







1、什么是UVM?它的优势是什么?
**UVM(Universal Verification Methodology)**是一个标准化的用于验证设计的方法学。其优势包括:
重用性、VIP即插即用、通用性、独立于仿真器、支持CDV(coverage driven verification)、支持CRV(constraint random verification)等等
2、uvm_component和uvm_object有什么区别?
**uvm_component:**在build_phase之后就一直存在于整个仿真周期。通过interface连接到DUT或者通过TLM port连接到其他uvm_component。通过configure机制和phase机制控制uvm_component的层次结构和仿真行为。
**uvm_object:**从一个uvm_component生成,然后传递到另一个uvm_component之后就会消失。不会连接到任何组件,也不存在phase机制
3、为什么需要phase机制,不同的phase有什么区别?
phase机制用来控制和同步不同uvm_component的仿真行为。
可以根据是否消耗仿真时间区分为function phase和task phase
4、哪些phase是top-down phase、bottom-up phase和parallel phase?
build_phase是top-down phase,run phase等task phase是parallel phase,其他都是bottom-up phase。
5、为什么build_phase是top-down phase,而connect_phase是bottom-up phase?
build_phase需要验证平台根据高层次组件的配置来决定建立低层次的组件,所以其是top-down phase。
connect_phase需要在build_phase之后完成验证组件之间TLM连接
6、uvm phase仿真是怎么开始启动的?
通过在顶层调用run_test,run_test任务会首先创建test top,然后调用所有的phase,开始仿真。
7、VCS中通过什么方式执行对应的test case?
在顶层调用run_test(),在仿真选项中使用
+UVM_TESTNAME = testname
8、uvm_config_db和uvm_resource_db有什么区别?
uvm_config_db和uvm_resource_db都是参数化的类,用于配置验证组件中不同类型的参数。相比于uvm_resource_db,uvm_config_db增加了层次关系。对于最后配置的参数值,uvm_resource_db是**“last write wins”, uvm_config_db是“parent wins”**
9、什么是factory automation?
factory是一种在验证环境中实例化组件或生成激励时提供更大灵活性的机制。factory机制允许在不修改原始源代码的条件下覆盖现有验证代码创建的对象类型
10、当前类的super class是什么?
super class是当前类所**“扩展(extends)”**的类。例如,my_test的super class是uvm_test
11、什么是事物级建模(Transaction Level Modelling)?
事务级别建模(TLM)是一种在较高抽象级别上对系统设计或模块设计进行建模的方法,抽象出所有底层实现细节。
这是验证方法学中用于提高模块化和重用性的关键概念之一。即使DUT的实际接口由信号级别表示,但大多数验证任务(如生成激励,功能检查,收集覆盖率数据等)都可以在事务级别上更好地完成。这有助于验证组件在项目内部和项目之间重用和维护。
12、什么是TLM ports和exports?
在事务级别建模中,不同的组件或模块使用事务对象进行通信。TLM port定义了用于连接的一组方法(API),而这些方法的具体实现称为TLM exports。
TLM port和export之间的连接建立了两个组件之间的通信机制。producer可以创建事务并将其“put”到TLM端口,而“put”方法实现(也称为TLM export)将在consumer中读取producer创建的事务,从而建立通信渠道。
13、什么是TLM FIFOs?
如果producer组件和consumer组件需要独立运行,则可以使用TLM FIFO进行事务通信。在这种情况下,producer组件生成事务并将其“puts”到FIFO,而consumer组件一次从FIFO获取一个事务并对其进行处理。
14、TLM上的get()和peek()操作之间有什么区别?
get()操作将从TLM FIFO返回一个事务(如果存在的话),并且还会从FIFO中删除该事务。如果FIFO中没有可用的事务,它将阻塞并等待,直到FIFO至少有一个事务。
peek()操作将从TLM FIFO返回事务(如果存在的话),而无需从FIFO中删除该事务。这也是一个阻塞调用,如果FIFO没有可用事务,它将等待。
15、TLM fifo上的get()和try_get()操作之间有什么区别?
get()是从TLM FIFO获取事务的阻塞调用。因此如果FIFO中没有可用的事务,则任务get()将等待。
try_get()是一个非阻塞调用,即使FIFO中没有可用的事务,也会立即返回。try_get()的返回值指示是否返回有效事务项。
16、analysisports和TLM ports之间有什么区别?analysisFIFOs和TLM FIFO有什么区别?analysis ports/ FIFO在哪里使用?
TLM ports/ FIFO用于两个组件之间的事务级别通信,这两个组件具有使用put/get方法建立的通信通道。Analysis ports/FIFOs是另一种事务通信通道,用于组件将事务广播到多个组件。
TLM ports / FIFO用于driver和sequencer之间的连接,而analysis ports/FIFOs用于monitor将接收的事务广播到scoreboard或reference model。
17、sequence和sequence item有什么区别?
sequence item是一个对象,其建模了两个验证组件之间传输的信息(有时也可以称为事务(transaction))。例如:读操作和写操作中的地址和数据信息。
sequence是由driver驱动的sequence item序列模式,由其body()方法实现。例如:连续读取10次事务。
18、uvm_transaction和uvm_sequence_item有什么区别?
uvm_transaction是从uvm_object派生的用于对事务进行建模的基类。
sequence item是在uvm_transaction的基础上还添加了一些其他信息的类,例如:sequence id。建议使用uvm_sequence_item实现基于sequence的激励。
19、copy()、clone()和create()方法之间有什么区别?
**create()**方法用于构造一个对象。
**copy()**方法用于将一个对象复制到另一个对象。
**clone()**方法同时完成对象的创建和复制。
20、解释UVM方法学中的Agent概念。
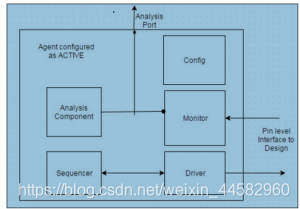
UVM agent集合了围绕DUT的其他uvm_components。大多数DUT具有多个interfaces,并且一个Agent用于组合driver、sequencer和monitor。使用此层次结构有助于在不同验证环境和项目之间重用Agent。
21、get_name()和get_full_name()有什么区别
get_name()函数返回对象的名称,该对象的名称由new构造函数或set_name()方法提供。
get_full_name()返回对象的完整层次结构名称。对于uvm_components,这在打印语句中使用时很有用,因为它显示了组件的完整层次结构。对于没有层次结构的sequence或配置对象,与get_name()打印相同的值
22、ACTIVE agent与PASSIVE agent有何不同?
ACTIVE agent是可以在其操作的接口上生成激励,其包含driver和sequencer。
PASSIVE agent不生成激励,只能监视接口,这意味着在PASSIVE agent中将不会创建driver和sequencer。
23、Agent如何配置为“ACTIVE”或“PASSIVE”?
UVM agents具有类型为uvm_active_passive_enum的变量,该变量定义agents是否是active (UVM_ACTIVE)(构建了sequencer和driver)或者passive(UVM_PASSIVE) (不构建sequencer和driver)。
此参数默认情况下设置为UVM_ACTIVE,在environment类中创建agents时,可以使用**set_config_int()**进行更改。然后,agent的build phase阶段应具有以下代码以选择性地构建driver和sequencer。
function void build_phase(uvm_phase phase);
if(m_cfg.active == UVM_ACTIVE) begin
//create driver, sequencer
end
endfunction
24、什么是driver和sequencer,为什么需要它们?
Driver是根据接口协议将事务转换为一组信号级切换的组件。Sequencer是一个将事务(sequence items)从sequence发送到Driver,并将Driver的响应反馈给sequence的组件。
sequencer也会对同时尝试访问Driver以激励设计接口的多个sequences进行仲裁。sequence和sequencer在事务级抽象,Driver在信号级对设计接口进行驱动,即单一设计模式。
25、UVM中的monitor和scoreboard有什么区别?
monitor是一个监测引脚级别的信号活动并将其转换为事务或sequence_items的组件。monitor还通过analysis port将这些事务发送到其他组件。
scoreboard用于检查DUT的行为是否正确。
26、哪个方法可以激活UVM验证平台,如何调用它?
**run_test()方法(静态方法)**用来激活UVM验证平台。通常在顶层的“ initial begin…end”块中调用,并且它使用一个参数指定要运行的test case。run_test()方法在build_phase()中执行test class的构造函数,并进一步构造层次化的Env / Agent / Driver / Sequencer对象。

27、运行sequence需要什么步骤?
启动sequence需要执行三个步骤,如下所示:
**1)**创建一个序列。使用工厂创建方法创建一个序列:
my_sequence_c seq;
seq = my_sequence_c ::type_id :: create(“ my_seq”)
**2)**配置或随机化序列。
seq.randomize()
**3)**开始一个sequence。使用sequence.start()方法启动序列。start方法需要输入一个指向sequencer的参数。关于sequence的启动,UVM进一步做了封装。
28、解释sequencer和driver之间的握手协议?
UVM将sequence item从sequence传输到driver并收集来自driver的响应。
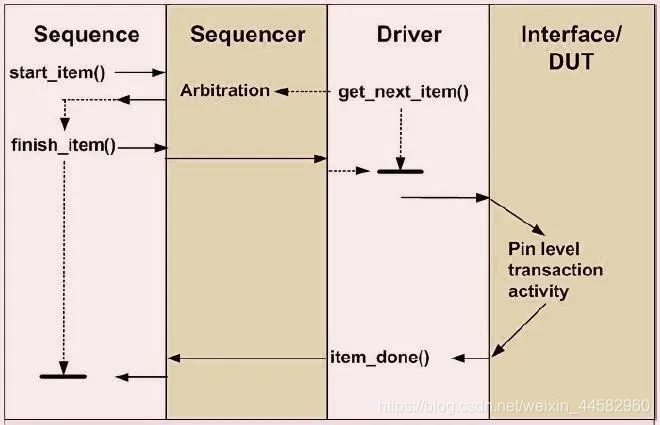
在sequence端:
1)start_item():请求sequencer访问driver
2)finish_item():使driver接收sequence item,这是阻塞调用,在driver调用item_done()方法后才返回。
在driver端:
1)get_next_item(req):这是driver中的一个阻塞方法,直到接收到sequence item,driver可以将其转换为引脚级协议信号。
2)item_done(req):向sequencer发出信号,表明它可以接受新的sequence请求,使得sequence解除对finish_item()方法的阻塞。
29、sequence中的pre_body()和post_body()函数是什么?它们总是被调用么?
**pre_body()是sequence类中的方法,该方法在body()**方法之前调用,然后调用post_body()方法。
uvm_sequence:: start()有一个可选参数,如果将其设置为0,将不调用这些方法。以下是sequence中start()方法的参数:
virtual task start (
uvm_sequencer_base sequencer, // Pointer to sequencer
uvm_sequence_base parent_sequencer = null, // parent sequencer
integer this_priority = 100, // Priority on the sequencer
bit call_pre_post = 1); // pre_body and post_body called
30、Sequencer有哪些不同的仲裁机制可用于?
多个sequences可以同时连接到单个接口的driver上。Sequencer支持仲裁机制,以确保在任何时间点只有一个sequences可以访问driver。哪个sequence_item可以发送取决于用户选择的Sequencer仲裁算法。
在UVM中实现了五种内置的Sequencer仲裁机制,也可以实现用户自定义的仲裁算法。Sequencer有一个set_arbitration()的方法,调用该方法可以选择使用哪种算法进行仲裁。可以选择的六种算法如下:
• SEQ_ARB_FIFO(Default if none specified)
• SEQ_ARB_WEIGHTED
• SEQ_ARB_RANDOM
• SEQ_ARB_STRICT_FIFO
• SEQ_ARB_STRICT_RANDOM
• SEQ_ARB_USER
31、在sequencer上启动sequence时,如何指定sequence的优先级?
通过将优先级相对值参数传递给sequence的start()方法来指定优先级,第三个参数指定优先级。
seq_1.start(m_sequencer, this, 500); //Highest priority
seq_2.start(m_sequencer, this, 300); //Next Highest priority
seq_3.start(m_sequencer, this, 100); //Lowest priority among threesequences
32、sequence如何才能独占访问sequencer?
当在sequencer上运行多个sequence时,sequencer对sequence中的每个sequence item 的访问权限进行仲裁。有时一个sequence可能希望独占访问sequencer,直到将其所有的sequence item都发送完毕为止(例如:你希望施加一个定向的激励,在此过程中不被打断)。
有两种机制允许sequence获得对sequencer的独占访问权。
lock()和unlock( ): sequence可以调用sequencer的lock方法,以通过sequencer的仲裁机制获得对driver的独占访问权限。如果还有其他标记为更高优先级的sequences,则此sequences需要等待。授予lock权限后,其他sequences将无法访问driver,直到该sequences在sequencer上调用unlock()方法。lock方法是阻塞调用,直到获得lock权限才返回。
**grab()和ungrab()😗*grab()方法类似于lock()方法,用于申请独占访问。grab()和lock()之间的区别在于,调用grab()时将立即生效,不考虑其他sequences的优先级,除非已经存在sequences调用了lock()或grab()。
33、流水线和非流水线sequence-driver模式有什么区别?
根据设计接口如何激励,可以分为两种sequence-driver模式:
**1) 非流水线模式:**如果driver一次仅对驱动一个事务,则称为非流水线模型。在这种情况下,sequence可以将一个事务发送给driver,并且driver可能需要几个周期(基于接口协议)才能完成驱动该事务。只有在该事务完成驱动之后,driver才会接受sequencer的新事务
class nonpipe_driver extends uvm_driver #(req_c);
task run_phase(uvm_phase phase);
req_c req;
forever begin
get_next_item(req); // Item from sequence via sequencer
// drive request to DUT which can take more clocks
// Sequence is blocked to send new items til then
item_done(); // ** Unblocks finish_item() in sequence
end
endtask: run_phase
endclass: nonpipe_driver
**2) 流水线模式:**如果driver一次驱动多个事务,则称为流水线模式。在这种情况下,sequence可以继续向driver持续发送新事务,而无需等待driver完成之前事务的驱动。在这种情况下,对于从该sequence发送的每个事务,driver中都会有一个单独的进程来驱动该事务,而不用等到它完成上一次事务的驱动之后再接受新事务。如果我们不需要等待设计的响应,则此模式很有用。
class pipeline_driver extends uvm_driver #(req_c);
task run_phase(uvm_phase phase);
req_c req;
forever begin
get_next_item(req);// Item from sequence via sequencer
fork
begin
//drive request toDUT which can take more clocks
//separate threadthat doesn’t block sequence
//driver can acceptmore items without waiting
end
join_none
item_done(); // **Unblocks finish_item() in sequence
end
endtask: run_phase
endclass:pipeline_driver
34、我们如何确保在driver驱动多个sequences 时,则driver的响应会发送给正确的sequences ?
如果从driver返回了几个sequences 之一的响应,则sequencer利用sequence中的sequence ID字段将响应返回给正确的sequence。driver中的响应处理代码应调用set_id_info(),以确保任何响应都具有与其原始请求相同的sequence ID。下面的代码driver的参考伪代码说明上述问题。
class my_driver extends uvm_driver;
//function that gets item from sequence port and
//drives response back
function drive_and_send_response();
forever begin
seq_item_port.get(req_item);
//function that takes req_item and drives pins
drive_req(req_item);
//create a new response item
rsp_item = new();
//some function that monitors response signals from dut
rsp_item.data = m_vif.get_data();
//copy id from req back to response
rsp.set_id_info(req_item);
//write response on rsp port
rsp_port.write(rsp_item);
end
endfunction
endclass
35、什么是m_sequencer句柄?
启动sequence时,它始终与启动sequencer相关联。m_sequencer句柄包含该sequencer的引用。使用此句柄,sequence可以访问UVM组件层次结构中的信息
36、什么是p_sequencer句柄,与m_sequencer相比有什么不同?
与sequencer,driver或monitor等UVM组件在整个仿真周期内都存在不同,UVM sequence是生命周期有限的对象。因此,如果在sequence从测试平台层次结构(组件层次结构)访问任何成员或句柄,则需要运行该sequence的sequencer的句柄。
**m_sequencer是uvm_sequencer_base类型的句柄,**默认情况下在uvm_sequence中可用。但是要访问在真实的sequencer,我们需要对m_sequencer进行转换(typecast),通常称为p_sequencer。下面是一个简单的示例,其中sequence要访问clock monitor组件的句柄。
class test_sequence_c extends uvm_sequence;
test_sequencer_c p_sequencer;
clock_monitor_c my_clock_monitor;
task pre_body();
if(!$cast(p_sequencer, m_sequencer)) begin
`uvm_fatal(“Sequencer Type Mismatch:”, ” Wrong Sequencer”);
end
my_clock_monitor = p_sequencer.clk_monitor;
endtask
endclass
class test_Sequencer_c extends uvm_sequencer;
clock_monitor_c clk_monitor;
endclass

















 6784
6784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









