







 DeepSORT是一种基于深度学习的多目标跟踪算法,它结合了深度学习特征提取和卡尔曼滤波,通过匈牙利算法进行目标匹配,解决了SORT算法中身份变换的问题,提高了跟踪的准确性和稳定性。此外,ByteTrack是另一个改进的跟踪算法,特别关注低分检测框的处理,增强了对遮挡物体的跟踪能力。
DeepSORT是一种基于深度学习的多目标跟踪算法,它结合了深度学习特征提取和卡尔曼滤波,通过匈牙利算法进行目标匹配,解决了SORT算法中身份变换的问题,提高了跟踪的准确性和稳定性。此外,ByteTrack是另一个改进的跟踪算法,特别关注低分检测框的处理,增强了对遮挡物体的跟踪能力。
多目标跟踪算法:DeepSort
https://arxiv.org/pdf/1703.07402.pdf
https://github.com/ZQPei/deep_sort_pytorch
DeepSORT(Deep Learning-based SORT)是一种基于深度学习的多目标跟踪算法,用于在视频序列中跟踪多个目标并进行身份识别。它是SORT(Simple Online and Realtime Tracking)算法的扩展,可以处理遮挡、运动模糊和光照变化等复杂情况,因此在视频监控、交通管理和人员追踪等领域得到广泛应用。
DeepSORT基于卷积神经网络(CNN)和循环神经网络(RNN)等深度学习模型,可以从目标检测框中提取出目标的特征表示,并通过匈牙利算法和卡尔曼滤波等多种跟踪技术,对多个目标进行跟踪和身份识别。具体来说,DeepSORT包括以下几个步骤:
-
目标检测:使用目标检测算法(如YOLO、Faster R-CNN等)从视频帧中检测出所有目标,并生成对应的边界框。
-
目标特征提取:使用CNN等深度学习模型从每个目标的边界框中提取出特征向量,并将其输入到RNN中进行序列建模。
-
目标匹配:使用匈牙利算法计算两帧之间的目标匹配关系,并根据目标特征向量的相似度和卡尔曼滤波预测结果来确定匹配结果。
-
身份管理:为每个跟踪目标分配一个唯一的ID,并在跟踪过程中将其与先前的跟踪结果进行比较,以确保ID的唯一性和一致性。
DeepSORT通过融合深度学习和传统跟踪技术,可以实现高效、准确和稳定的多目标跟踪和身份识别,因此在实际应用中具有广泛的应用前景。
多目标追踪的主要步骤
- 获取原始视频帧;
- 利用目标检测器对视频帧中的目标进行检测;
- 将检测到的目标的框中的特征提取出来,该特征包括表观特征(方便特征对比避免ID switch)和运动特征(运动特征方便卡尔曼滤波对其进行预测);
- 计算前后两帧目标之前的匹配程度(利用匈牙利算法和级联匹配),为每个追踪到的目标分配ID。
Sort 算法原理
- 卡尔曼滤波算法
该算法的主要作用就是当前的一系列运动变量去预测下一时刻的运动变量,但是第一次的检测结果用来初始化卡尔曼滤波的运动变量。
- 匈牙利算法
简单来讲就是解决分配问题,就是把一群检测框和卡尔曼预测的框做分配,让卡尔曼预测的框找到和自己最匹配的检测框,达到追踪的效果。
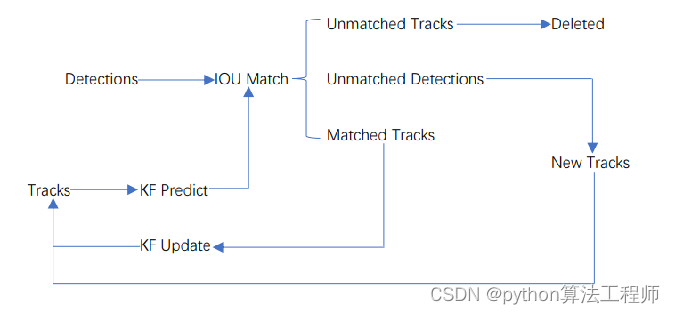
Detections是目标检测框
Tracks是轨迹信息(外观特征和运动信息)
什么是重识别(ReID)?
重识别(ReID)是一种计算机视觉任务,旨在识别不同位置、时间或摄像机中的同一对象。它通常应用于视频监控、人员管理和公共安全等领域。
在ReID中,模型需要从给定的图像或视频序列中提取出人物的特征向量,并将其与一个已知的人物数据库进行匹配,以确定该人物在数据库中的身份。与传统的人脸识别不同,ReID需要处理全身图像,因此需要考虑姿态、服装、光照等因素。
ReID通常包括以下几个步骤:
-
特征提取:使用深度学习模型(如ResNet、DenseNet等)从图像中提取出人物的特征向量。
-
特征匹配:使用一些度量方法(如欧氏距离、余弦相似度等)计算两个特征向量之间的相似度,并将其与一个已知的数据库进行比较。
-
单目标跟踪(可选):使用目标跟踪算法(如卡尔曼滤波、匈牙利算法等)跟踪单个目标,并在多个摄像机之间进行跨摄像机重识别。
-
多目标跟踪(可选):将单目标跟踪扩展到多个目标,以处理多人情况。
近年来,随着深度学习的发展,ReID已经取得了显著的进展,并在许多实际应用中得到了广泛应用。
上一帧
 当前帧
当前帧

什么是身份变换(IDswitch)?
在目标追踪中引入身份变换(IDswitch)是一种常见的技术,它可以实现目标的身份变换,从而应对目标在追踪过程中的遮挡、离开视野等问题。身份变换可以用于多种目标追踪场景,例如视频监控、智能交通和机器人导航等领域。
身份变换的实现通常包括以下几个步骤:
-
目标检测:使用目标检测算法(如YOLO、Faster R-CNN等)从视频帧中检测出目标,并生成对应的边界框。
-
目标跟踪:使用目标跟踪算法(如KCF、MOSSE等)追踪目标,并根据目标位置和运动状态等信息对目标进行预测。
-
身份变换:根据目标特征表示(如人脸特征、颜色特征等),将目标的身份进行变换。这通常需要使用图像合成技术(如身份变换、图像融合等)将目标的特征表示与目标图像进行融合,从而实现身份变换的效果。
-
身份管理:为每个目标分配一个唯一的ID,并在跟踪过程中将其与先前的跟踪结果进行比较,以确保ID的唯一性和一致性。
需要注意的是,身份变换技术可能存在一些误差和局限性,例如人脸姿态变化、光照变化和遮挡等问题。因
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1119
1119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









