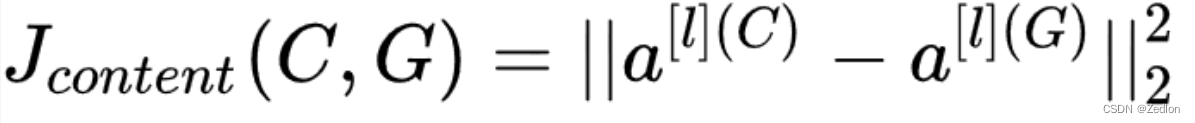
什么是风格? 神经网络各隐藏层输出激活项的含义。

风格代价函数
怎样量化风格差异?
相关性的计算:
怎样量化风格差异?
风格矩阵(Style matrix) :
(1)什么是风格矩阵

(2)符号规定

( 3)计算
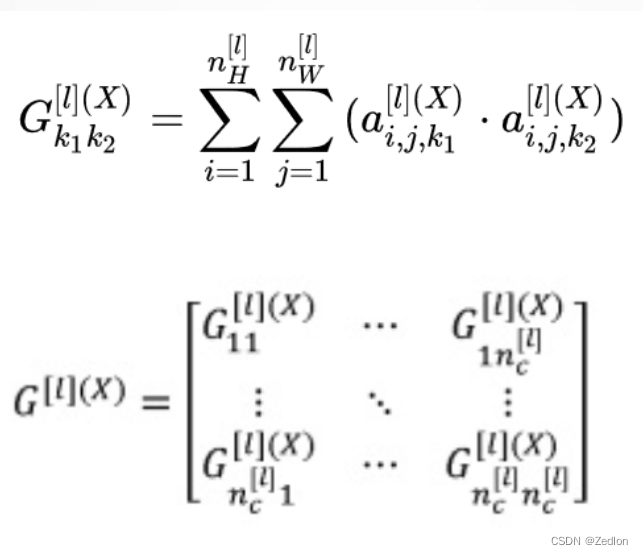
风格代价函数:
(1)隐藏层l的风格代价函数
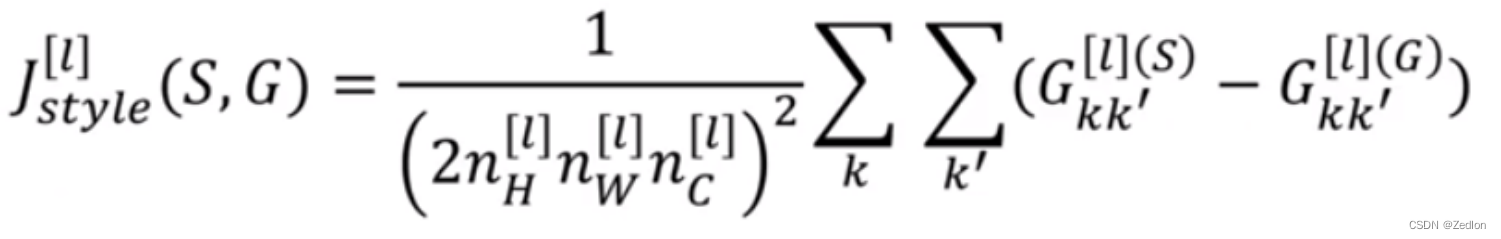
(2)总体风格代价函数
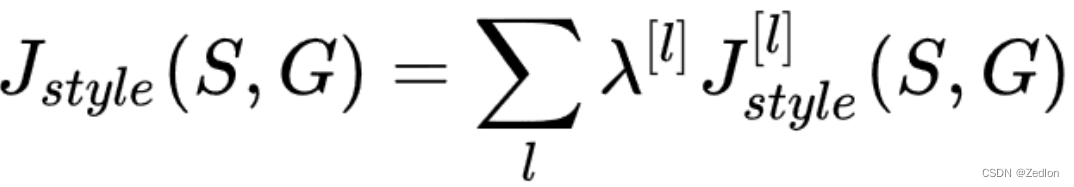
总体代价函数
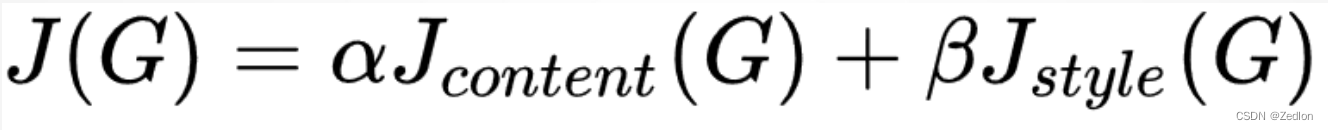
4.8.3训练
读取内容图像和样式图像
预处理和后处理图像
抽取特征
定义损失函数
样式迁移的损失函数。它由3部分损失组成。
内容损失
样式损失
总变差损失
训练合成图像
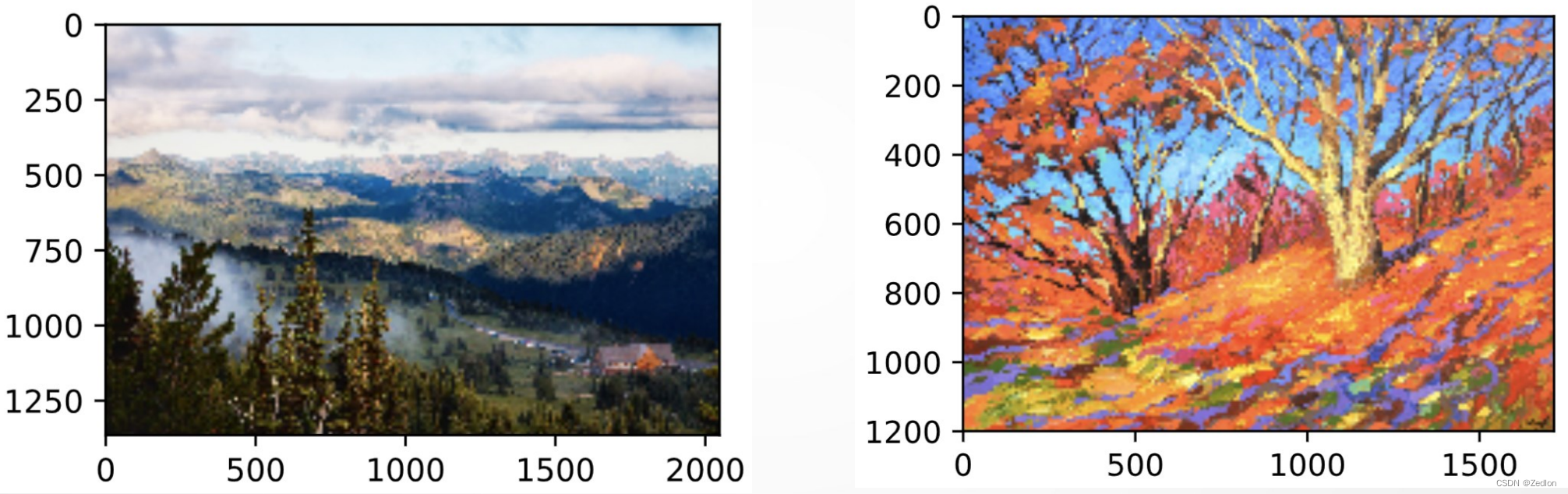
下面我们查看一下训练好的合成图像。可以看到图中的合成图像保留了内容图像的风景和物体,并同时迁移了样式图像的色彩。因为图像尺寸较小 ,所以细节上依然比较模糊。

为了得到更加清晰的合成图像,下面我们在更大的300×450300×450尺寸上训练。我们将原图的高和宽放大2倍,以初始化更大尺寸的合成图像。
从训练得到的图中可以看到,此时的合成图像因为尺寸更大, 所以保留了更多的细节。合成图像里面不仅有大块的类似样式图像的油画色彩块, 色彩块中甚至出现了细微的纹理。

样式迁移常用的损失函数由3部分组成:内容损失使合成图像与内容图 像在内容特征上接近,样式损失令合成图像与样式图像在样式特征上 接近,而总变差损失则有助于减少合成图像中的噪点。
可以通过预训练的卷积神经网络来抽取图像的特征,并通过最小化损 失函数来不断更新合成图像。
用格拉姆矩阵表达样式层输出的样式。
4.9人脸识别
4.9.1 两类问题的区别
人脸验证(Face verification)
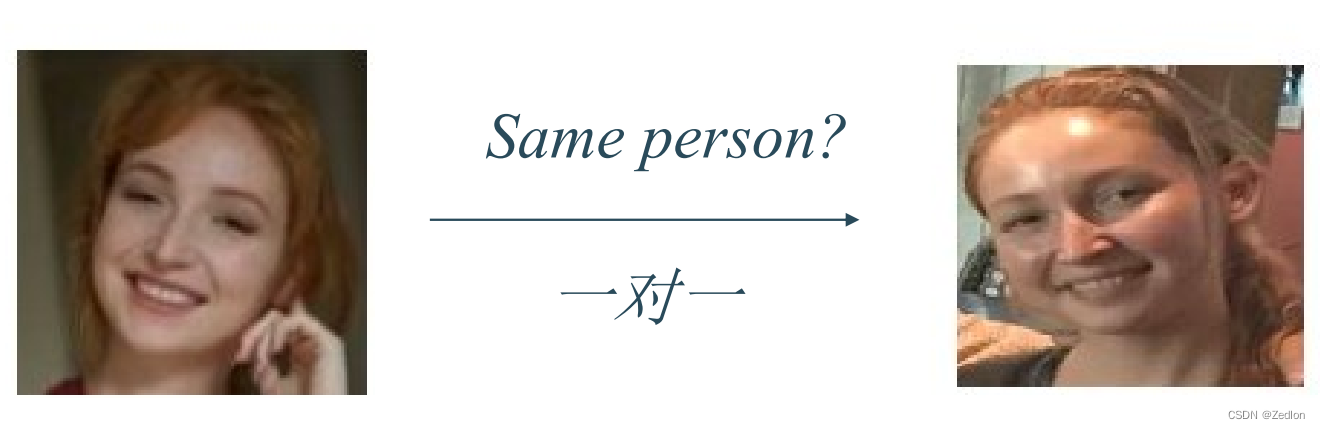
人脸识别(Face recognition)
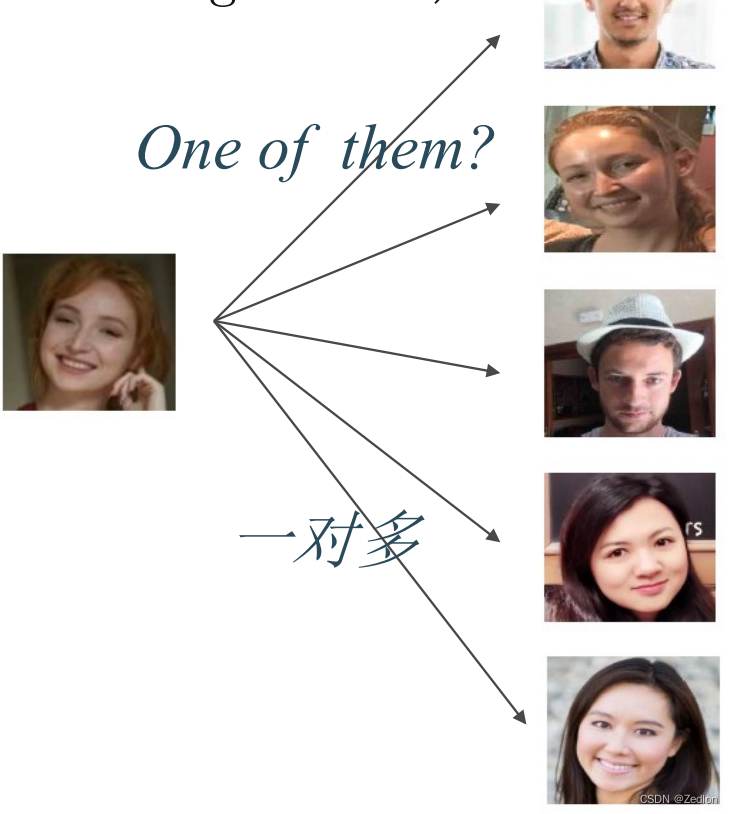
4.9.2从人脸验证到人脸识别
for i in 数据库中的所有照片:
调用人脸验证检测输入与数据库中照片i上的是否为同一人
4.9.3 构建神经网络
旧有思路
转化为分类问题
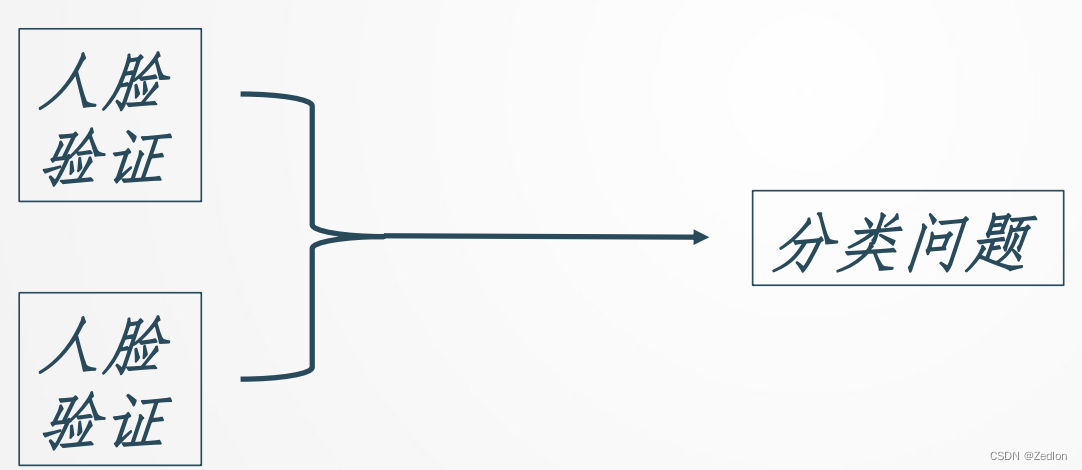
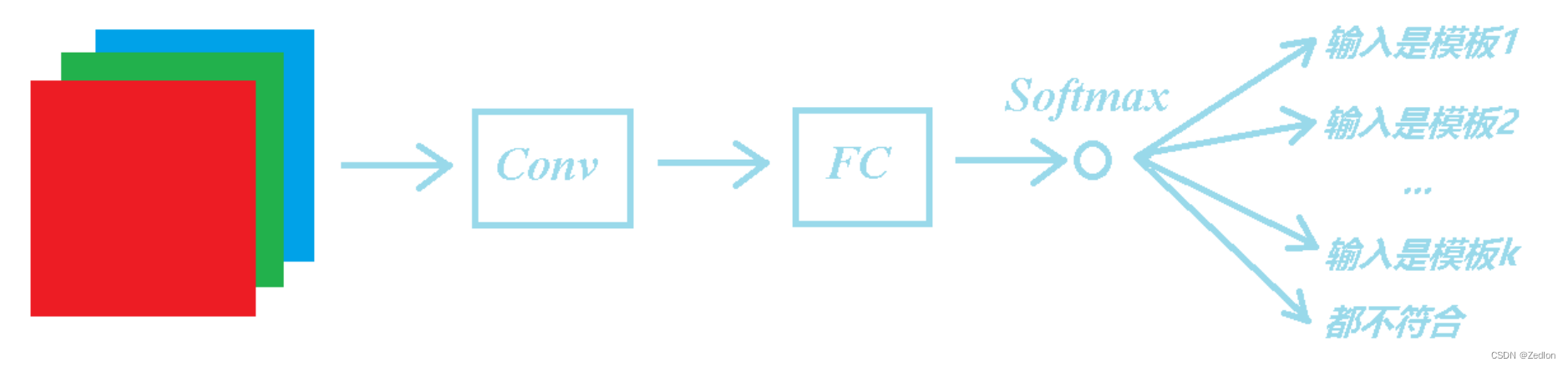
相似度函数

Siamese网络
对输入图片进行编码
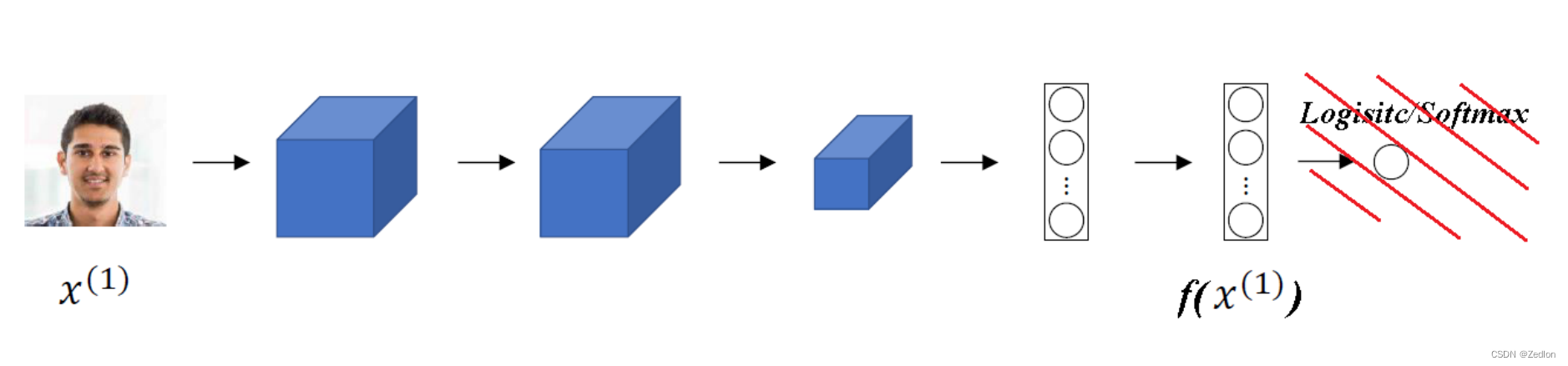
双输入结构
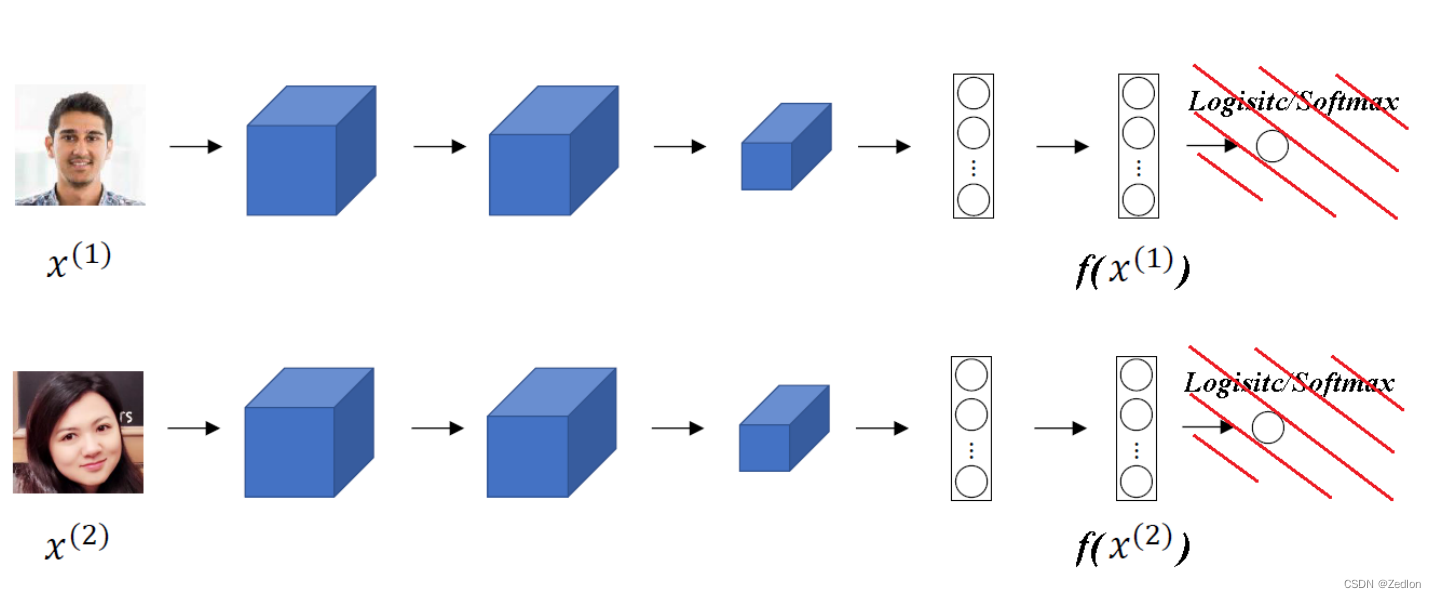
相似度函数的具体定义
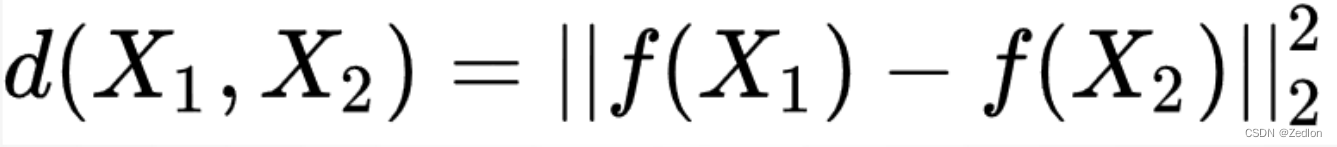
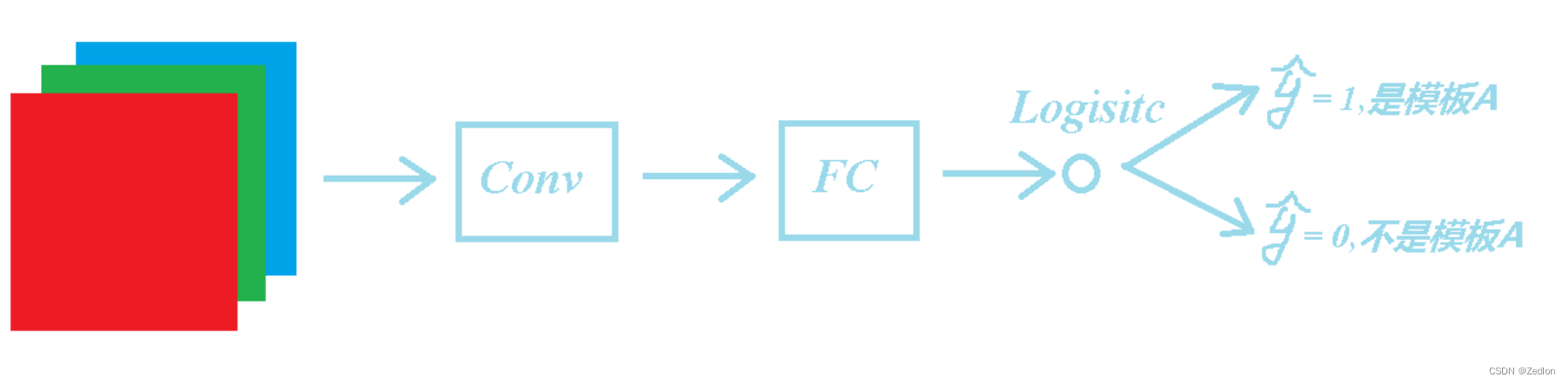
面部验证与二分类
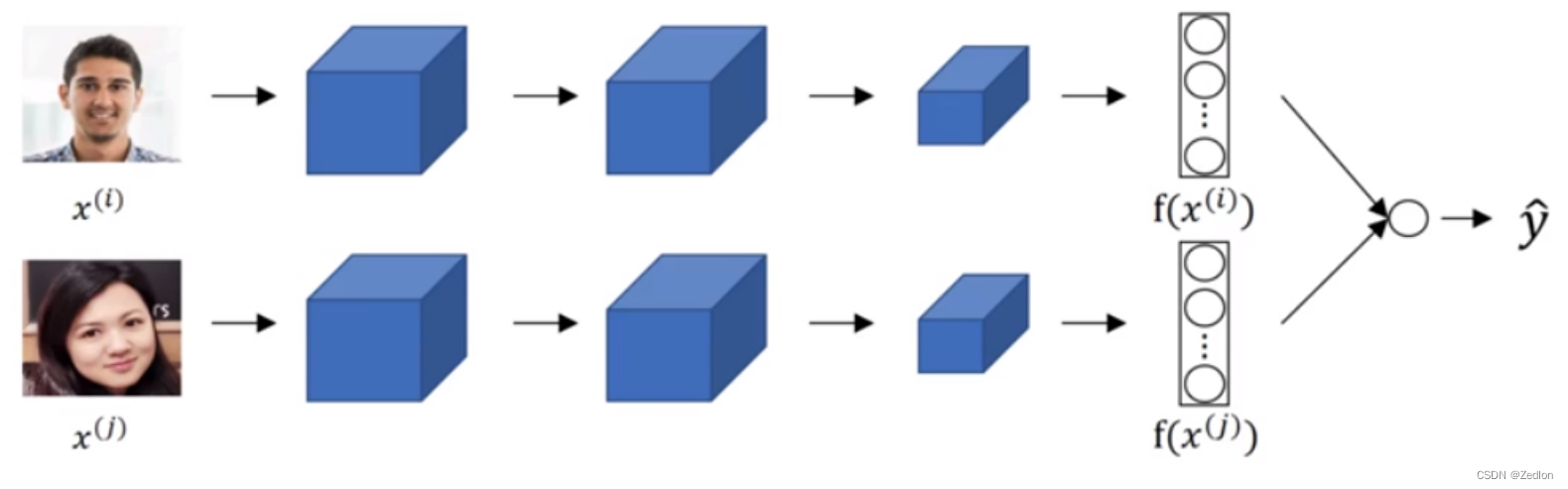
面部验证与二分类 输出softmax神经元: 也可以采用均方形式。
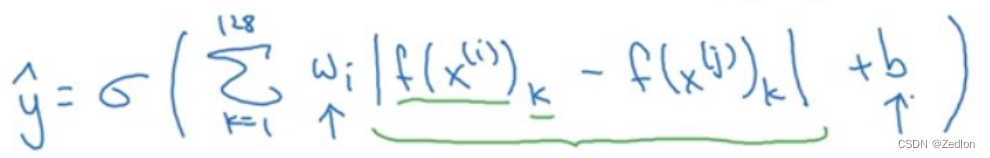















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









